
写在前面:
本篇文章是对个人学习的笔记记录,仅用于学习使用。
中间可能会存在错别字、描述不准确的地方,欢迎各位网友指正。
Linux基本命令
Linux启动过程

Linux手册
man -ls Linux提供的帮助手册,按下q退出手册which查找命令
which 去PATH路径中,找到命令的绝对路径,并输出。
[admin@server ~]$ which pwd
/usr/bin/pwdclear清屏命令
clear 清屏
Ctrl+lshutdown关机命令
shutdown 关机命令reboot重启系统
reboot 重启Linux系统history查看命令历史记录
history 显示今天敲了哪些命令,默认300条。
history -c 清空历史命令记录捋一捋
1.你登录了一个机器,你的操作,都会被history记录,临时存储在哎内存中
2.退出登录后,记录被写入到文件,永久存储,下一次登录 ,系统会去加载家目录中的资料,也包括 ~/.bash_hisotry
彻底清空的动作
> .bash_history
1.你登录了某机器,做了某操作,不想被记录, 直接hisotry -c ,清空你当前登录后,执行的所有操作
2. 把当前的历史记录,写入到文件中,强制写入(退出登录)
history -w # 把当前的历史记录,内存中的数据,写入到文件里
同时敲下面这两条命令
history -c
history -w
下次再登录,啥也看不到了!!执行上一条命令
!+[字母] 执行最近以[字母]开头的命令。
!+[number] 执行历史命令列表的第几条命令。 Ctrl+r 进入搜索命令行使用过得历史命令记录模式Ctrl+g 从执行Ctrl+r的搜索命令模式中退出Linux定时计划任务crontab
在线工具
什么是计划任务:后台运行,到了预定的时间就会自动执行的任务,前提是:事先手动将计划任务设定好。
周期性任务执行
清空/tmp目录下的内容
mysql数据库备份
redis数据备份
这就用到了crond服务。
计划任务的作用
操作系统不可能24 小时都有人在操作,有些时候想在指定的时间点去执行任务(例如:每天凌晨2 点去重新启动Apache),此时不可能真有人每天夜里2点去执行命令,这就可以交给计划任务程序去执行操作了。
查看计划任务
语法:
# crontab [选项]常用选项:
-l: list,列出指定用户的计划任务列表
-e : edit,执行文字编辑器来设定时程表,内定的文字编辑器是VI, 如果你想用别的文字编辑器,则请先设定VISUAL环境变数来指定使用那个文字编辑器(比如说setenv VISUAL joe)
-u : user,指定的用户名,如果不指定,则表示当前用户
-r : remove,删除指定用户的计划任务列表
示例代码:列出当前用户的计划任务列表
[root@server ~]# crontab -l
no crontab for root默认应该是没有设置定时任务的。
命令功能
通过crontab命令,我们可以在固定的间隔时间执行指定的系统指令或shell script脚本。时间间隔的单位可以是分钟、小时、日、月、周及以上的任意组合。这个命令非常设合周期性的日志分析或数据备份等工作。
编辑计划任务(重点)
进入计划任务编辑文件
[root@server ~]# crontab -e打开计划任务编辑文件后,可以在此文件中编写我们自定义的计划任务
计划任务的规则语法格式,以行为单位,一行则为一个计划:
分 时 日月周 需要执行的命令
例如:0 0* * * reboot ,代表每天0时0分执行reboot指令。
语法
[root@server ~]# cat /etc/crontab
SHELL=/bin/bash #定时任务,是帮我们去执行shell语句的,因此必须得有bash解释器,以及系统上有很多的解释器类型/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin #注意:crontab自己定义了PATH变量,写在定时任务里面的命令,必须是绝对路径,不如容易出错
MAILTO=root #定时任务执行后,会给系统用户发一个邮件
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59) #分钟
# | .------------- hour (0 - 23) #小时
# | | .---------- day of month (1 - 31) #日
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ... #月
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat #周
# | | | | |
# * * * * * user-name command to be executed
分 时 日 月 周 用户名 需要执行的命令
* * * * * 是命令的绝对路径取值范围(常识):
分 : 8 ~ 59
时 : 8 ~ 23
日 : 1 ~ 31
月 : 1 ~ 12
周 : 0 ~ 7,0和7表示星期天
#注意:日期和星期几是不能同时写得。
四个符号:
* : 表示取值范围中的每一个数字
- : 做连续区间表达式的,要想表示1~7,则可以写成: 1 - 7
/ : 表示每多少个,例如:想每10分钟一次,则可以在分的位置写: */10
, : 表示多个取值,比如想在1点,2点6点执行,则可以在时的位置写: 1 , 2 , 6并且在定时任务里,命令,请写上绝对路径。
通过whereis命令搜索绝对路径
如:
[root@server ~]# whereis systemctl
systemctl: /usr/bin/systemctl /usr/share/man/man1/systemctl.1.gz实例
* * * * *
分 时 日 月 周 命令绝对路径
[root@server ~]# crontab -e问题1:每月1、10、22 日的4:45 重启network 服务
45 4 1,10,20 * * /user/bin/systemctl restart network问题2:每周六、周日的下午1:10 重启network 服务
10 1 * * 6,7 /user/bin/systemctl restart network问题3:每天18:00 至23:00 之间每隔30 分钟重启network 服务
*/30 18-23 * * * /user/bin/systemctl restart network问题4:每隔两天的上午8点到11点的第3和第15分钟执行一次重启
3,15 8-11 */2 * * /usr/sbin/reboot问题5 :每天凌晨整点重启nginx服务。
0 0 * * * /user/bin/systemctl restart nginx问题6:每周4的凌晨2点15分执行命令
15 2 * * 4 command问题7:工作日的工作时间内的每小时整点执行my.sh脚本。
0 9-18 * * 1-5 /usr/bin/bash my.sh问题8:如果定时任务的时间,没法整除,定时任务就没有意义了,得通过其他手段,自主控制定时任务频率。
问题9:crontab提供最小分钟级别的任务,想完成秒级别的任务,得通过编程语言自己写。
问题10:每1分钟向文件里写入一句话"超哥666",且实时监测文件内容变化。
* * * * * /usr/bin/echo "超哥666" >> /tmp/666.txt
1.写入计划任务
[root@server ~]# crontab -e
2.写入语句
[root@server ~]# crontab -e
no crontabfor root-using an empty one
crontab: installing new crontab
[root@server ~]# crontab -l
* * * * * /usr/bin/echo "超哥666" >> /tmp/666.txt
3.等待定时任务执行
[root@server ~]# tail -F /tmp/666.txt
tail: cannot open '/tmp/666.txt’ for reading: No such file or directory
tail:“/tmp/666.txt"has appeared; following end of new file
超哥666
超哥666问题11:每天凌晨2点30,执行ntpdate命令同步 ntp.aliyun.com,并且sys同步到硬件时钟,且不输出任 何信息。
30 2 * * * /usr/sbin/ntpdate -u ntp.aliyun.com &> /dev/null
1.ntpdate同步成功后,会生成同步的结果日志
[root@server ~]# ntpdate u ntp.aliyun.com
可以重定向标准输出结果到照洞文件,
ntpdate -u ntp.aliyun.com &> /dev/nu1l
2.编写定时任务语句
30 2 * * * /usr/sbin/ntpdate untp.aliyun,com &> /dev/null;/usr/sbin/hwclock -w &> /dev/null问题12:1.每天的凌晨3点12分 备份整个/mysql_data目录到/opt/mysql_back.tgz,并且要求定时任务无信息输出。
备份整个文件夹,成为一个压缩文件
打包,且压缩文件夹,生成压缩文件
建议,这样去备份
方法一:
[root@server ~]# vim /scripts/mysql_bak.sh
cd /
tar -zcf /opt/mysql_back.tgz ./mysql_data
这样就是俩语句了得写入脚本文件中,再去执行文件
定时任务,执行这个脚本即可
[root@server ~]# 12 3 * * * /bin/bash /scripts/mysql_bak.sh
方法2
[root@server ~]# tar -zcf /opt/mysql_back.tgz /mysql_data
建议使用方法一问题13:由于jerry01业务需要创建定时任务,以root用户给jerry01创建如下定时任务。
* * * * * echo 'i am jerry01 , how are you' >> /tmp/jerry01.log
[root@server ~]# crontab -u jerry01 -e
crontab:installing new crontab
[root@server ~]# crontab-u jerry01 -l #查看定时任务
*****/usr/bin/echo 'i am jerry0l ,how are you' >> /tmp/jerry01.log扩展(黑白名单)
① crontab 权限问题
crontab是任何用户都可以创建的计划任务,但是超级管理员可以通过配置来设置某些用户不允许设置计划任务。 黑名单配置文件位于:/etc/cron.deny 里面写用户名,一行只能写一个
#禁止yuchao01用户设置定时任务
[root@yuchao-linux01 ~]# vim /etc/cron.deny
[root@yuchao-linux01 ~]#
[root@yuchao-linux01 ~]# cat /etc/cron.deny
yuchao81
#切换yuchao01用户登录
[yuchao01@yuchao-linux01 ~]$ crontab -e
You(yuchao01)are not allowed to use this program(crontab)
See crontab(1)for more information白名单还有一个配置文件,/etc/cron.allow(本身不存在,自己创建) 注意:白名单优先级高于黑名单,如果一个用户同时存在两个名单文件中,则会被默认允许创建计划任务。
#添加白名单后,会立即更新权限
[rootyuchao-linux01 ~]#echo'yuchao01"> /etc/cron.allow
# yuchao01就可以写入了
[yuchao01@yuchao-linux01 ~]$ crontab -e②查看计划任务文件保存路径
问题:计划任务文件具体保存在哪里呢? 答:/var/spoo1/cron/用户名文件中 ,如果使用root用户编辑计划任务,则用户文件名为root。 有图可见,该目录存放用户的定时任务信息,
③查看计划任务日志
问题:在实际应用中,我们如何查看定时任务运行情况? 答:通过计划任务日志,日志文件位于/var/log/cron
④定时任务,crontab会在系统中,生成大量的邮件日志,会占用磁盘,因此我们都会关闭邮件服务即可。
[root@server ~]# find / -type f -name 'post*.service'
/usr/lib/systemd/system/postfix.service
systemctl服务管理命令
[root@server ~]# systemctl list-units |grep post
postfix.service
loaded active running Postfix Mail Transport Agent
[root@server ~]# systemctl status postfix
[root@server ~]# systemctl stop postfix
[root@server ~]# systemctl is-enabled postfix
[root@server ~]# systemctl disable postfixDiff命令对比两个文件
语法
diff [-abBcdefHilnNpPqrstTuvwy][-<行数>][-C <行数>][-D <巨集名称>][-I <字符或字符串>][-S <文件>][-W <宽度>][-x <文件或目录>][-X <文件>][--help][--left-column][--suppress-common-line][文件或目录1][文件或目录2]参数
-<行数> 指定要显示多少行的文本。此参数必须与-c或-u参数一并使用。
-a或--text diff预设只会逐行比较文本文件。
-b或--ignore-space-change 不检查空格字符的不同。
-B或--ignore-blank-lines 不检查空白行。
-c 显示全部内文,并标出不同之处。
-C<行数>或--context<行数> 与执行"-c-<行数>"指令相同。
-d或--minimal 使用不同的演算法,以较小的单位来做比较。
-D<巨集名称>或ifdef<巨集名称> 此参数的输出格式可用于前置处理器巨集。
-e或--ed 此参数的输出格式可用于ed的script文件。
-f或-forward-ed 输出的格式类似ed的script文件,但按照原来文件的顺序来显示不同处。
-H或--speed-large-files 比较大文件时,可加快速度。
-I<字符或字符串>或--ignore-matching-lines<字符或字符串> 若两个文件在某几行有所不同,而这几行同时都包含了选项中指定的字符或字符串,则不显示这两个文件的差异。
-i或--ignore-case 不检查大小写的不同。
-l或--paginate 将结果交由pr程序来分页。
-n或--rcs 将比较结果以RCS的格式来显示。
-N或--new-file 在比较目录时,若文件A仅出现在某个目录中,预设会显示:
Only in目录:文件A若使用-N参数,则diff会将文件A与一个空白的文件比较。
-p 若比较的文件为C语言的程序码文件时,显示差异所在的函数名称。
-P或--unidirectional-new-file 与-N类似,但只有当第二个目录包含了一个第一个目录所没有的文件时,才会将这个文件与空白的文件做比较。
-q或--brief 仅显示有无差异,不显示详细的信息。
-r或--recursive 比较子目录中的文件。
-s或--report-identical-files 若没有发现任何差异,仍然显示信息。
-S<文件>或--starting-file<文件> 在比较目录时,从指定的文件开始比较。
-t或--expand-tabs 在输出时,将tab字符展开。
-T或--initial-tab 在每行前面加上tab字符以便对齐。
-u,-U<列数>或--unified=<列数> 以合并的方式来显示文件内容的不同。
-v或--version 显示版本信息。
-w或--ignore-all-space 忽略全部的空格字符。
-W<宽度>或--width<宽度> 在使用-y参数时,指定栏宽。
-x<文件名或目录>或--exclude<文件名或目录> 不比较选项中所指定的文件或目录。
-X<文件>或--exclude-from<文件> 您可以将文件或目录类型存成文本文件,然后在=<文件>中指定此文本文件。
-y或--side-by-side 以并列的方式显示文件的异同之处。
--help 显示帮助。
--left-column 在使用-y参数时,若两个文件某一行内容相同,则仅在左侧的栏位显示该行内容。
--suppress-common-lines 在使用-y参数时,仅显示不同之处。实例1:比较两个文件
[root@localhost test3]# diff log2014.log log2013.log
3c3
< 2014-03
---
> 2013-03
8c8
< 2013-07
---
> 2013-08
11,12d10
< 2013-11
< 2013-12上面的"3c3"和"8c8"表示log2014.log和log20143log文件在3行和第8行内容有所不同;"11,12d10"表示第一个文件比第二个文件多了第11和12行。
实例2:并排格式输出
[root@localhost test3]# diff log2014.log log2013.log -y -W 50
2013-01 2013-01
2013-02 2013-02
2014-03 | 2013-03
2013-04 2013-04
2013-05 2013-05
2013-06 2013-06
2013-07 2013-07
2013-07 | 2013-08
2013-09 2013-09
2013-10 2013-10
2013-11 <
2013-12 <
[root@localhost test3]# diff log2013.log log2014.log -y -W 50
2013-01 2013-01
2013-02 2013-02
2013-03 | 2014-03
2013-04 2013-04
2013-05 2013-05
2013-06 2013-06
2013-07 2013-07
2013-08 | 2013-07
2013-09 2013-09
2013-10 2013-10
> 2013-11
> 2013-12说明:
"|"表示前后2个文件内容有不同
"<"表示后面文件比前面文件少了1行内容
">"表示后面文件比前面文件多了1行内容
文件目录篇
Linux目录树状图
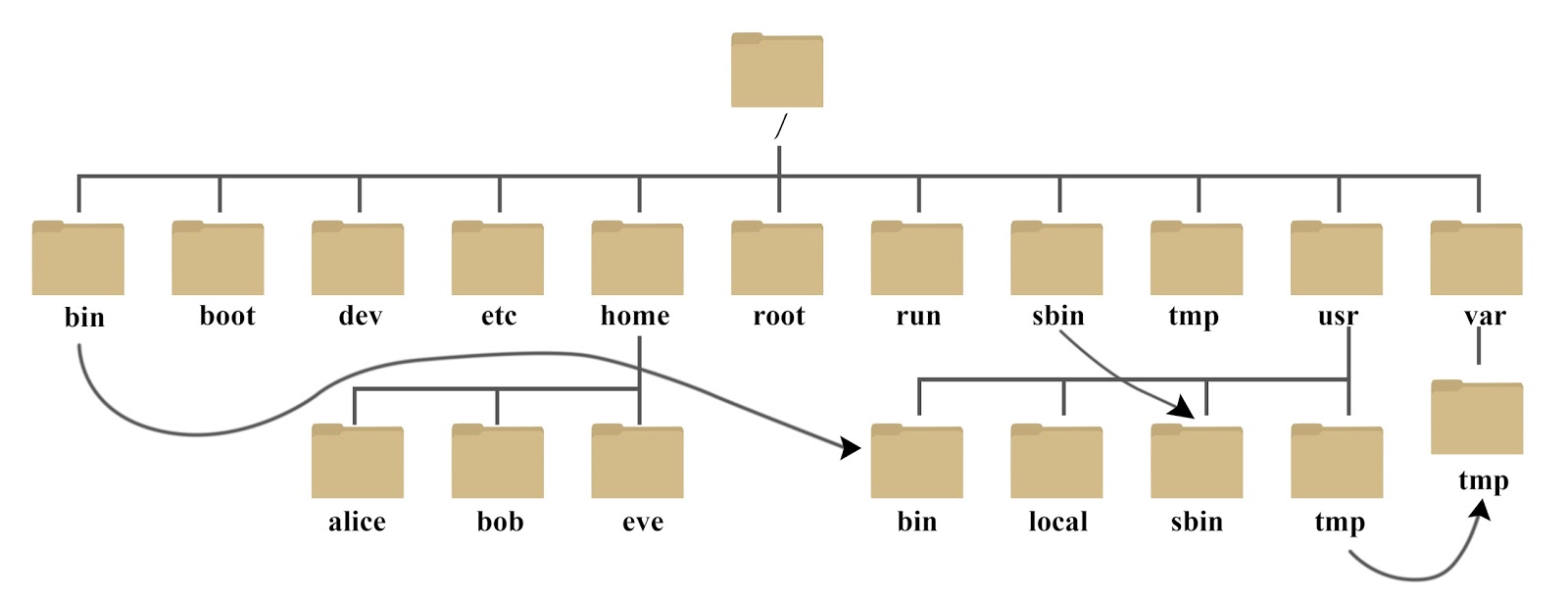
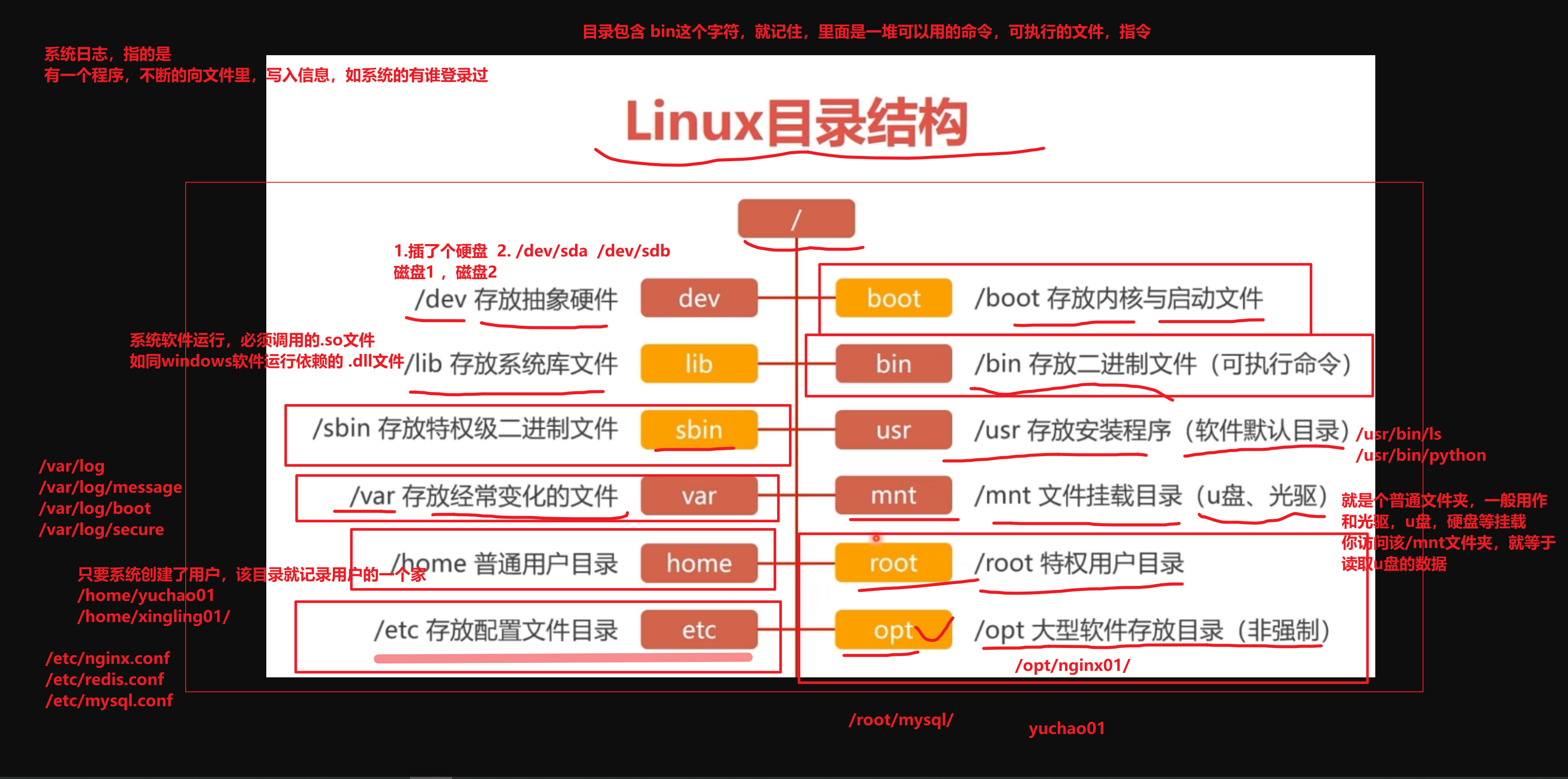
常见目录(需记忆)
以下是对这些目录的解释:
/bin: bin 是 Binaries (二进制文件) 的缩写, 这个目录存放着最经常使用的命令。
/boot: 这里存放的是启动 Linux 时使用的一些核心文件,包括一些连接文件以及镜像文件。
/dev : dev 是 Device(设备) 的缩写, 该目录下存放的是 Linux 的外部设备,在 Linux 中访问设备的方式和访问文件的方式是相同的。
/etc: etc 是 Etcetera(等等) 的缩写,这个目录用来存放所有的系统管理所需要的配置文件和子目录。

/home: 用户的主目录,在 Linux 中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的,如上图中的 alice、bob 和 eve。
/lib: lib 是 Library(库) 的缩写这个目录里存放着系统最基本的动态连接共享库,其作用类似于 Windows 里的 DLL 文件。几乎所有的应用程序都需要用到这些共享库。
/lost+found: 这个目录一般情况下是空的,当系统非法关机后,这里就存放了一些文件。
/media: linux 系统会自动识别一些设备,例如U盘、光驱等等,当识别后,Linux 会把识别的设备挂载到这个目录下。
/mnt: 系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将光驱挂载在 /mnt/ 上,然后进入该目录就可以查看光驱里的内容了。
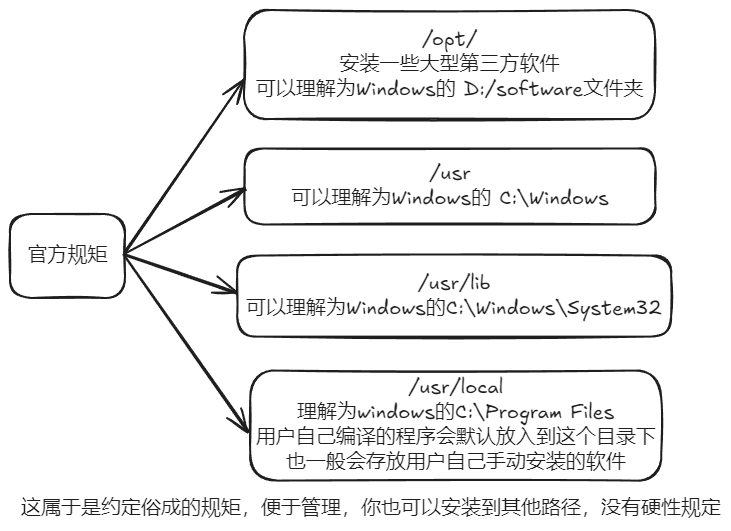
/opt: opt 是 optional(可选) 的缩写,这是给主机额外安装软件所摆放的目录。比如你安装一个ORACLE数据库则就可以放到这个目录下。默认是空的。
/proc: proc 是 Processes(进程) 的缩写,/proc 是一种伪文件系统(也即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件,这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。 这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件,比如可以通过下面的命令来屏蔽主机的ping命令,使别人无法ping你的机器:
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all/root: 该目录为系统管理员,也称作超级权限者的用户主目录。
/sbin: s 就是 Super User 的意思,是 Superuser Binaries (超级用户的二进制文件) 的缩写,这里存放的是系统管理员使用的系统管理程序。
/selinux: 这个目录是 Redhat/CentOS 所特有的目录,Selinux 是一个安全机制,类似于 windows 的防火墙,但是这套机制比较复杂,这个目录就是存放selinux相关的文件的。
/srv: 该目录存放一些服务启动之后需要提取的数据。
/sys:
这是 Linux2.6 内核的一个很大的变化。该目录下安装了 2.6 内核中新出现的一个文件系统 sysfs 。
sysfs 文件系统集成了下面3种文件系统的信息:针对进程信息的 proc 文件系统、针对设备的 devfs 文件系统以及针对伪终端的 devpts 文件系统。
该文件系统是内核设备树的一个直观反映。
当一个内核对象被创建的时候,对应的文件和目录也在内核对象子系统中被创建。
/tmp: tmp 是 temporary(临时) 的缩写这个目录是用来存放一些临时文件的。
/usr: usr 是 unix shared resources(共享资源) 的缩写,这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似于 windows 下的 program files 目录。
/usr/bin: 系统用户使用的应用程序。
/usr/sbin: 超级用户使用的比较高级的管理程序和系统守护程序。
/usr/src: 内核源代码默认的放置目录。
/usr/local/:
用户自己编译的程序会默认放在该目录下。
/var: var 是 variable(变量) 的缩写,这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。
/var/cache/:
Linux缓存目录。
/run: 是一个临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。如果你的系统上有 /var/run 目录,应该让它指向 run。
在 Linux 系统中,有几个目录是比较重要的,平时需要注意不要误删除或者随意更改内部文件。
/etc: 上边也提到了,这个是系统中的配置文件,如果你更改了该目录下的某个文件可能会导致系统不能启动。
/bin, /sbin, /usr/bin, /usr/sbin: 这是系统预设的执行文件的放置目录,比如 ls 就是在 /bin/ls 目录下的。
值得提出的是 /bin、/usr/bin 是给系统用户使用的指令(除 root 外的通用用户),而/sbin, /usr/sbin 则是给 root 使用的指令。
/var: 这是一个非常重要的目录,系统上跑了很多程序,那么每个程序都会有相应的日志产生,而这些日志就被记录到这个目录下,具体在 /var/log 目录下,另外 mail 的预设放置也是在这里。
特殊目录
. 当前工作目录
.. 上一级的目录
.filename 以.开头的文件,表示隐藏文件
- 上一次工作目录
~ 当前登陆用户的家目录
cd 在目录之间移动
[root@localhost ~]# cd /etc/yum
[root@localhost yum]#
[root@localhost yum]# cd /~ #或者cd
[root@localhost ~]
cd - 短横线表示上一次的工作目录
[root@localhost yum]# cd -
/root
[root@localhost ~]# cd -
/etc/yum
[root@localhost yum]#
作业:假如我当前在/root/desktop/apple/xiaomi目录,我要进入到/desktop/huawei目录,怎么实现?
[root@root ~]# cd desktop/
[root@root desktop]# ls
apple huawei
方法一:绝对路径
[root@root xiaomi]# cd /root/desktop/huawei/
[root@root huawei]#
方法二:相对路径
[root@root xiaomi]# pwd
/root/desktop/apple/xiaomi/redmi
[root@root xiaomi]# cd ../../huawei
[root@root huawei]# tree命令——显示目录结构
tree命令使用示例
查看命令版本
[root@root ~]# tree --version
tree v1.7.0 (c) 1996 - 2014 by Steve Baker, Thomas Moore, Francesc Rocher, Florian Sesser, Kyosuke Tokoro查看目录/opt目录结构
[root@root ~]# tree -N /opt/
/opt/
├── rh
├── 璃月
│ └── 岩神
│ └── 钟离.png
├── 稻妻
│ └── 雷神
│ └── 雷电将军.png
├── 蒙德
│ └── 风神
│ └── 巴巴托斯.png
└── 须弥
└── 草神
└── 纳西妲.png
9 directories, 4 files使用语法
tree [选项] [目录]
tree [选项] [目录] -o filename参数说明
展示参数说明
文件参数说明
排序参数说明
图形选项参数说明
XML/HTML选项参数说明
特殊文件
/dev/null
/dev/null代表linux的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”。比较常见的用法是把不需要的输出重定向到这个文件。
ping yuchaoit.cn > /dev/null &/dev/zero
零”设备,可以无限的提供空字符(0x00,ASCII代码NUL)。常用来生成一个特定大小的文件。
dd if=/dev/zero of=test.log bs=1M count=50/dev/random和/dev/urandom
/dev/random和/dev/urandom是Linux系统中提供的随机伪设备,这两个设备的任务,是提供永不为空的随机字节数据流。很多解密程序与安全应用程序(如SSH Keys,SSL Keys等)需要它们提供的随机数据流。危险玩法,比如实现类似于shred粉碎文件的作用
dd bs=1M count=30 if=/dev/urandom of=./t1
也可以销毁硬盘分区数据
dd if=/dev/urandom of=/dev/sda5实例
如何生成一个5G大小的文件,提示(dd命令)
dd if=/dev/zero of=/opt/5G.txt bs=100M count=50用户管理篇
Linux登陆与退出登陆
远程登录方式Win/Linux
Xshell/Windows
ssh [主机名]@[要登陆的主机IP的地址][:端口号 默认:22]
如:[C:\~]$ssh admin@10.0.0.129:22Linux终端
ssh -p [端口号] [主机名]@[要登陆的主机IP的地址]
如:[admin@localhost ~]$ssh -p 20 admin@10.0.0.130远程登录ubuntu
ubuntu乌班图下,都是普通用户操作,必须加sudo
1.默认拿到一个新机器,可能没开启ssh服务,无法远程连接
2.或许需要升级下软件仓库
sudo apt update
3.需要安装ssh服务
sudo apt install openssh-server
#查询安装好ssh没有
#dpkg -l | grep ssh
4.启动ssh服务,即可远程连接
sudo service sshd start
5.查看该端口
sudo ss -tunlp|grep 22exit/logout退出登陆
exit 退出登陆
logout 退出该会话登陆id/whomai命令,查看用户信息
验证该用户名是否存在
id [用户名]
[admin@localhost ~]$ id root
uid=0(root) gid=0(root) groups=0(root)
[admin@localhost ~]$ id admin
uid=1000(admin) gid=1000(admin) groups=1000(admin),10(wheel)
[admin@localhost ~]$ id admin01
id: admin01: no such user查看系统中的当前用户信息
id
[root@localhost ~]# id
uid=0(root) gid=0(root) groups=0(root)
whoami
[root@localhost ~]# whoami
rootlast显示登录记录
last -5 显示最近的5条登录记录
lastlog 显示关于用户的登录记录useradd创建新用户
用户与用户组在Linux中的记录
Linux将用户账号、密码等相关信息分别存储在四个文件夹下:
/etc/passwd 管理用户UID/GID重要参数
/etc/shadow 管理用户密码
/etc/group 管理用户组相关信息
/etc/gshadow 管理用户组管理员相关信息(给组设置密码)
自动创建用户的家目录,默认在/home下,与用户名同名,如/home/root/etc/passwd存储格式

其中,
密码项显示"x” 是出于安全考虑, Linux 将密码信息移到/etc/shadow 进行存储;
每一个用户都有一一个 UID、GID,对应的含义就是UserID、GrouplD, UID会映射到/etc/shadow以获得密码信息,GID会映射到/etc/group以获取用户的用户组信息。
/etc/shadow存储格式

其中,
第二列表示密码加密后的字符串。
/etc/passwd通过UID, 在该文件中找出对应UID 的用户,并提取对应密码用于登陆验证。
/etc/group存储格式

其中,用户组密码通常是为了设置用户组管理员存在的,其信息也移动到/etc/gshadow中;/etc/passwd通过GID,在该文件中找到对应的用户组,并提取用户组相关信息;
另外,由于一一个用户可以在多个用户组中,因此就有一一个初始用户组的有效用户组的概念。
所谓的初始用户组,就是用户所记录的GID, 是在创建用户时生成或指定的用户组;所谓的有效用户组,就是利用命令groups 查看并输出的首个用户组,即有效用户组;用户在登录的时候,以初始用户组身份工作,用户可以用newgrp命令实现有效用户组的切换。
/etc/gshadow存储格式

般用户组不使用用户组管理员,相应地也就不需要设置密码。
Linux用户账号管理
在此部分,会分别介绍新增、修改、删除用户及用户组,用户身份切换,查询用户信息等多种用户账号的管理操作。
命令行格式
Linux命令行格式: command [-options] [parameter]
command:命令名,相应功能的英文单词或单词的缩写
[-options]:选项,可用来对命令进行控制,也可以省略
[parameter]:传给命令的参数,可以是0个、1个或多个useradd新增、修改、删除用户
可选参数
-c<备注> 加上备注文字。备注文字会保存在passwd的备注栏位中。
-d<登入目录> 指定用户登入时的起始目录。
-D 变更预设值.
-e<有效期限> 指定帐号的有效期限。
-f<缓冲天数> 指定在密码过期后多少天即关闭该帐号。
-g<群组> 指定用户所属的群组。
-G<群组> 指定用户所属的附加群组。
-m 制定用户的登入目录。
-M 不要自动建立用户的登入目录。
-n 取消建立以用户名称为名的群组.
-r 建立系统帐号。
-s<shell> 指定用户登入后所使用的shell。
-u<uid> 指定用户ID。
新增用户 useradd
useradd [-options] [username]在使用useradd 时,可以通过不同的参数options, 达到不同的创建用户的效果,例如指定UID、指定初始用户组、指定次要用户组、指定主文件夹等。具体参数请利用man命令进行查询。useradd在不指定任何参数的时候,会参考两个主要配置文件的默认值来新增用户。
[admin@localhost ~]$ cat /etc/default/useradd
# useradd defaults file
GROUP=100 #默认的用户组
HOME=/home #默认的主文件夹所在目录
INACTIVE=-1 #密码失效日
EXPIRE= #账号失效日
SHELL=/bin/bash #默认shell
SKEL=/etc/skel #用户主文件夹的内容数据参考目录
CREATE_MAIL_SPOOL=yes #是否创建邮件信箱[admin@localhost ~]$ cat /etc/login.defs
PASS_MAX_DAYS 99999 #多久必须重设密码(天)
PASS_MIN_DAYS 0 #距上次修改密码多久不可重设密码(天)
PASS_MIN_LEN 5 #密码最短的字符长度
PASS_WARN_AGE 7 #距离多少天过期会报警提示
UID_MIN 1000 #创建用户的UID默认最小值
UID_MAX 60000 #创建用户的UID上限
GID_MIN 1000 #创建用户的GID默认最小值
GID_MAX 60000 #创建用户的GID上限
CREATE_HOME yes #创建家目录
USERGROUPS_ENAB yes #删除用户时是否删除初始用户组(组内不再有其他成员)useradd通过参考这两个文件的配置信息,赋予创建的用户默认值。另外,useradd默认会在/home下创建用户同名的主目录;同时,useradd创建的用户还没有设置登录密码,需要利用passwd进行密码设置。
设置密码 passwd
利用passwd命令,可以设置或重置密码
passwd [-options] [username]与useradd相同,不同的options参数能够满足不同的密码设置需求,包括失效时间、密码改动时间等。
修改用户
chage命令用来修改与用户密码相关的过期信息,如密码失效日、密码最短保留天数、失效前警告天数等。
chage [-options] [username]当然,passwd也可以做相应的修改.
usermod
用来修改用户信息
usermod [-options] [username]
将用户yang加入到devops组里
usermod -G devops yangusermod通过选用不同的options 参数,可以修改存储在/etc/passwd内的用户信息。
删除用户
userdel命令用来删除用户的相关的所有数据。
userdel [-options] [username]
options:
-r:同时删除用户的家目录groupad新增、修改、删除用户组
可选参数
-g 设置id号,默认从1000开始,1~999是系统预留的组。
groupadd -g 1001 yanghonqiang
-n 设置组名新增用户组
使用方式与useradd 非常相似,与useradd 不同的是,新建的用户组通常不需要设置密码。
groupadd [-options] [username]修改用户组
groupmod命令用来修改group相关的参数,不过通常不建议修改GID
groupmod [-options] [username]删除用户组
groupdel删除用户组之前,必须保证没有任何-个用户使用这个用户组作为初始用户组,否则无法删除。
groupdel [options] [groupname]su命令,用户名切换,sudo -i用户切换
su [-options] [系统中存在的用户名]
#短横线"-"表示切换用户且加载该用户的环境变量PATH,且进入该用户的家目录。
#不加短横线,为不完全切换,不加载该目标用户的环境变量。
su - 切换到root用户命令等同于 sudo -i命令
[admin@localhost ~]$ su - root
Password: #root
Last login: Fri Jul 12 16:25:59 CST 2024 from 10.0.0.1 on pts/1
Last failed login: Tue Jul 16 20:28:27 CST 2024 on pts/1
There was 1 failed login attempt since the last successful login.
[root@localhost ~]# su - admin
Last login: Tue Jul 16 20:30:23 CST 2024 on pts/1
[admin@localhost ~]$
options:
-: 代表使用login-shell 的变量文件读取方式来登录系统.
-l: 同上.
-m: 表示使用当前的环境设置,而不读取新用户的配置文件.
-C: 仅进行一-次命令,执行完后直接回到目前的用户身份.visudo

who/w查看当前登陆系统终端
[admin@root ~]$ who
admin :0 2024-07-20 19:06 (:0)
admin pts/0 2024-07-20 19:06 (:0) #VMware
admin pts/1 2024-07-20 19:35 (10.0.0.1) #Xshell 7 通过物理机的以太网卡VMnet8进来的。Windows->Linux
[admin@root ~]$ w
19:39:35 up 34 min, 3 users, load average: 0.04, 0.03, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
admin :0 :0 19:06 ?xdm? 39.14s 0.12s /usr/libexec/gnome-session-binary
admin pts/0 :0 19:06 1:59 0.26s 1.89s /usr/libexec/gnome-terminal-server
admin pts/1 10.0.0.1 19:35 7.00s 0.03s 0.01s w主要涉及用户信息查询的命令
id <user> #展示指定user的UID、GID、用户组信息等,默认为当前有效用户
who am i #等同于who -m,仅显示当前登录用户相关信息
whoami #仅显示当前有 效用户的用户名
W #展示当前正在登录主机的用户信息及正在执行的操作
who #展示当前正在登录主机的用户信息
last <user> #展示指定用户的历史登录信息,默认为当前有效用户
lastlog -u <user> #展示指定用户最近的一次登录信息,默认显示所有用户hostname修改主机名
主机名
[root@localhost ~]# hostname #查看当前主机名
localhost.localdomain
[root@localhost ~]# hostname linux01 #临时修改主机名
[root@localhost ~]# hostname
linux01
[root@localhost ~]# hostnamectl set-hostname [主机名] #修改主机名
[root@localhost ~]# vi /etc/hostname #修改主机名 永久
[root@localhost ~]# cat /etc/hostname
linux01
#1,退出登陆实现修改
[root@linux01 ~]# exit
logout
[admin@localhost ~]$ su - root
Password:
Last login: Tue Jul 16 21:22:08 CST 2024 on pts/1
[root@linux ~]#
#2,重新加载该系统的环境变量(建议使用这个)
[root@localhost ~]# bash
[root@linux01 ~]#
#3,--reboot 重启生效(生产环境中慎用)
[root@linux01 ~]# uname查看内核信息
查看内核信息 name
[admin@localhost ~]$ uname
Linux
[admin@localhost ~]$ uname -a
Linux localhost.localdomain 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:24 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
uname常见命令参数
-a, --all print all information, in the following order,
except omit -p and -i if unknown://显示全部信息
-s, --kernel-name print the kernel name // 显示内核名称
-n, --nodename print the network node hostname //显示主机名
-r, --kernel-release print the kernel release //显示内核的发行版本
-v, --kernel-version print the kernel version //显示内核版本
-m, --machine print the machine hardware name //显示硬件名
-p, --processor print the processor type or "unknown" //显示处理器名称
-i, --hardware-platform print the hardware platform or "unknown" //显示硬件平台类型
-o, --operating-system print the operating system //显示操作系统名文件管理篇
文件命名规则
除了字符/之外,所有的字符都可以使用,但要注意,在目录名或文件名中,不建议使用某些特殊字符例如:< > ? 、 *等。如果一个文件名包含了特殊字符,例如空格,那么在访问这个文件时需要使用引号``将文件名括起来。
建议文件命名规则
由于Linux严格区分大小写,因此建议使用小写字母命名。
如果必须对文件进行分割,建议使用_来进行分割,如:
manba_out.txt创建和删除文件夹
mkdir命令
mkdir 创建文件夹(只有创建文件夹的作用) mkdir [文件名]
在root目录下创建Desktop文件夹 mkdir /root/Desktop
mkdir [文件夹1] [文件夹2] [文件夹3] 在当前目录下一次性创建多个文件夹
[root@root desktop]# mkdir txt01 txt02 txt03
[root@root desktop]# ls
hello world! txt01 txt02 txt03
mkdir -p [文件夹/文件夹/文件夹] 一次性递归创建多个文件夹
[root@root desktop]# mkdir -p txt01/ops/nginx
[root@root nginx]# pwd
/root/desktop/txt01/ops/nginx
可以同时创建多个文件夹,且注意绝对,相对路径。
如:一次性在当前目录下创建 原神,在/opt下创建gensin并在其文件夹里再创建game文件夹,在/根目 录下创建star,在上一级目录创建zzz。
[root@root desktop]#mkdir -p ./原神 /opt/gensin/game /star ../zzz rmdir命令
rmdir 删除空目录 rmdir [文件名] rmdir /root/Desktop
在root目录下删除Desktop文件夹rmdir [文件夹1] [文件夹2] [文件夹3] #删除的是最后一个文件夹3.rmdir -p [文件夹1] [文件夹2] [文件夹3] #递归删除改路径下的所有文件夹,前提是文件夹里没文件。创建和删除文件
touch命令
touch 创建文本(1.创建文件 2.修改时间戳) touch {文本名}[.txt]
1.该文件名不存在,则创建该文件
创建一个happy.txt文件 touch happy.txt
1.1 touch '[filename!!]' 加上单引号可以命名特殊符号,"/"除外。
[root@root desktop]# touch hello world!
[root@root desktop]# ll
total 0
-rw-r--r--. 1 root root 0 Jul 16 22:07 hello
-rw-r--r--. 1 root root 0 Jul 16 22:07 world!
[root@root desktop]# touch 'hello world!'
[root@root desktop]# ll
total 0
-rw-r--r--. 1 root root 0 Jul 16 22:07 hello world!
2.该文件名存在,则是修改他的文件时间属性(被访问的时间是什么时候)例题一
修改 /desktop/happy.txt 的访问时间为 2018-08-08:13:00
touch -d "2018-08-08:13:00" -a /desktop/happy.txt例题二
修改 /desktop/happy.txt 的数据修改时间为 2018-08-08:13:00
touch -d "2018-08-08:13:00" -m /desktop/happy.txt在同级目录下创建多个文件,文件夹也同样适用
[root@root ~]# touch desktop/game/mihoyo/{gemsin,star,zzz}
[root@root ~]# mkdir -p desktop/mingcaho/{今夕,长离}
[root@root ~]# tree -FN desktop/
desktop/
├── game/
│ └── mihoyo/
│ ├── gemsin
│ ├── star
│ └── zzz
└── mingcaho/
├── 今夕/
└── 长离/
5 directories, 3 files
# "/"表示文件夹类型,没有"/"表示文件类型花括号{ }结合touch命令,创建多个连续文件
创建1~10个game.log文件
[root@root desktop]# touch game{1..10}.log
[root@root desktop]# ls
game10.log game2.log game4.log game6.log game8.log
game1.log game3.log game5.log game7.log game9.log
删除1~10个game.log文件
[root@root desktop]# sudo rm game{1..10}.logstat命令可以查看文件详细信息
stat是status英文单词的缩写,表示状态的意思。
这里用于证明touch命令可以修改时间戳
[root@root desktop]# echo "原神启动" > hello\ world\!
[root@root desktop]# cat hello\ world\!
原神启动
[root@root desktop]# stat hello\ world\!
File: ‘hello world!’
Size: 13 Blocks: 8 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 18217622 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Context: unconfined_u:object_r:admin_home_t:s0
Access: 2024-07-16 22:15:39.109795966 +0800
Modify: 2024-07-16 22:15:36.060796166 +0800
Change: 2024-07-16 22:15:36.060796166 +0800
Birth: -
#stat命令可以查看文件的详细信息,
#Access 访问时间
#Modify 文件内容修改变化时间
#Change 文件的权限,文件名,文件大小等变化时间。vim也可以创建文件
vim模式
vim编辑器的三种工作模式
命令模式
输入模式
末行模式
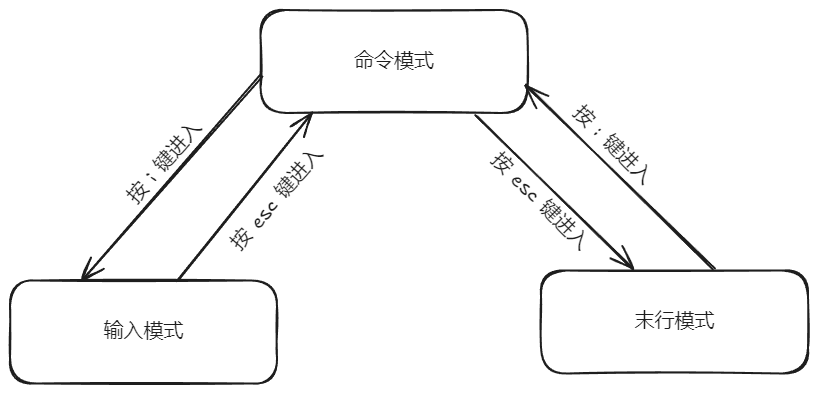
命令模式
启动vim编辑器后,默认进入命令模式。 该模式下可以使用方向键 ↑ 、↓ 、← 、→ 或k(上)、j(下)、h(左)、l(右)键来移动光标的位置,还可以通过命令对文件内容进行复制、粘贴、替换、删除等一系列操作。
输入模式
在命令模式下,输入
`i` # 进入输入模式并且从当前光标开始编辑
`o` # 进入输入模式并且从光标下一行开始编辑
`O` # 进入输入模式并且从光标上一行开始编辑末行模式
在命令模式下,输入 : 进入末行模式
配置Vim /etc/.vimrc #表示全局 ~/.vimrc #表示个人
在.vimrc中可以设置参数:
set nu #显示行号 set cul #突出显示当前所在行 set ai #设置自动缩进,每行与上一节缩进相同 set ts=4 #设置tab键宽度为4个空格
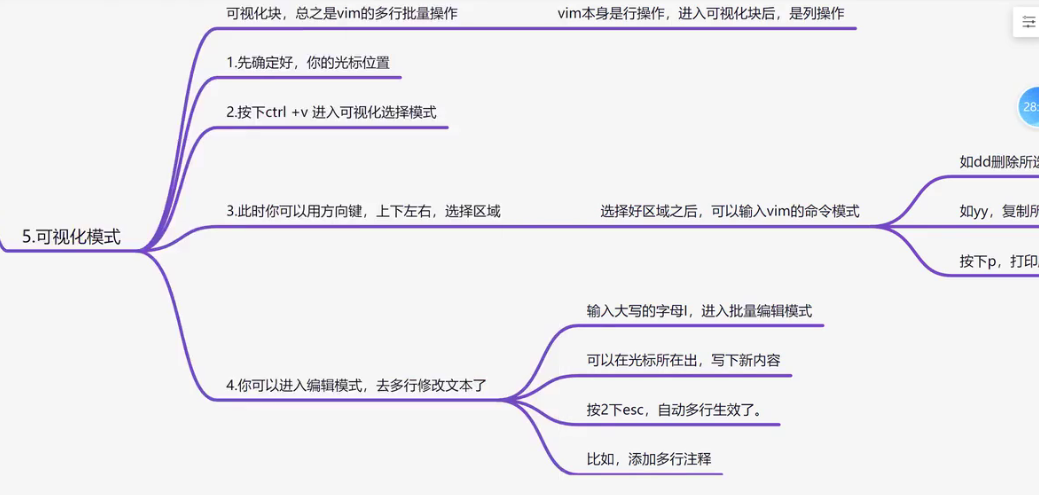
可视化模式
vim的swp文件处理
出现这个问题的原因
多个人同时编辑了文件
你编辑文件时,没有正常保存退出
echo命令
echo结合重定向符号
>才能创建文件
echo和引号的关系密切
1,Linux下的双引号,表示定义字符串,但是它能识别特殊符号(注意区分特殊符号中英文)。
[root@localhost ~]# echo "原神启动!!!"
-bash: !": event not found
2,Linux下的单引号,表示不做特殊符号转译,仅仅是一个纯字符串。
[root@localhost ~]# echo '原神启动!!!'
原神启动!!!
echo除了可以打印字符串也可以打印变量。
[root@localhost ~]# name='我将点燃大海'
[root@localhost ~]# echo ${name}
我将点燃大海
[root@localhost ~]# echo $name
我将点燃大海
echo 重定向输出字符 echo "[内容]" > [文件名]
将文本写入到名为happy.txt文件里
[admin@localhost ~]$ echo "今天是个好日子" > happy.txt echo追加内容>>
Linux文件单引号' '与双引号" "的区别
单引号——写什么执行什么。
[root@root ~]# man='manba out,!!'
[root@root ~]# echo ${man}
manba out,!!双引号—>对特殊字符进行转译执行。
如: !! 执行的含义为—>取得上一次执行的命令是什么。
[root@root ~]# man24="manba out,!!"
man24="manba out,echo ${man}"
[root@root ~]# echo ${man24}
manba out,echo manba out,!!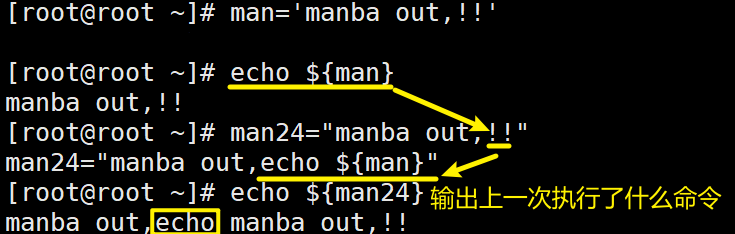
rm删除命令
rm 删除单个文件 rm [文件名]
删除多个文件 rm file1.txt file2.txt file3.txt
使用通配符删除多个文件 rm *.txt
递归删除文件夹 rm -r directory_name
强制删除文件,不询问确认 rm -f filename.txt
同时递归和强制删除 rm -rf directory_name
删库跑路(高危命令) rm -rf /*
删除单个文件 [root@root desktop]# rm game1.log
rm: remove regular empty file ‘game1.log’? yes
强制删除文件 [root@root desktop]# rm -f game{2..10}.log
sudo rm [文件] 可以在命令前加上`sudo`以管理员权限执行shred粉碎文件
shred命令与rm命令的区别
rm命令,删除文件,其实还是可以恢复的,现在的文件系统,都是日志型系统(你的操作,其实被系统监控,录制,做了个备份)。rm删除数据后,磁盘其实还未立即彻底删除,根据磁盘恢复数据手段,还是可以把数据拿回来的。
shred命令,这个命令之所以叫粉碎文件,是随机写入一堆二进制数据,导致原文件无法使用。
随机写入二进制数据到文件中,比较危险,不推荐使用。
[root@yuanlai-0224 test_tar]# shred gushi.txt ln命令,创建快捷方式,软链接
ln是link的意思,表示创建一个快捷方式。
用法
ln [选项] [目标文件] [链接文件]
[root@server ~]# ln -s /opt/t1.txt /opt/link_t1
[root@server ~]# ll /opt/
total 2804
drwxr-xr-x 10 root root 222 Aug 18 20:10 eladmin
lrwxrwxrwx 1 root root 11 Aug 23 15:34 link_t1 -> /opt/t1.txt
-rw-r--r-- 1 root root 82 Aug 17 23:06 t1.txt
[root@server ~]# cat /opt/link_t1
31
31
21
[root@server ~]# cat /opt/t1.txt
31
31
21选项
-b或--backup:删除,覆盖目标文件之前的备份;
-d或-F或——directory:建立目录的硬连接;
-f或——force:强行建立文件或目录的连接,不论文件或目录是否存在;
-i或——interactive:覆盖既有文件之前先询问用户;
-n或--no-dereference:把符号连接的目的目录视为一般文件;
-s或——symbolic:对源文件建立符号连接,而非硬连接;
-S<字尾备份字符串>或--suffix=<字尾备份字符串>:用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,预设的备份字符串是符号“~”,用户可通过“-S”参数来改变它;
-v或——verbose:显示指令执行过程;
-V<备份方式>或--version-control=<备份方式>:用“-b”参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这个字符串不仅可用“-S”参数变更,当使用“-V”参数<备份方式>指定不同备份方式时,也会产生不同字尾的备份字符串;
--help:在线帮助;
--version:显示版本信息。alias别名命令
查看系统默认别名
[admin@root ~]$ alias
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias vi='vim'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
重新设置别名
[admin@root ~]$ alias rm='rm -i'
自定义命令
[root@root ~]# ls /var/log
anaconda dmesg.old pluto tallylog
audit firewalld ppp tuned
[root@root ~]# alias lg='ls /var/log'
[root@root ~]# lg
anaconda dmesg.old pluto tallylog
audit firewalld ppp tuned
取消别名
unalias [别名]
永久好使,并且别影响到被人,怎么永久添加
写入到自己的用户环境变量文件中
~/.bash_profile实例
给启动django的命令做一个简单的别名
alias stdj='python3 manage.py runserver 0.0.0.0:8000'
取消别名
unalias stdjcp拷贝命令
拷贝文件且改名
[root@root desktop]# cp ./manba.txt /home/out.txt
[root@root desktop]# ls /home/
admin out.txt
仅拷贝文件
[root@root desktop]# cp ./manba.txt /home/maba.txt
[root@root desktop]# ls /home/
admin out.txt
-r 拷贝文件夹,递归拷贝操作
[root@root dev]# tree -N gemsin/
gemsin/
└── yuan
├── 111.txt
├── 222.txt
└── 333.txt
1 directory, 3 files
[root@root dev]# cp -r ./gemsin/ /opt/ZZZ
[root@root dev]# tree -N /opt/
/opt/
├── ZZZ
│ └── yuan
│ ├── 111.txt
│ ├── 222.txt
│ └── 333.txt
注意有坑:这个/opt/文件夹下是否有gemsin这个文件夹,没有则会拷贝并修改文件夹名↑,有则会将整个目录复制进同名文件夹里↓,mv命令也一样。
[root@root dev]# cp -r ./gemsin/ /opt/ZZZ
[root@root dev]# tree -N /opt/
/opt/
├── ZZZ
│ └── gemsin
│ └── yuan
│ ├── 111.txt
│ ├── 222.txt
│ └── 333.txtmv移动,剪切和重命名命令
从A目录移动到B目录,移动单个文件
mv [文件路径] [目标文件路径]
[root@root opt]# tree -N /opt/
/opt/
├── gensin
│ └── game
├── rh
├── 璃月
│ └── 岩神
│ └── 钟离.png
绝对路径移动
[root@root opt]# mv /opt/璃月/岩神/钟离.png /opt/璃月/
[root@root opt]# tree -N /opt/
/opt/
├── gensin
│ └── game
├── rh
├── 璃月
│ ├── 岩神
│ └── 钟离.png
文件重命名
mv [源文件] [重命名后的文件]
[root@root 岩神]# ls
钟离.png
[root@root 岩神]# mv 钟离.png zhongli.txt
[root@root 岩神]# ls
zhongli.txt
[root@root 岩神]# mv ./zhongli.txt /opt/璃月/岩神/钟离.png
[root@root 岩神]# tree -N /opt/
/opt/
├── gensin
│ └── game
├── rh
├── 璃月
│ └── 岩神
│ └── 钟离.png
移动文件夹
[root@root opt]# mv /opt/璃月 /opt/稻妻
[root@root opt]# tree -N /opt/
/opt/
├── gensin
│ └── game
├── rh
├── 稻妻
│ ├── 璃月
│ │ └── 岩神
│ │ └── 钟离.png
│ └── 雷神
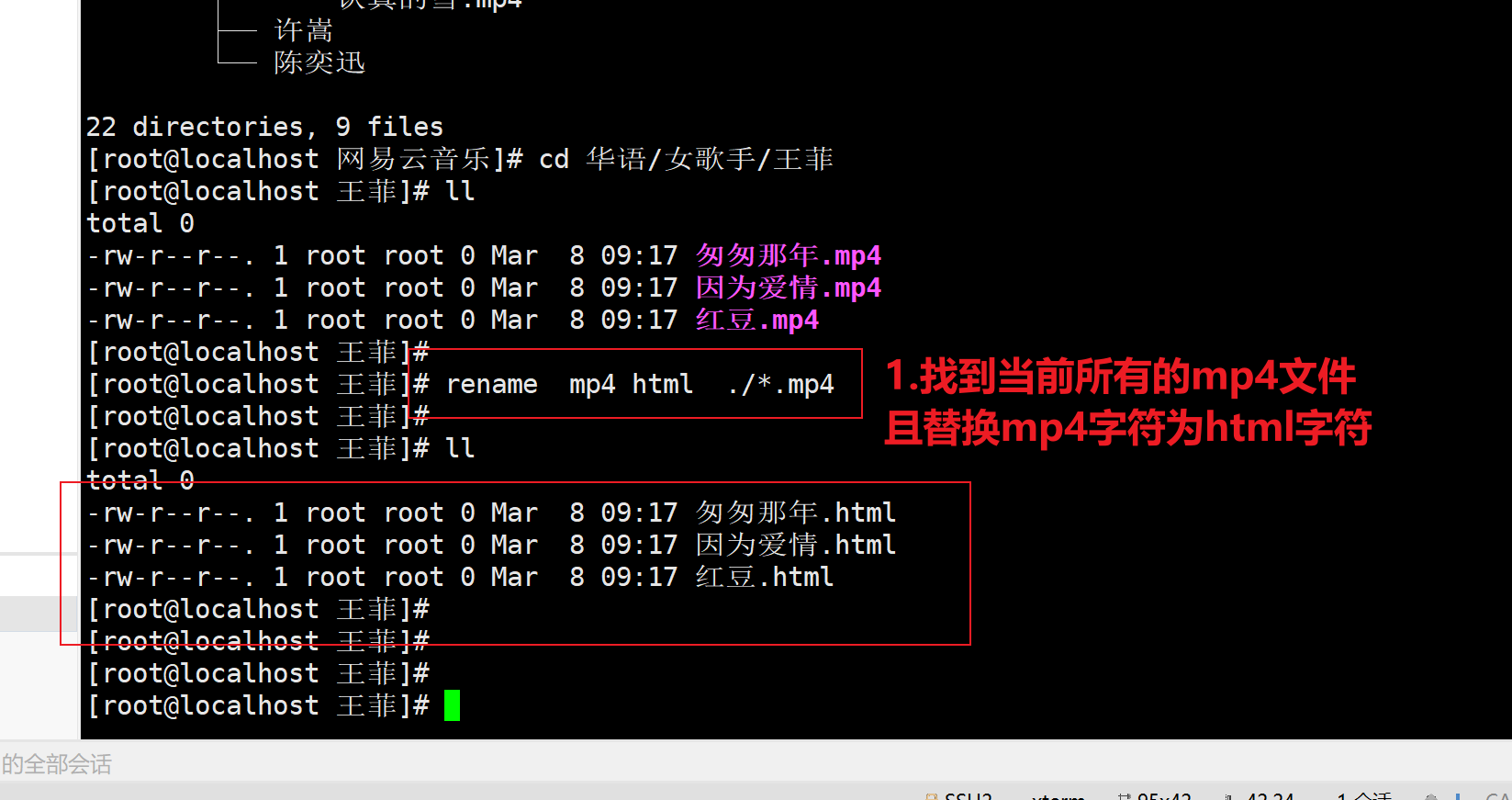
│ └── 雷电将军.pngrename命令批量重命名文件或目录
压缩与解压缩
tar [参数] [打包文件名] [你要打包的文件内容]
常见参数:
用不同的参数,有不同的作用
tar实现,到底是打包,还是压缩,或者是解压缩,就看给的参数是什么。
-c,create 创建的意思,打包。
-C,解压到指定路径。
[root@root ~]# tar -zxvf test.txt -C [路径]
-v,显示打包文件过程。
-f,指定打包的文件名,此参数是必须加的,且必须在最后一位。
-u,update缩写,更新原打包文件中的文件(了解)
-t,查看打包的文件内容(了解)(不解压,看看里面有什么)
-x,解包,解压缩(将一个单个的压缩文件,解压其中内容)
-z,压缩操作,是tar命令,去调用gzip命令的过程,压缩的参数。
提示:
tar命令打包的文件,通常称为tar包,如yuchao-all.tar文件
提问:
tar是个谁看的?是给centos看的,还是给运维超哥看的?压缩文件名命名规范
用tar命令压缩的文件,一般后缀加
*.tar 仅打包
*.tar.gz 打包+压缩
*.tgz 打包+压缩
打包
[root@root 0024]# tar -cvf all_zzz.tar zzz.txt zzz.txt1 zzz.txt2 zzz.txt3
查看打包文件中的内容
[root@root 0024]# tar -tf all_zzz.tar
zzz.txt
zzz.txt1
zzz.txt2
zzz.txt3
解包
[root@root 0024]# tar -xvf all_zzz.tar
zzz.txt
zzz.txt1
zzz.txt2
zzz.txt3
[root@root 0024]# ll
total 114596
-rw-r--r--. 1 root root 58675200 Jul 27 01:07 all_zzz.tar
-rw-r--r--. 1 root root 14666700 Jul 27 00:58 zzz.txt
-rw-r--r--. 1 root root 14666700 Jul 27 00:58 zzz.txt1
-rw-r--r--. 1 root root 14666700 Jul 27 00:58 zzz.txt2
-rw-r--r--. 1 root root 14666700 Jul 27 00:58 zzz.txt3
万能解压命令 -zxvf,解压压缩过的压缩包 .tar.gz
[root@root 0024]# tar -zxvf jdk-8u221-linux-x64.tar.gz
追加文件进归档包 -rvf -uvf
[root@root 0024]# tar -uvf all_zzz.tar 222.log
[root@root 0024]# tar -tf all_zzz.tar
zzz.txt
zzz.txt1
zzz.txt2
zzz.txt3
222.log打包并压缩
可以用tar 命令同时完成归档和压缩的操作,就是给tar 命令多加一个选项参数-z,使之完成归档操作后,还是调用gzip或bzip2命令来完成压缩操作。压缩后的文件后缀名为.tar.gz.
[root@root 0024]# tar -czvf all_zzz.tar.gz ./*
./222.log
./zzz.txt
./zzz.txt1
./zzz.txt2
./zzz.txt3
除了-z的压缩参数还有哪些
-z,压缩为.gz格式
-j,压缩为.bz2格式
-1,压缩为.xz格式
-c,create 创建的意思
-x,解压缩
-V,显示打包文件过程
-f,file指定打包的文件名,此参数是必须加的。
-u,update缩写,更新原打包文件中的文件(了解)
-t,查看打包的文件内容(了解)zip/unzip压缩/解压缩
“压缩 / 解压”zip文件(zip压缩文件一般来自于Windows操作系统)。
此命令需要自行安装
yum install zip
yum install unzip基础用法
zip -r test.zip test.txt 将test.tex文件压缩为test.zip,其中 -r 表示递归。
unzip -l test.zip 不解开 .zip 文件,只看其中内容。
unzip test.zip 解压 .zip 文件文件唯一值校验md5sum命令
用法
md5sum [文件/压缩包]
[root@localhost ~]# md5sum tengine-2.3.3.tar.gz
01651b1342c406b933490dd8f2962b36 tengine-2.3.3.tar.gz文件传输
lrzsz传输工具
Xshell直接拉取Windows本地文件到Linux当前目录
使用方法
1.先下载
2.使用文件传输工具,将该文件,发给linux
方法1,你的linux安装lrzsz工具,即可实现windows和xshell,直接拖拽文件
[root@localhost test_tar]# yum install lrzsz -y
安装该工具后,会自动生成
rz (接收)
sz (send 发送)
两个命令
3.获取win下载的那个文件
linux 接收,来自于win的文件
输入rz命令,接收scp远程传输
使用之前先把虚拟机网络连接改为桥接模式

scp用法
从本机192.168.31.125 server发送文件t1.txt到目标主机192.168.31.150 node1的/opt/目录下。
[root@server opt]# scp /opt/t1.txt root@192.168.31.150:/opt/
The authenticity of host '192.168.31.150 (192.168.31.150)' can't be established.
ECDSA key fingerprint is SHA256:eS2upD6YDw0mI8QSgYDIJlcGOTtoHwmEaDkRXRyebXk.
ECDSA key fingerprint is MD5:48:04:bb:96:90:08:9e:2a:ff:b2:b5:43:fc:8c:4f:0c.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.31.150' (ECDSA) to the list of known hosts.
root@192.168.31.150's password: root
t1.txt 100% 82 6.8KB/s 00:00
[root@node1 opt]# ls
0024 gensin rh t1.txt 璃月 稻妻 蒙德 须弥scp -r #递归传输
实例:把整个目录发过去
[root@server opt]# scp -r /var/log/ root@192.168.31.150:/tmp/把目标主机192.168.31.150 node1的/opt/目录中的
gensin文件夹拿到本机192.168.31.125 server的/opt/目录中。
[root@server opt]# scp -r root@192.168.31.150:/opt/gensin /opt
root@192.168.31.150's password:
[root@server opt]# ls
gensin rh t1.txt t2.txt
[root@server opt]# tree -N gensin/
gensin/
└── game
1 directory, 0 fileswget远程下载
该工具需要安装
yum install wget常用参数
-o 将日志信息写入指定的文件。
-O 将文档写入指定的文件。
-c 断点续传下载文件。文件相关命令
查看文件命令ls,ll
ls 查看当前目录下有哪些文件
[admin@localhost ~]$ ls
Desktop Documents Downloads happy happy.txt Music Pictures Public Videos
ls /dev/sd* 查看根目录下dev里的以sd开头的所有文件
[admin@localhost ~]$ ls /dev/sd*
/dev/sda /dev/sda1 /dev/sda2
ls -a 查看该目录中所有文件,包括隐藏文件。
[root@localhost ~]# ls -a
. anaconda-ks.cfg .bash_logout .bashrc .config .dbus
.. .bash_history .bash_profile .cache .cshrc desktop .tcshrc
ls -l / ll 查看更详细信息,并以列表展示。
[admin@localhost ~]$ ls -l / ll
total 0
drwxr-xr-x. 2 admin admin 6 Jul 10 17:19 Desktop
drwxr-xr-x. 2 admin admin 6 Jul 10 17:19 Documents
drwxr-xr-x. 2 admin admin 6 Jul 10 17:19 Downloads
-rw-rw-r--. 1 admin admin 0 Jul 14 16:20 happy
-rw-rw-r--. 1 admin admin 0 Jul 14 16:20 happy.txt
drwxr-xr-x. 2 admin admin 6 Jul 10 17:19 Music
drwxr-xr-x. 2 admin admin 6 Jul 10 17:19 Pictures
drwxr-xr-x. 2 admin admin 6 Jul 10 17:19 Public
drwxr-xr-x. 2 admin admin 6 Jul 10 17:19 Videos
ls -l /obt 查看/opt下文件的详细信息。
#[root@root opt]# ls
#rh
[root@root ~]# ls -l /opt/
total 0
drwxr-xr-x. 2 root root 6 Sep 7 2017 rh
ls -ld /opt 仅查看/opt目录本身的详细信息。
[root@root ~]# ls -ld /opt/
drwxr-xr-x. 3 root root 16 Jul 10 17:11 /opt/
ls -lh 与-l一起。以便于阅读的格式输出文件大小。(在普通用户模式下无效)
[root@localhost ~]# ls -lh
total 8.0K
-rw-------. 1 root root 1.6K Jul 10 17:15 anaconda-ks.cfg
drwxr-xr-x. 2 root root 6 Jul 16 16:23 desktop
-rw-r--r--. 1 root root 1.6K Jul 10 17:18 initial-setup-ks.cfg 常用参数
-l 显示详细列表
-a 显示所有文件和目录包括隐藏的
-h 适合人类阅读的
-t 按文件最近一次修改时间排序
-i 显示文件的inode (inode是文件内容的标识)
-r 倒序pwd 查看当前目录
[admin@localhost root]$ pwd
/rootfile查看文件类型
用法
file [文件名]
[root@localhost opt]# file jdk.tgz
jdk.tgz: ASCII text
[root@localhost opt]# file jdk-8u221-linux-x64.tar.gz
jdk-8u221-linux-x64.tar.gz: gzip compressed data, from Unix, last modified: Thu Jul 4 19:38:16 2019
看伪装的压缩文件原形毕露文本操作相关命令
查看文本命令cat
cat命令一次性读取所有内容到内存上不适合读取大文件。
cat 查看文件内容 cat [文件名] cat happy.txt
查看名为happy.txt文件内容
[admin@localhost ~]$ cat happy.txt
今天是个好日子常用参数
-n 显示行号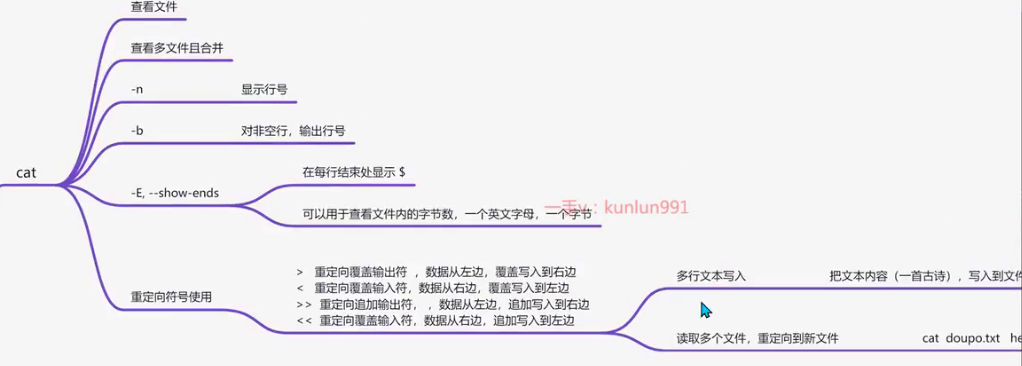
利用cat写入多行文本
用法
[root@localhost ~]# cat >> 春晓.txt <<EOf
>春晓
>春眠不觉晓
>处处闻啼鸟
>夜来风雨声
>花落知多少
>EOF
#EOF是一个关键字,End Of File,指文件的结束。查看文本命令tac
将文件从后向前倒着查看
more分页显示文件内容
more命令cat一次性读取所有内容到内存上不适合读取大文件。
用法
more /var/log/cloud-init.log
#空格是翻页
#回车是一行一行查看less分页显示文件内容
分页显示文件内容,更适合查看大的文件。
less /var/log/cloud-init.log快捷操作
空格键:前进一页(一个屏幕) ;
b 键:后退一-页;
回车键:前进一-行;
y 键:后退一行;
上下键:回退或前进一行;
d 键:前进半页;
q 键:停止读取文件,中止less命令;
= 键:显示当前页面的内容是文件中的第几行到第几行以及一-些其它关于本页内容的详细信息;
h 键:显示帮助文档;
/ 键:进入搜索模式后,按n键跳到- -个符合项目,按N键跳到上- -个符合项目,同时也可以输入正则表达式匹配。
? 键:向上查找,与/键相反。
head
显示文件的开头几行(默认是10行)
head cloud-init.log参数
-n 指定行数
head -2 cloud-init.logtail
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。
tail -f filename 会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容。
命令格式:
tail [参数] [文件] 参数
-f 会每过1秒检查下文件是否有更新内容,可监测文件变化,多用于查看日志。(循环读取)
-F 在文件被删除或改名后,如果重建同名文件,会继续跟踪。
tail [-f|-F] /var/log/xxx.log
-q 不显示处理信息
-v 显示详细的处理信息
-c<数目> 显示的字节数
-n<行数> 显示文件的尾部 n 行内容
tail -2 cloud-init.log
--pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
-q, --quiet, --silent 从不输出给出文件名的首部
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒实例
显示文件的结尾几行(默认是10行)
tail cloud-init.log要跟踪名为 notes.log 的文件的增长情况,请输入以下命令:
tail -f notes.log显示 notes.log 文件的最后 10 行。当将某些行添加至 notes.log 文件时,tail 命令会继续显示这些行。 显示一直继续,直到您按下(Ctrl-C)组合键停止显示。
显示文件 notes.log 的内容,从第 20 行至文件末尾:
tail -n +20 notes.log显示文件 notes.log 的最后 10 个字符:
tail -c 10 notes.logfind查找命令
文件搜索(递归搜索)
find [path] [expression]参数说明
#path 是要查找的目录路径,可以是一个目录, 也可以是多个路径,多个路径之间用空格分隔,如果未指定路径,则默认为当前目录。
#expression 可选参数,用于指定查找的条件,可以是文件名,文件类型,文件大小等。
#expression 中可使用的选项有二三十个之多,以下列出最常用的部份:
-name pattern:按文件名查找,支持使用通配符 * 和 ?进行模糊搜索。
-type type:按文件类型查找,可以是 f(普通文件)、d(目录)、l(符号链接)等。
-size [+-]size[cwbkMG]:按文件大小查找,支持使用 + 或 - 表示大于或小于指定大小,不加 -+ 表示等于。单位可以是 c(字节)、w(字数)、b(块数)、k(KB)、M(MB)或 G(GB)。
-mtime days:按修改时间查找,支持使用 + 或 - 表示在指定天数前或后,days 是一个整数表示天数。
-user username:按文件所有者查找。
-o 找出多种类型的文件。
-group groupname:按文件所属组查找。
find 命令中用于时间的参数如下:
-amin n:查找在 n 分钟内被访问过的文件。
-atime n:查找在 n*24 小时内被访问过的文件。
-cmin n:查找在 n 分钟内状态发生变化的文件(例如权限)。
-ctime n:查找在 n*24 小时内状态发生变化的文件(例如权限)。
-mmin n:查找在 n 分钟内被修改过的文件。
-mtime n:查找在 n*24 小时内被修改过的文件。在这些参数中,n 可以是一个正数、负数或零。正数表示在指定的时间内修改或访问过的文件,负数表示在指定的时间之前修改或访问过的文件,零表示在当前时间点上修改或访问过的文件。
例如:
-mtime 0 表示查找今天修改过的文件,-mtime -7 表示查找一周内修改过的文件。
关于时间 n 参数的说明:
+n:查找比 n 天前更早的文件或目录。
-n:查找在 n 天内更改过属性的文件或目录。
n:查找在 n 天前(指定那一天)更改过属性的文件或目录。
-o:是或者的意思。
-a:是并且的意思。
-not:是取反的意思。
-empty:搜索空文件或空目录。例题
查找当前目录下名为 file.txt 的文件:
# find . -name file.txt
将当前目录及其子目录下所有后缀为 .c 的`文件`并列出来:
# find . -type f -name "*.c"
查找 /home 目录下大于 1MB 的文件:
# find /home -size +1M
查找 /var/log 目录下在 7 天前修改过的文件:
# find /var/log -mtime +7
将当前目录及其子目录下所有最近 20 天前更新过的文件列出,不多不少正好 20 天前的:
# find . -ctime 20
将当前目录及其子目录下所有 20 天前及更早更新过的文件列出:
# find . -ctime +20
将当前目录及其子目录下所有最近 20 天内更新过的文件列出:
# find . -ctime -20
查找 /var/log 目录中更改时间在 7 日以前的普通文件,并在删除之前询问它们:
# find /var/log -type f -mtime +7 -ok rm {} \;
查找当前目录中文件属主具有读、写权限,并且文件所属组的用户和其他用户具有读权限的文
件:
# find . -type f -perm 644 -exec ls -l {} \;
查找系统中所有文件大小为 0 的普通文件,并列出它们的完整路径:
# find / -type f -size 0 -exec ls -l {} \
查找/var目录中所有文件大小为 10M 的普通文件,并列出它们的完整路径:
# find /var -type f -size +10M
找出/var目录下的log文件及txt文件
# find /var -type f -name "*.log" -o "*.txt"locate
Linux locate命令用于查找符合条件的文档,他会去保存文档和目录名称的数据库内,查找合乎范本样式条件的文档或目录
locate的特点
1.locate基于数据库的查询,速度很快,但不是实时的查询。 2.locate是模糊查询 3.需要对文件的目录有rx的权限
locate的语法
-b, --basename -- 仅匹配路径名的基本名称
-c, --count -- 只输出找到的数量
-d, --database DBPATH -- 使用 DBPATH 指定的数据库,而不是默认数据库 /var/lib/mlocate/mlocate.db
-e, --existing -- 仅打印当前现有文件的条目
-1 -- 如果 是 1.则启动安全模式。在安全模式下,使用者不会看到权限无法看到 的档案。这会始速度减慢,因为 locate 必须至实际的档案系统中取得档案的 权限资料。
-0, --null -- 在输出上带有NUL的单独条目
-S, --statistics -- 不搜索条目,打印有关每个数据库的统计信息
-q -- 安静模式,不会显示任何错误讯息。
-P, --nofollow, -H -- 检查文件存在时不要遵循尾随的符号链接
-l, --limit, -n LIMIT -- 将输出(或计数)限制为LIMIT个条目
-n -- 至多显示 n个输出。
-m, --mmap -- 被忽略,为了向后兼容
-r, --regexp REGEXP -- 使用基本正则表达式
--regex -- 使用扩展正则表达式
-q, --quiet -- 安静模式,不会显示任何错误讯息
-s, --stdio -- 被忽略,为了向后兼容
-o -- 指定资料库存的名称。
-h, --help -- 显示帮助
-i, --ignore-case -- 忽略大小写
-V, --version -- 显示版本信息locate的日常使用
1.查询passwd
[root@192 ~]# locate passwd -n 5
/etc/passwd
/etc/passwd-
/etc/pam.d/passwd
/etc/security/opasswd
/usr/bin/gpasswd2.忽略大小写查询
[root@192 ~]# locate -i CONF -n 5
/ansible/roles/webserver/files/httpd.conf
/boot/config-3.10.0-957.el7.x86_64
/boot/grub2/i386-pc/configfile.mod
/etc/GeoIP.conf
/etc/GeoIP.conf.default3.更新本地数据库
updatedb
[root@192 ~]# updatedb -V
updatedb (mlocate) 0.26
Copyright (C) 2007 Red Hat, Inc. All rights reserved.
This software is distributed under the GPL v.2.
This program is provided with NO WARRANTY, to the extent permitted by law.4.打印系统数据库的信息
root@192 ~]# locate -S
Database /var/lib/mlocate/mlocate.db:
13,857 directories
189,679 files
11,268,161 bytes in file names
4,331,363 bytes used to store databasewc(word count)统计命令
基本功能
用于计算文本中行数、单词数,字符数或字节数。基础语法
wc filename.txt #统计filename.txt
[root@localhost zzz]# wc test0.txt
1 1 10 test0.txt
第一个 1,表示行数
第二个 1,表示单词数
第三个 10,表示字节数
[root@localhost zzz]# cat test0.txt
mabao_out常用参数
-l 统计行数
-w 统计单词数
-c 统计字节数
-m 统计字符数查看ect目录下以.conf结尾的各文件的行数
wc -l /etc/*.conf
例题一:计算/etc目录下所有`.conf`文件的总行数。
[root@localhost ~]# wc -l /etc/*conf |grep -v total |awk '{print $1}' |xargs -n3
wc: /etc/dconf: Is a directory
wc: /etc/gconf: Is a directory
3 411 11
559 17 11
19 38 0
52 669 51
3 2 2
0 26 1
137 39 163
26 21 1
7 89 1
35 131 52
79 70 135
64 58 5
131 58 160
18 41 3
20 91 18
9 57 86
10 191 4
40 2 0
26
[root@localhost ~]# wc -l /etc/*conf |grep -v total |awk '{print $1}' |xargs
wc: /etc/dconf: Is a directory
wc: /etc/gconf: Is a directory
3 411 11 559 17 11 19 38 0 52 669 51 3 2 2 0 26 1 137 39 163 26 21 1 7 89 1 35 131 52 79 70 135 64 58 5 131 58 160 18 41 3 20 91 18 9 57 86 10 191 4 40 2 0 26
[root@localhost ~]# wc -l /etc/*conf |grep -v total |awk '{print $1}' |xargs |tr ' ' '+'
wc: /etc/dconf: Is a directory
wc: /etc/gconf: Is a directory
3+411+11+559+17+11+19+38+0+52+669+51+3+2+2+0+26+1+137+39+163+26+21+1+7+89+1+35+131+52+79+70+135+64+58+5+131+58+160+18+41+3+20+91+18+9+57+86+10+191+4+40+2+0+26
[root@localhost ~]# wc -l /etc/*conf |grep -v total |awk '{print $1}' |xargs |tr ' ' '+' |bc
wc: /etc/dconf: Is a directory
wc: /etc/gconf: Is a directory
3953
bc 表示计算。
例题二:
统计/etc目录下所有以.conf结尾的文件个数
[root@localhost ~]# find /etc -name "*.conf" | wc -l
435grep查找
基本功能
在文件中查找关键字,并显示关键字所在行。
grep [关键字] [目录]
例子一:
[root@localhost ~]# grep path /etc/profile
pathmunge () {
pathmunge /usr/sbin
pathmunge /usr/local/sbin
pathmunge /usr/local/sbin after
pathmunge /usr/sbin after
unset -f pathmunge
例子二:
[root@localhost ~]# grep hello /opt/mihoyo/zzz/test1.txt
hello world常见参数
-i 忽略大小写, grep -i path /etc/profile
-n 显示行号, grep -n path /ect/profile
-v 取反(获取不包含关键字的文件内容) grep -v path /etc/profile
-r 递归查找, grep -r hello /opt
-R 查找所有文件包含子目录
-o 只输出匹配的内容 grep -o
[root@localhost ~]# grep -r hello /opt/
/opt/mihoyo/zzz/test1.txt:hello world
^a a开头
a$ a结尾
/bin/bash$ 以/bin/bash结尾的行高级用法
grep -E 可以配合正则表达式使用,等价于egrep
grep -E path etc/profile --> 完全匹配path
grep -E^path etc/profile --> 匹配path开头的字符串
grep -E[Pp]ath etc/profile --> 匹配Path或path例题一
使用正则过滤出ens33网卡信息中的ip地址、掩码及广播地址。
[root@localhost dasan]# ifconfig ens33 | egrep -o '[0-9]{1,3}(\.[0-9]{1,3}){3}'
192.168.111.128
255.255.255.0
192.168.111.255
# -o 完全匹配
[root@localhost dasan]# ifconfig ens33 | egrep '[0-9]{1,3}(\.[0-9]{1,3}){3}'
inet 192.168.111.128 netmask 255.255.255.0 broadcast 192.168.111.255
#不完全匹配
例题二
在/etc/passwd用户文件中,过滤root用户并保持到/opt/admin.txt中
grep "root" /etc/passwd > /opt/admin1.txt
cat /etc/passwd |grep "root" > /opt/admin1.txt例题三
实时过滤/var/log/messages日志中的error内容并保存到/tmp/error.txt里
tail -f /var/log/messages |grep -i "error" >> /tmp/error.txt例题四
查看对应服务端口状态
netstat -antuple | grep [服务名][root@localhost ~]# netstat -anptule| grep zabbix
tcp 0 0 0.0.0.0:10050 0.0.0.0:* LISTEN 1099/zabbix_agentd
tcp 0 0 0.0.0.0:10051 0.0.0.0:* LISTEN 1922/zabbix_server
tcp6 0 0 :::10050 :::* LISTEN 1099/zabbix_agentd
tcp6 0 0 :::10051 :::* LISTEN 1922/zabbix_server 拓展xargs命令
xargs的作用是,简单的说 就是把其他命令的给它的数据,传递给它后面的命令作为参数。
先抛出需求
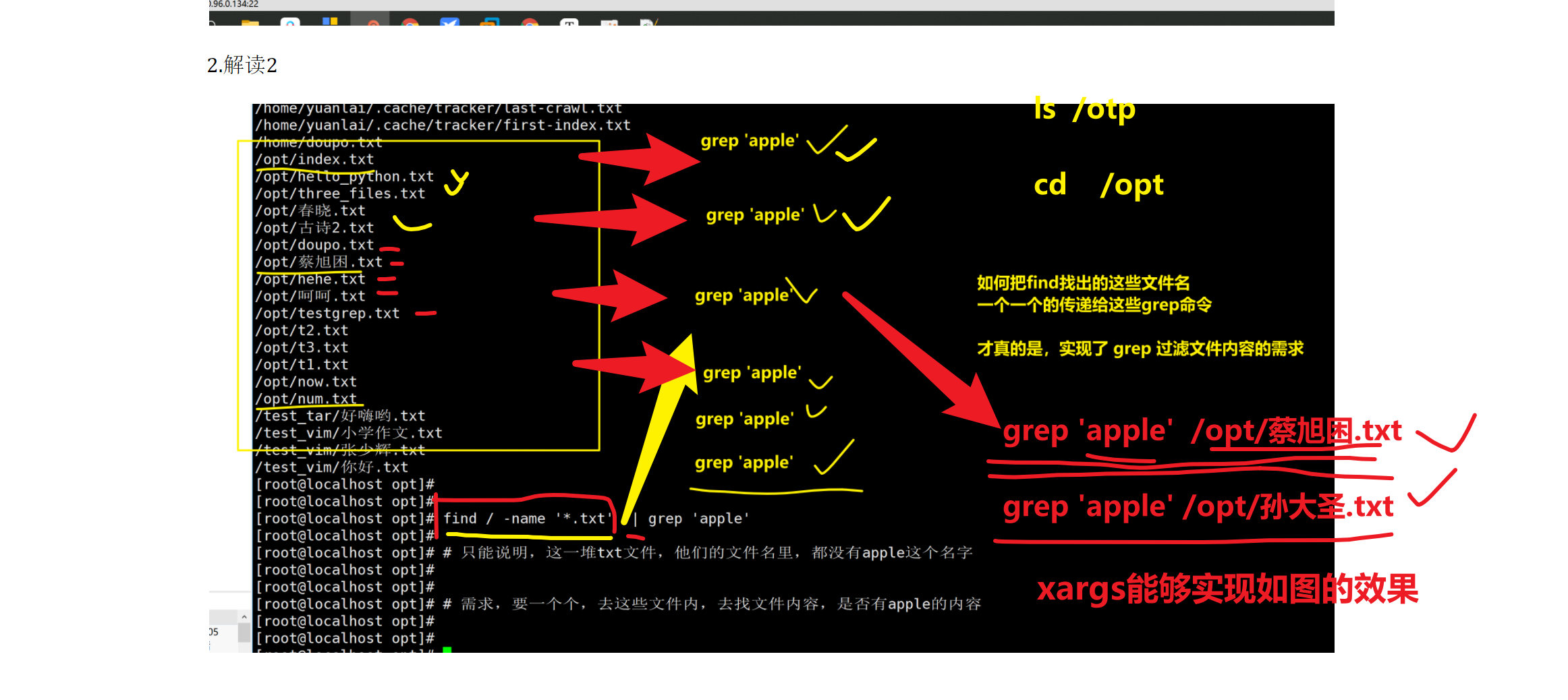
语法如下
命令1 | xargs 选项
选项
-i 用 {} 代替传递的数据例题一
xargs实现批量备份

例题二
xargs实现批量重命名,把/tmp目录下以txt.log结尾的文件改为以log结尾
ls /tmp/ |xargs -i rename txt.log log {}
rename txt.log log /tmp/*.log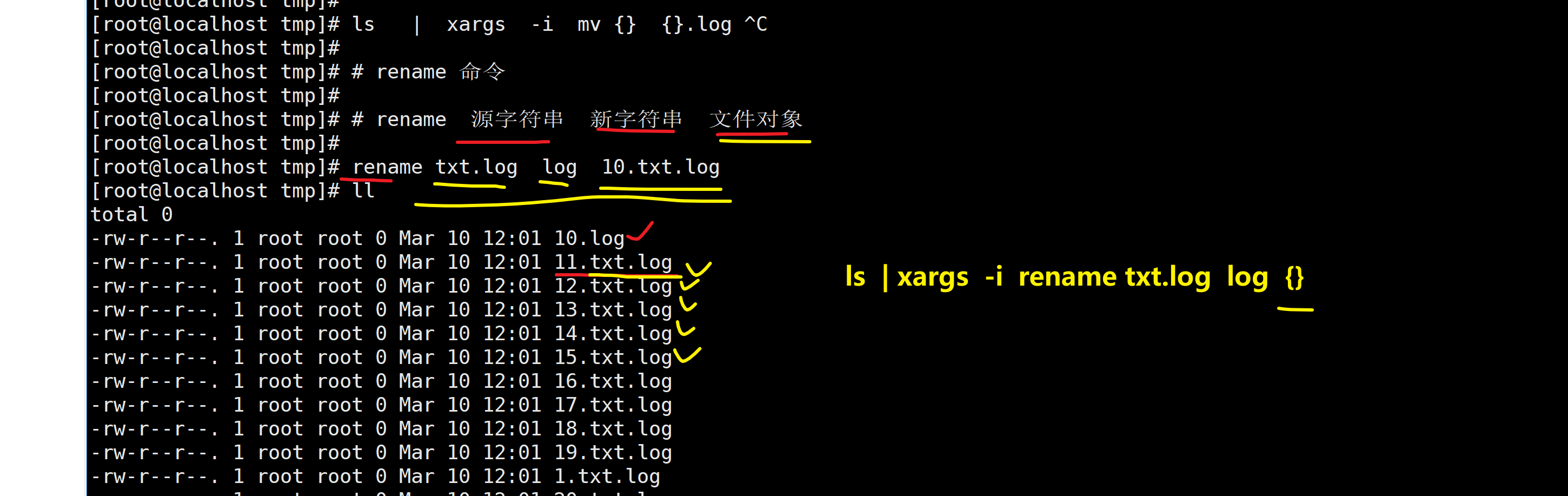
例题三
全系统中搜索,包含某数据的文件名
[root@localhost tmp]# find / -type f -name '*.txt' | xargs -i grep -l 'xiake' {}
/var/log/nginx/mima.txt例题三
备份/var/log下的所有.log文件到/var/log/log_bak目录下
find /var/log -type f -name '*.log' |xargs -i cp {} var/log/log_bak拓展exec和ok命令

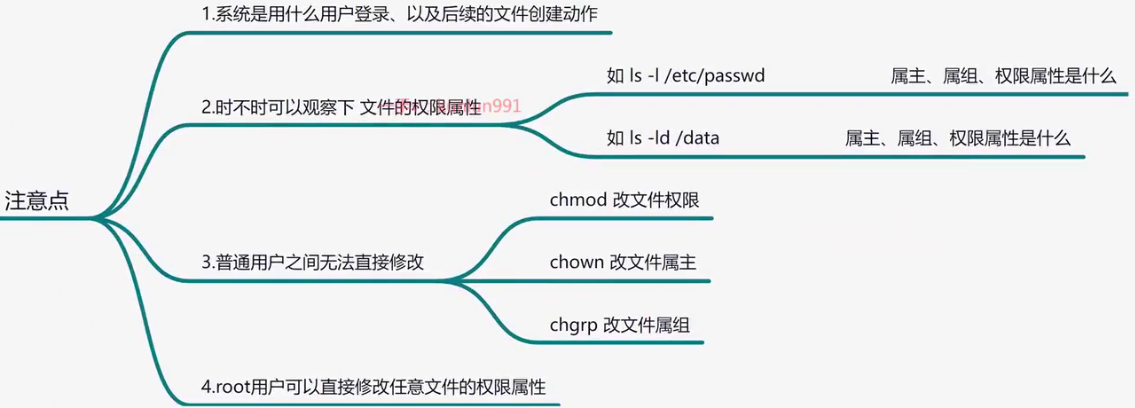
chmod文件权限
drwxr-xr-x. 2 admin admin 6 Jul 10 17:19 Downloads
-rw-rw-r--. 1 admin admin 0 Jul 14 16:20 happy
drwx各个含义:
d:文件夹
r:(read)可读 4
w:(write)可写 2
x:(execute)可执行 1
第一个rwx指user,第二个指group,第三个指other 可知Downloads文件夹权限为 755
chmod 修改权限
第一种:chmod [u/g/o+-r/w/x] [文件名/目录]
[admin@localhost ~]$ chmod u+x happy
[admin@localhost ~]$ chmod g+x happy
-rwxrwxr--. 1 admin admin 0 Jul 14 16:20 happy
[admin@localhost ~]$ chmod g-x happy
-rwxrw-r--. 1 admin admin 0 Jul 14 16:20 happy
第二种:chmod 754 [文件名/目录](rwxr-xr--)
[admin@localhost ~]$ chmod 754 happy
-rwxr-xr--. 1 admin admin 0 Jul 14 16:20 happychgrp修改文件所属组,group
chgrp yang hello.shchown修改文件所属主,user
chown yang hello.sh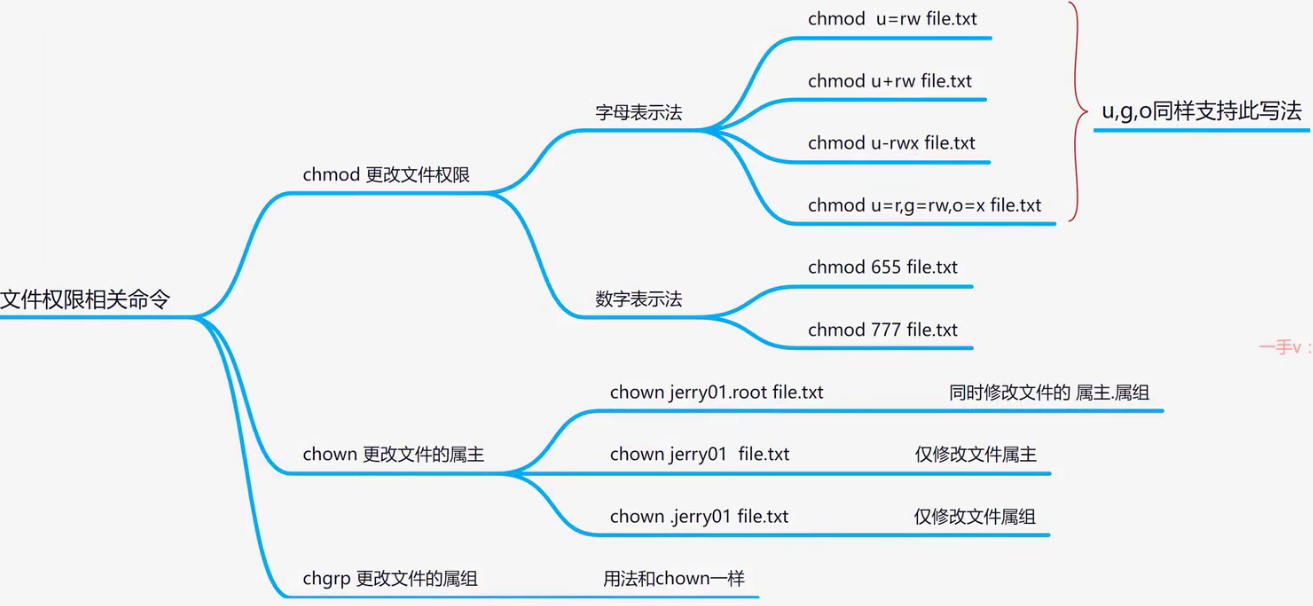
特殊权限
在linux系统中,除了r读w写x执行权限外,还存在其他的权限;下图中在权限位置上有不同的字母

特殊权限对照表
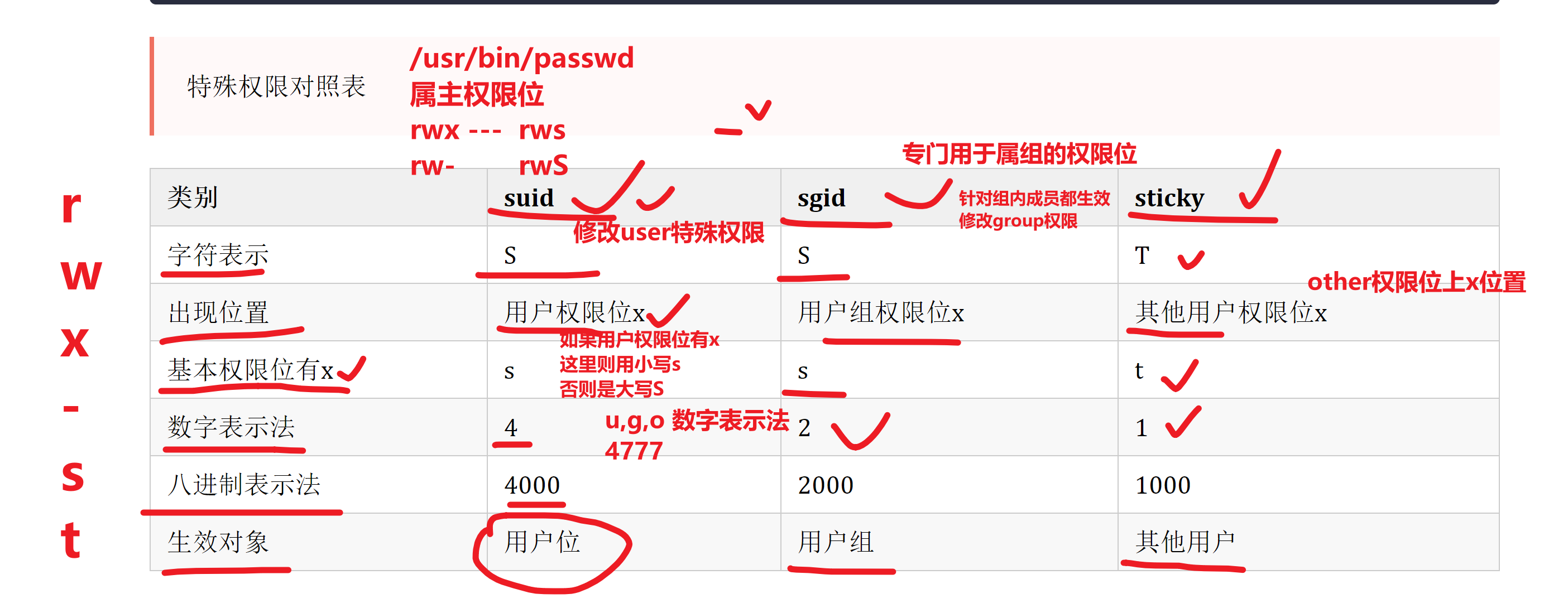
suid
sudi的作用
概念:命令文件的x权限位变为s,那么其他用户执行命令文件时,就会以该命令文件的属主用户去执行
如果属主权限位上有x,则会显示小s
如果属主权限位上没有x,则会显示大S
实例:
设置suid,普通用户可以正常修改自己的密码,取消suid,普通账户无法修改自己的密码
[root@localhost ~]# useradd tdm #创建用户tdm
[root@localhost ~]# passwd tdm #设置密码
Changing password for user tdm.
New password:
BAD PASSWORD: The password is shorter than 7 characters
Retype new password:
passwd: all authentication tokens updated successfully. #设置密码成功
[root@localhost ~]# su - tdm #切换用户tdm
Last login: Mon Jun 5 11:21:29 CST 2023 on pts/0
[tdm@localhost ~]$ passwd #修改密码
Changing password for user tdm.
Changing password for tdm.
(current) UNIX password:
New password:
Retype new password:
passwd: all authentication tokens updated successfully. #修改密码成功
[tdm@localhost ~]$ exit #退出登录
logout
[root@localhost ~]# chmod u-s /bin/passwd #修改passwd权限,取消suid权限
[root@localhost ~]# ll /bin/passwd #查看命令文件权限
-rwxr-xr-x. 1 root root 27832 Jun 10 2014 /bin/passwd #s变成了x
[root@localhost ~]# su - tdm #再次切换tdm账户
Last login: Mon Jun 5 11:24:54 CST 2023 on pts/0
[tdm@localhost ~]$ passwd #修改密码
Changing password for user tdm.
Changing password for tdm.
(current) UNIX password:
New password:
Retype new password:
passwd: Authentication token manipulation error #密码修改失败问题:如果普通用户在使用passwd命令时,是以root的身份去执行的,普通用户是否能修改其他账户的密码
无法修改,只有root在使用passwd命令时后面可以接用户名称,其他账号不可以。
[tdm@localhost ~]$ passwd test #tdm想修改test的密码
passwd: Only root can specify a user name. #只用root账户后面才能接用户名称授权、撤销suid权限
授权格式:
chmod u+s 文件名称
撤销格式:
chmod u-s 文件名称[root@localhost ~]# touch test.txt #创建文件
[root@localhost ~]# ll test.txt #查看文件属性
-rw-r--r--. 1 root root 0 Jun 5 11:37 test.txt
[root@localhost ~]# chmod u+s test.txt #授权suid属性
[root@localhost ~]# ll test.txt
-rwSr--r--. 1 root root 0 Jun 5 11:37 test.txt #文件具有suid属性
[root@localhost ~]# chmod u-s test.txt #文件取消suid属性
[root@localhost ~]# ll test.txt
-rw-r--r--. 1 root root 0 Jun 5 11:37 test.txt #文件取消suid属性
[root@localhost ~]# chmod 4644 test.txt #授权suid属性
[root@localhost ~]# ll test.txt
-rwSr--r--. 1 root root 0 Jun 5 11:37 test.txt #文件具有suid属性
[root@localhost ~]# chmod 0644 test.txt #文件取消suid属性
[root@localhost ~]# ll test.txt
-rw-r--r--. 1 root root 0 Jun 5 11:37 test.txt #文件取消suid属性sgid
sgid的作用
概念:一般情况下是设置给目录使用的,主要目的是让彼得用户无法删除其他用户所创建的文件或目录
如果属主权限位上有x,则会显示小s
如果属主权限位上没有x,则会显示大S
实例: 给目录设置了sgid权限,在该目录下创建的文件或者目录的属组都与该目录一致
[root@localhost opt]# mkdir abc #创建目录abc
[root@localhost opt]# ll
total 0
drwxr-xr-x. 2 root root 6 Jun 5 13:18 abc
[root@localhost opt]# chmod 777 abc #授予abc权限
[root@localhost opt]# ll
total 0
drwxrwxrwx. 2 root root 6 Jun 5 13:18 abc
[root@localhost opt]# su - tdm #切换用户
Last login: Mon Jun 5 13:15:58 CST 2023 on pts/0
[tdm@localhost ~]$ cd /opt/abc
[tdm@localhost abc]$ touch test.txt #创建test文件
[tdm@localhost abc]$ ll
total 0
-rw-rw-r--. 1 tdm tdm 0 Jun 5 13:18 test.txt #查看文件的属主属组,都是tdm
[root@localhost opt]# exit #退出tdm账户
logout
[root@localhost opt]# chmod g+s abc/ #给目录abc授予sgid权限
[root@localhost opt]# ll
total 0
drwxrwsrwx. 2 root root 22 Jun 5 13:18 abc #目录具有sgid权限
[root@localhost opt]# su tdm
[tdm@localhost opt]$ ll
total 0
drwxrwsrwx. 2 root root 22 Jun 5 13:18 abc
[tdm@localhost opt]$ cd abc
[tdm@localhost abc]$ touch test1.txt #创建test1.txt文件
[tdm@localhost abc]$ ll
total 0
-rw-rw-r--. 1 tdm root 0 Jun 5 13:21 test1.txt #该文件的属组跟随目录的属组是root
-rw-rw-r--. 1 tdm tdm 0 Jun 5 13:18 test.txt授权、撤销sgid权限
授权格式:
chmod g+s 文件名称
撤销格式:
chmod g-s 文件名称练习
将sgid和红帽认证考题结合练习
1.创建一个共享目录/home/admins
[root@localhost ~]# mkdir /home/admins2.要求该目录属组是adminuser,adminuser组内成员对该目录的权限是,可读,可写,可执行。
创建组adminuser
[root@localhost ~]# groupadd adminuser
修改/home/admins的属组
[root@localhost ~]# chgrp adminuser /home/admins
修改group角色的权限是 r,w,x
[root@localhost ~]# chmod g=rwx /home/admins3.其他用户均无任何权限(root特例)
[root@localhost ~]# chmod o='' /home/admins4.进入/home/admins创建的文件,自动继承adminuser组的权限。(难点)
(这里用到了sgid的权限吗,你需要给/home/admins设置sgid权限,肯定得是root去设置吧)
用字母表示法,给文件夹设置sgid权限
[root@localhost ~]# chmod g+s /home/admins
用数字表示法,给文件夹设置sgid权限
[root@localhost ~]# chmod 2770 /home/admins
查看是否生效
[root@localhost ~]# ll /home/admins/ -d
drwxrws---. 2 root adminuser 6 3月 17 11:50 /home/admins/5.此时你在这个目录下,创建的文件,自动继承adminuser的权限(文件的group,默认就是adminuser了)
[root@localhost ~]# touch /home/admins/我是root.log
[root@localhost ~]# mkdir /home/admins/我是root文件夹
[root@localhost ~]# ll /home/admins/
总用量 0
-rw-r--r--. 1 root adminuser 0 3月 17 11:56 我是root.log
drwxr-sr-x. 2 root adminuser 6 3月 17 11:56 我是root文件夹
发现文件夹,也自动有了s权限,还实现了递归继承的效果sbit粘滞位特殊权限
sbit的作用
如果属主权限位上有x,则会显示小t
如果属主权限位上没有x,则会显示大T
实例:
只作用在目录上,当一个目录没有设置sticky bit权限时,并且该目录对所有的用户都有读写执行权限时,普通用户在该目录下创建的文件或目录都会被其他用户删除
[root@localhost opt]# ll
total 0
drwxrwxrwx. 2 root root 6 Jun 5 13:30 abc #当前目录对所有用户都有读写执行权限
[root@localhost opt]# su test #切换至test账户
[test@localhost opt]$ ll
total 0
drwxrwsrwx. 2 root root 39 Jun 5 13:21 abc
[test@localhost opt]$ cd abc
[test@localhost abc]$ ll
total 0
-rw-rw-r--. 1 tdm root 0 Jun 5 13:21 test1.txt
-rw-rw-r--. 1 tdm tdm 0 Jun 5 13:18 test.txt
[test@localhost abc]$ rm -f test1.txt #删除test1文件
[test@localhost abc]$ rm -f test.txt #删除test文件
[test@localhost abc]$ ll #目录为空,文件已被删除
total 0当一个目录设置了sticky bit权限时,普通用户在该目录下所创建的文件或目录,只能被该文件或目录的属主用户或者root删除,其他用户无法删除彼得用户所创建的文件或者目录
drwxrwxrwx. 2 root root 6 Jun 5 13:30 abc
[root@localhost opt]# chmod o+t abc #给目录授予sbit权限
[root@localhost opt]# ll
total 0
drwxrwxrwt. 2 root root 6 Jun 5 13:30 abc
[root@localhost opt]# su test #切换test账户
[test@localhost opt]$ cd abc
[test@localhost abc]$ touch test.txt #创建文件
[test@localhost abc]$ ll
total 0
-rw-rw-r--. 1 test test 0 Jun 5 13:47 test.txt
[test@localhost abc]$ exit
exit
[root@localhost opt]# su tdm #切换tdm账户
[tdm@localhost opt]$ cd abc
[tdm@localhost abc]$ ll
total 0
-rw-rw-r--. 1 test test 0 Jun 5 13:47 test.txt
[tdm@localhost abc]$ rm -f test.txt #tdm账户删除test文件
rm: cannot remove ‘test.txt’: Operation not permitted #操作不允许授权、撤销sbit权限
授权格式:
chmod o+t 文件名称
撤销格式:
chmod o-t 文件名称五.总结
SUID: user - 占据属主的执行权限位
s: 属主拥有 x 权限
S:属主没有 x 权限
SGID: group - 占据 group 的执行权限位
s: group 拥有 x 权限
S:group 没有 x 权限
Sticky: other - 占据 ohter 的执行权限位
t: other 拥有 x 权限
T:other 没有 x 权限
参考:https://blog.csdn.net/m0_57515995/article/details/124817049
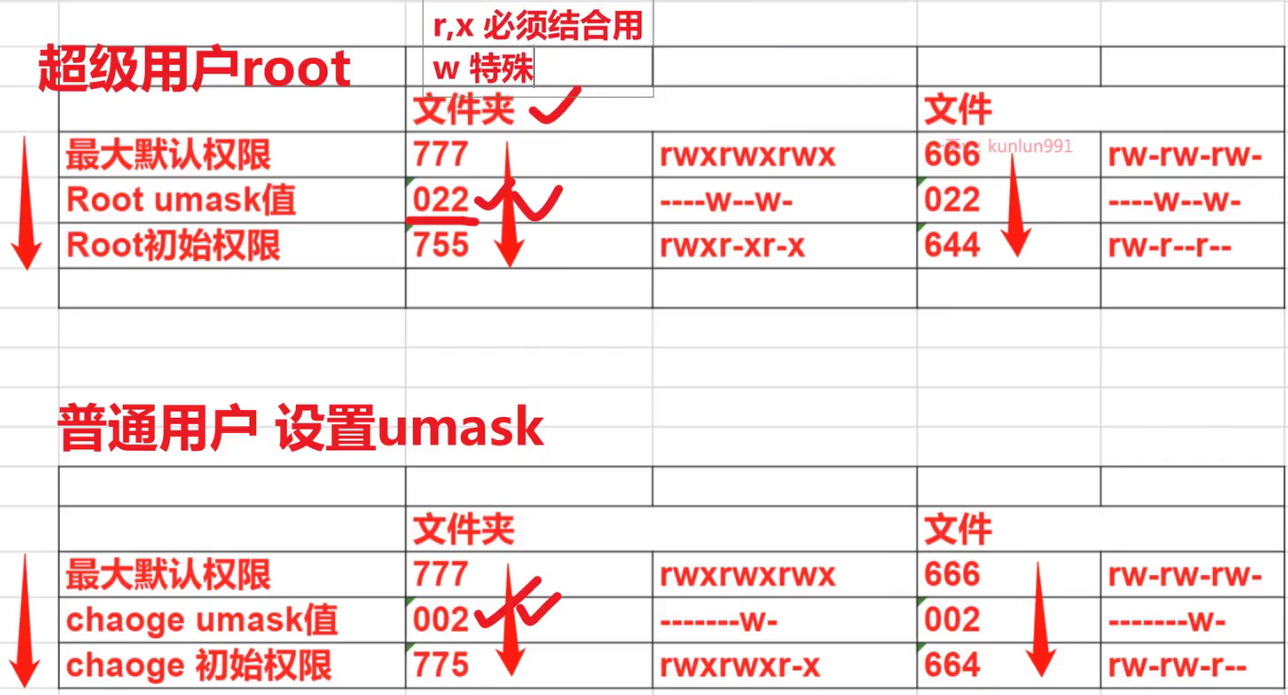
umask
umask的作用
umask 命令是用来限制新文件权限的掩码,也称之为遮罩码。
防止文件、文件夹创建的时候权限过大
当新文件被创建时,其最初的权限由文件创建掩码决定
用户每次注册进入系统时,umask命令都被执行,并自动设置掩码改变默认值,新的权限将会把旧的覆盖。
root用户和普通用户的,umask值不一样,创建文件的权限也不一样。
如何使⽤umask
Linux用户默认创建文件/文件夹的初始权限=默认最高权限-umask (文件默认没有x权限,其默认最大权限为666,若遮罩码设置为奇数,会自动+1变成偶数)
如何修改umask
# 临时修改
[root@localhost tmp]# umask 011
[root@localhost tmp]# touch test-umask.txt
[root@localhost tmp]# ll test-umask.txt
-rw-rw-rw-. 1 root root 0 Mar 17 18:41 test-umask.txt
# 永久修改(数据写入文件,每次开机都会加载)
将'umask 033'写入用户环境变量文件 ~/.bashrc重新登录会话,检查umask值,查看默认权限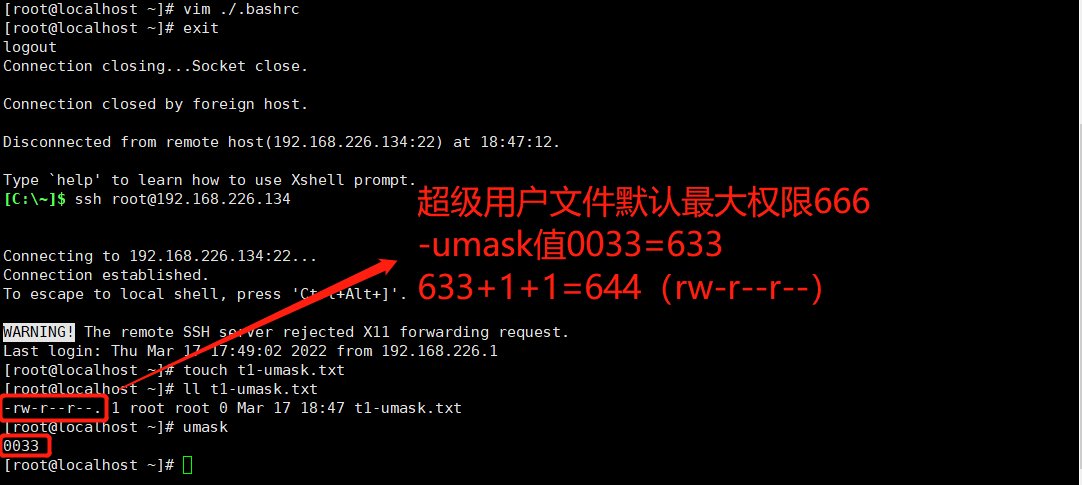
文件特殊属性
chattr修改文件特殊属性
命令说明
chattr用于改变文件的扩展属性。
chmod用于修改文件9位基础权限r、w、x
更底层的权限由chattr改变。
lsattr查看文件特殊属性
语法、参数
#参数
-a: 只能向文件中添加数据,不得删除。
-R: 递归更改目录属性。
-V: 显示命令执行过程。
#模式
+ 增加参数。
- 移除参数。
= 更新为指定参数。
A 不让系统修改文件最后访间时间。
a 只能追加文件数据,不得删除。
i 文件不能被删除、改名、修改内容。+a参数
+a(append追加)限制文件只能继续追加数据,不得删除。
#添加特殊a权限
[root@localhost opt]# touch 富婆联系方式.txt
[root@localhost opt]# chattr +a 富婆联系方式.txt
[root@localhost opt]# lsattr 富婆联系方式.txt
-----a---------- 富婆联系方式.txt
#验证
[root@localhost opt]# rm -rf 富婆联系方式.txt
rm: 无法删除"富婆联系方式.txt": 不允许的操作
[root@localhost opt]# echo "乔碧萝 TEL:114514" > 富婆联系方式.txt
-bash: 富婆联系方式.txt: 不允许的操作
[root@localhost opt]# echo "大美 TEL:110" >> 富婆联系方式.txt
[root@localhost opt]# cat 富婆联系方式.txt
大美 TEL:110
#删除特殊a权限
[root@localhost opt]# chattr -a 富婆联系方式.txt
[root@localhost opt]# lsattr 富婆联系方式.txt
---------------- 富婆联系方式.txt+i参数
+i文件不能被删除、改名、修改内容,文件被锁定。
#添加特殊i权限
[root@localhost opt]# chattr +i 富婆联系方式.txt
[root@localhost opt]# lsattr 富婆联系方式.txt
----i----------- 富婆联系方式.txt
#验证
[root@localhost opt]# rm -rf 富婆联系方式.txt
rm: 无法删除"富婆联系方式.txt": 不允许的操作
[root@localhost opt]# echo "大美 TEL:110" >> 富婆联系方式.txt
-bash: 富婆联系方式.txt: 权限不够
#删除特殊i权限
[root@localhost opt]# chattr -i 富婆联系方式.txt
[root@localhost opt]# lsattr 富婆联系方式.txt
---------------- 富婆联系方式.txt
[root@localhost opt]# ls
rh 富婆联系方式.txt
[root@localhost opt]# rm -rf 富婆联系方式.txt
[root@localhost opt]# ls
rh真实案例黑客利用特殊权限让root用户无法删除病毒文件
2019-1-21日常上班的周一
刚想学学kafka,登录与服务器看看把,谁知ssh特别慢,很奇怪,我以为是我网速问题,断了wifi,换了网线,通过iterm想要ssh root@x.x.x.x,但是上不去?
就tm的很奇怪了,登录腾讯云的webshell吧,登录上去之后,。。。。。
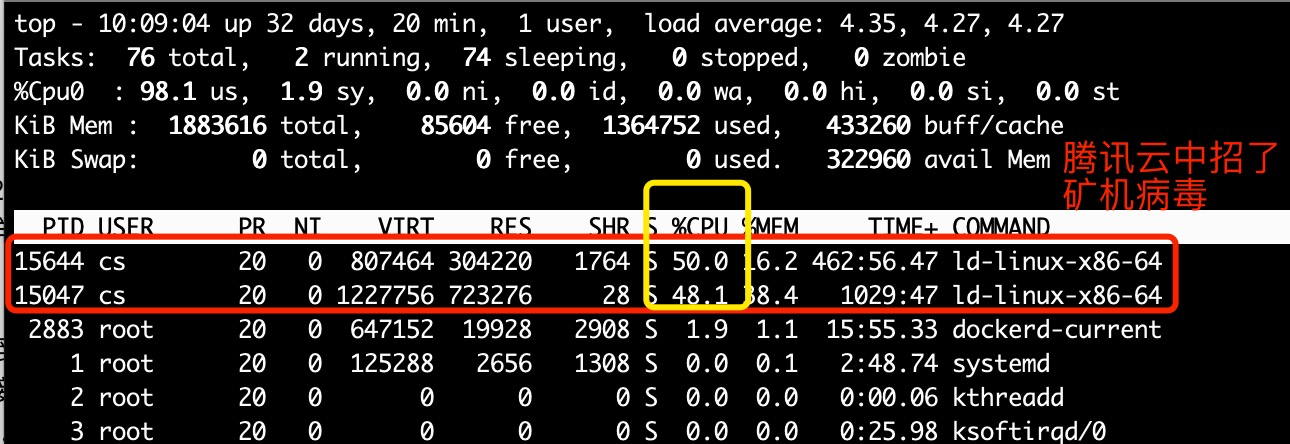
Id-linux的进程,cs用户,占了我100%的cpu,真是哔了***
解决办法
pkill -9 ld-linux 先杀死矿机进程
然后删除 cs用户
userdel -f cs
然后想要找到矿机病毒文件
find / -name ld-linux
注意!/usr/lib64/ld-linux-x86-64.so.2是linux系统文件,不能删
注意!/usr/lib64/ld-linux-x86-64.so.2是linux系统文件,不能删
注意!/usr/lib64/ld-linux-x86-64.so.2是linux系统文件,不能删
可能找到如下的东西
/tmp/.xm/stak/ld-linux-x86-64.so.2
/usr/lib64/ld-linux-x86-64.so.2 -> ld-2.17.so
/usr/share/man/man8/ld-linux.so.8.gz
/usr/share/man/man8/ld-linux.8.gz
#取消ld-linux-x86-64.so.2的特殊权限
chattr -i /tmp/.xm/stak/ld-linux-x86-64.so.2
rm -rf /tmp/.xm/stak/ld-linux-x86-64.so.2可以删除/tmp/底下的所有内容,但是其他的别动
哎,本人手残,删了库文件

系统重装了。。。。。
网络管理篇
网络命令
ip addr查看本机IP地址
查看本机ip地址
ip addr
[root@localhost ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:8b:20:7b brd ff:ff:ff:ff:ff:ff
inet 10.0.0.129/24 brd 10.0.0.255 scope global noprefixroute dynamic ens33
valid_lft 1575sec preferred_lft 1575sec
inet6 fe80::8bdd:eb1e:9914:8d8e/64 scope link noprefixroute
valid_lft forever preferred_lft forever
inet6 fe80::1b53:5dd3:4a3e:e6c5/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 52:54:00:cd:44:50 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN group default qlen 1000
link/ether 52:54:00:cd:44:50 brd ff:ff:ff:ff:ff:ff修改动态IP地址
方法一:
ifconfig [接口名/ens33] [IP地址] netmask [子网掩码/255.255.255.0]方法二:
ip addr add [IP地址/掩码(24)] dev [接口名/ens33]方法三:修改配置文件
在大多数Linux发行版中,网络配置文件位于/etc/network/interfaces或/etc/sysconfig/network-scripts/ifcfg-[接口名]目录中。要更改IP地址,可以按照以下步骤进行操作:
打开终端窗口,以root用户身份登录。
使用文本编辑器打开网络配置文件。例如,在
Ubuntu中,可以使用以下命令打开/etc/network/interfaces文件:sudo nano /etc/network/interfaces2.1.在
CentOS系统中,可以使用以下命令打开:vim /etc/sysconfig/network-scripts/ifcfg-[接口名]PS:PREFIX是掩码,16是16位(255.255.0.0),想要255.255.255.0的请用24 例子:PREFIX=24
IPADDR=172.28.28.100 # IP地址 PREFIX=16 # 掩码 GATEWAY=172.28.18.1 # 默认网关 DNS1=119.29.29.29 # DNS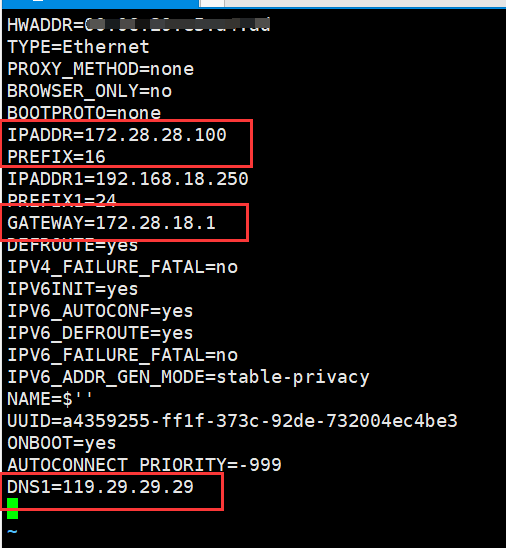
网卡配置文件内容解释
[root@localhost ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE="Ethernet" #网络类型,以太网 PROXY_METHOD="none" #代理模式 BROWSER_ONLY="no" BOOTPROTO="dhcp" #IP获取方式,dhcp动态分配,static静态IP DEFROUTE="yes" #启用默认路由 IPV4_FAILURE_FATAL="no" #关闭IPv4错误检测 IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" UUID="60ca54ad-08ce-4a73-9f30-fb0dccc196a9" DEVICE="ens33" #本机网卡名称 ONBOOT="yes" #开机是否激活网卡,为no表示不激活找到要更改IP地址的网络接口配置部分。通常,它会以"iface"开头,后面跟着接口名称(如eth0)。
在接口配置部分中,找到"address"和"netmask"行,并将其值更改为新的IP地址和子网掩码。
例如,要将eth0接口的IP地址更改为192.168.0.10,子网掩码为255.255.255.0,可以将以下行添加或修改为:
address 192.168.0.10
netmask 255.255.255.0
保存文件并关闭文本编辑器。
输入以下命令来重新启动网络服务:
service network restart修改静态IP地址
虚拟机上网流程
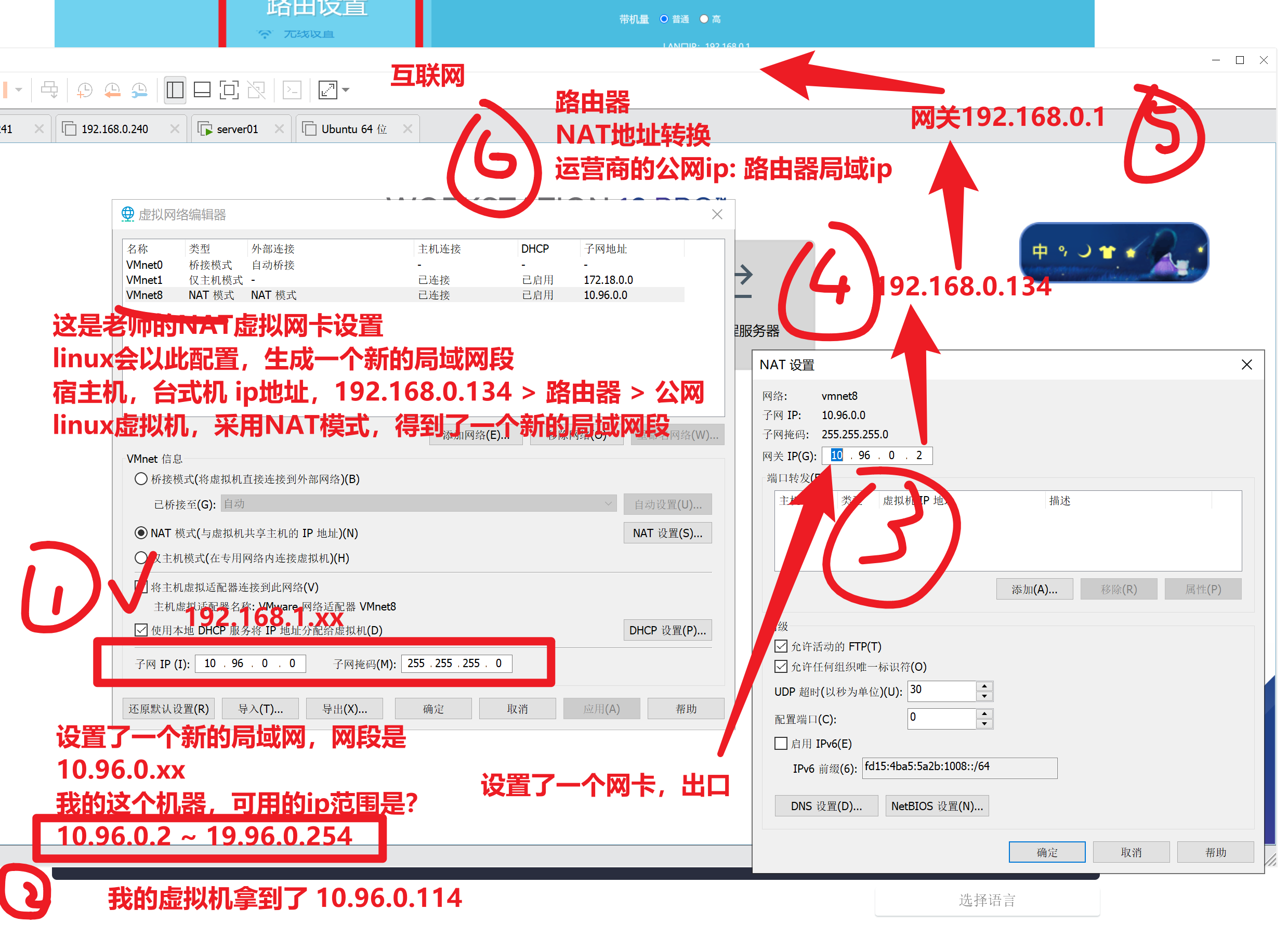
给虚拟机配置静态ip,需要根据如上配置来,找到哪些信息
确认你所在的网段环境 (10.96.0.xx)
确认网关
填写dns服务器地址
修改网卡为
static模式,添加IPADDR,GATEWAY,DNS
[root@localhost ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet" #网络类型,以太网
PROXY_METHOD="none" #代理模式
BROWSER_ONLY="no"
BOOTPROTO="static" #IP获取方式,dhcp动态分配,static静态IP
IPADDR="10.96.0.130" #静态IP地址
GATEWAY="10.96.0.2" #网关
DNS1="114.114.114.114" #主DNS解析地址
DNS2="223.5.5.5" #备用DNS解析地址
DEFROUTE="yes" #启用默认路由
IPV4_FAILURE_FATAL="no" #关闭IPv4错误检测
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="60ca54ad-08ce-4a73-9f30-fb0dccc196a9"
DEVICE="ens33" #本机网卡名称
ONBOOT="yes" #开机是否激活网卡,为no表示不激活
[root@localhost ~]# service network restartlinux网卡配置文件删掉了如何恢复?
一、解决方法
1.通过nmcli connection show 命令查看所有网络连接信息
nmcli connection show 
可以看到有个网卡的名字叫,ens33
2.重新生成网卡配置文件,命令如下:
nmcli con add con-name ens33 type ethernet ifname ens33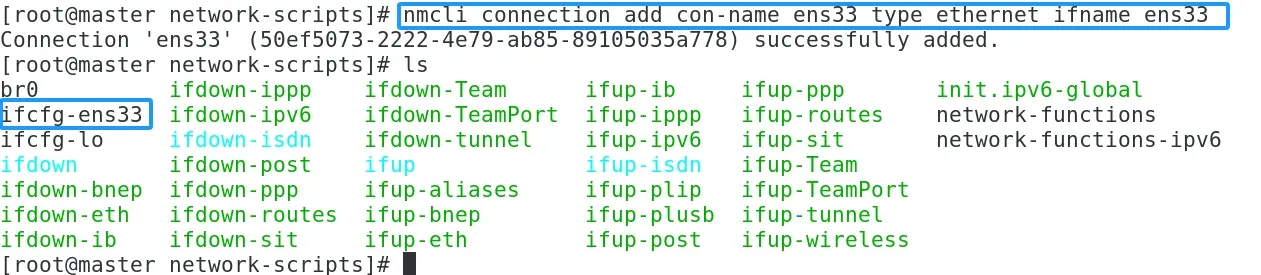
执行完命令后,通过ls命令可以看到,多了一个ifcfg-ens33的网卡配置文件。
域名
域名
域名映射 : C:\Windows\System32\drivers\etc
在windows上配置虚拟机的ip映射
C:\Windows\System32\drivers\etc\hosts
192.168.133.33 linux01
在linux上配置windows的域名映射
vi /etc/hosts
192.168.133.2 windowsnslookup域名查找
交互式
[root@yuanlai-0224 test_tar]# nslookup
> www.yuchaoit.cn
Server: 114.114.114.114
Address: 114.114.114.114#53
Non-authoritative answer:
Name: www.yuchaoit.cn
Address: 123.206.16.61非交互式
[root@yuanlai-0224 test_tar]# nslookup apecome.com
Server: 114.114.114.114
Address: 114.114.114.114#53
Non-authoritative answer:
Name: apecome.com
Address: 123.57.242.10dig
用法
dig @[DNS] [域名]
[root@yuanlai-0224 test_tar]# dig @8.8.8.8 apecome.comnetstat查看网络端口号
网络端口查看
netstat
英文:network statistics 命令路径:/bin/netstat 执行权限:所有用户
作用:主要用于检测主机的网络配置和状况
-a all显示所有连接和监听端口
-t (tcp)仅显示tcp相关连接
-u (udp)仅显示udp相关连接
-n 使用数字方式显示地址和端口号
-l (listening) 显示监控中的服务器的socket
-p port
-- 执行命令
[root@linux01 ~]# netstat -nltp | grep 3306
tcp6 0 0 :::3306 :::* LISTEN 1748/mysqld
[root@linux01 ~]# service mysqld stop
Redirecting to /bin/systemctl stop mysqld.service
[root@linux01 ~]# netstat -nltp | grep 3306
查看系统上所有端口信息↓
[root@linux01 ~]# netstat -tunlp
注意:如果netstat命令报错 notfound 下载安装
-- 安装网络工具
yum -y install net-tools ss命令
用法和netstat一模一样
ss -tunlp |grep nginx在高并发场景下,也就是机器的链接数特别多的时候,使用ss性能比netstat更高一些。
DNS
CensOS的DNS域名解析文件目录: "/etc/resolv.conf"
cat /etc/resolv.conf ← Linux系统DNS配置文件
[root@root ~]# cat /etc/resolv.conf
# Generated by NetworkManager
search localdomain
nameserver 10.0.0.2
公网DNS列举
114.114.114.114
223.5.5.5 #阿里DNS解析DNS劫持原理
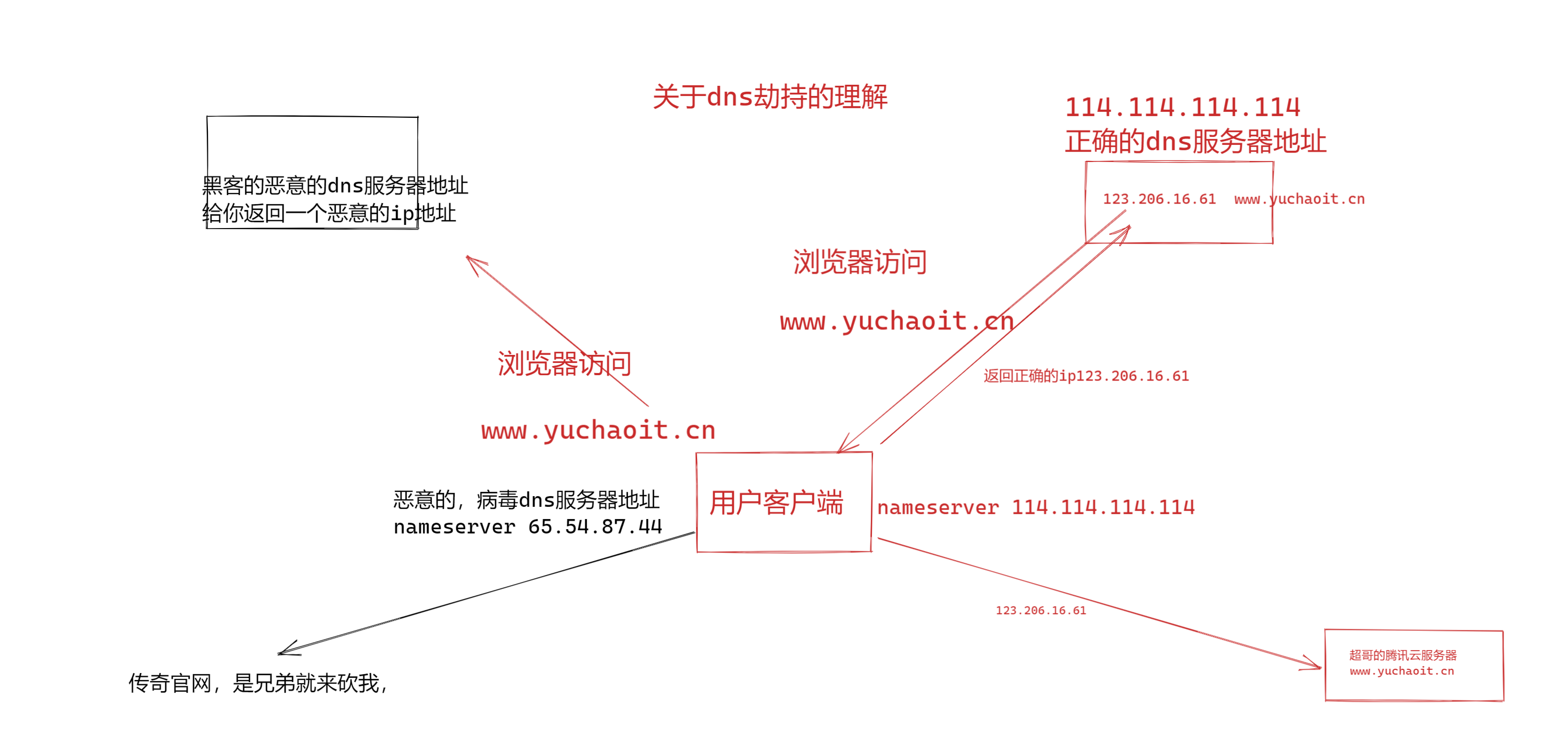
黑客攻击劫持你的DNS方式
1.关闭你本地的公网dns服务器设置
2.修改hosts文件(Windows本地hosts文件路径>>C:\Windows\System32\drivers\etc\host)
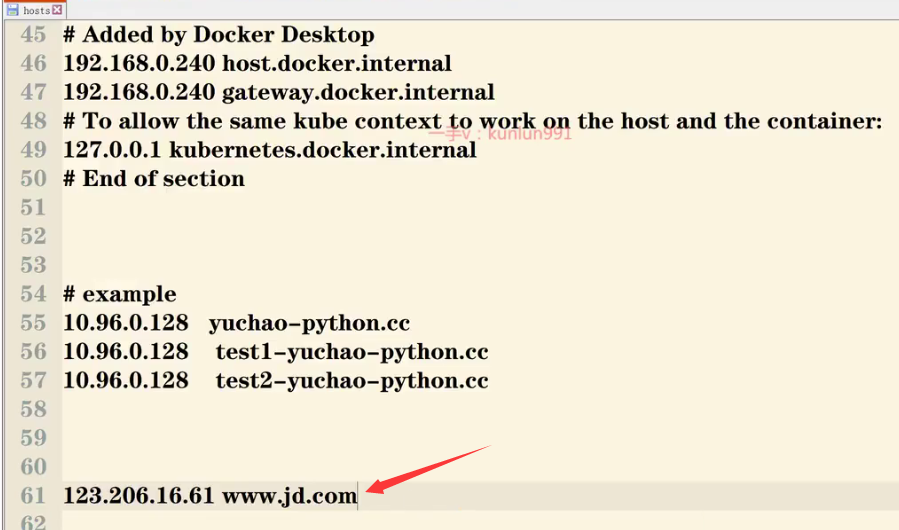
网站IP地址与域名要一一对应。
解决方法
1.去掉hosts里的恶意解析
2.配置正确的dns地址
Windows:
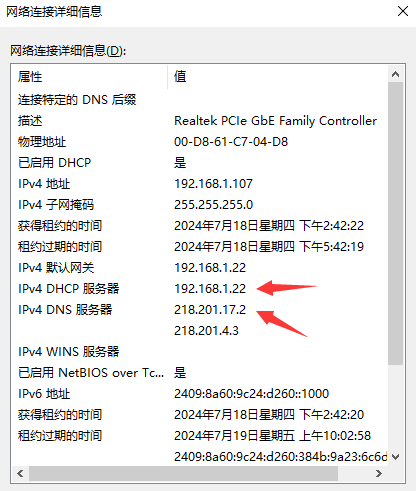
Linux:
/etc/resolv.conf3.涉及你本地机器,会有dns解析缓存,使用命令强制刷新
关于/etc/hosts文件
systemctl服务管理
centos7,用这个命令,同时对服务进行启停管理,以及开机自启
systemctl start/stop/restart/reload/enable/disable/is-enabled [服务的名]
这个命令属于对centos6提供的2个命令,做了一个整合
service
这个命令,linux的命令,大多数都是去机器上找到某个文件,然后读取文件配置,加载功能
service旧的命令,是默认去 /etc/init.d/目录下寻找(服务管理脚本文件)
然后根据你的指令 service start/stop network (/etc/init.d/network)
service [服务名] [启停指令]
然后会去读取 /etc/init.d目录下的脚本
我们在用centos6的时候,自己安装了某软件,比如nginx网站,但是没有方便的启停管理脚本
自己写nginx启停脚本,然后放到/etc/init.d/nginx
然后就可以调用
serivce nginx start
chkconfig
两个命令整合了
现在,都用这个指令了更方便,强大
# 这个命令是去
systemctl [启停指令] [服务名] 查找服务
[root@server ~]# systemctl list-units实例
查找防火墙服务是否运行
[root@server ~]# systemctl list-units |grep fire
firewalld.service loaded active running firewalld - dynamic firewall daemon
# 这个命令,其实是找到一个服务脚本文件
systemctl status firewalld.service
# 这个firewalld.service文件在哪?
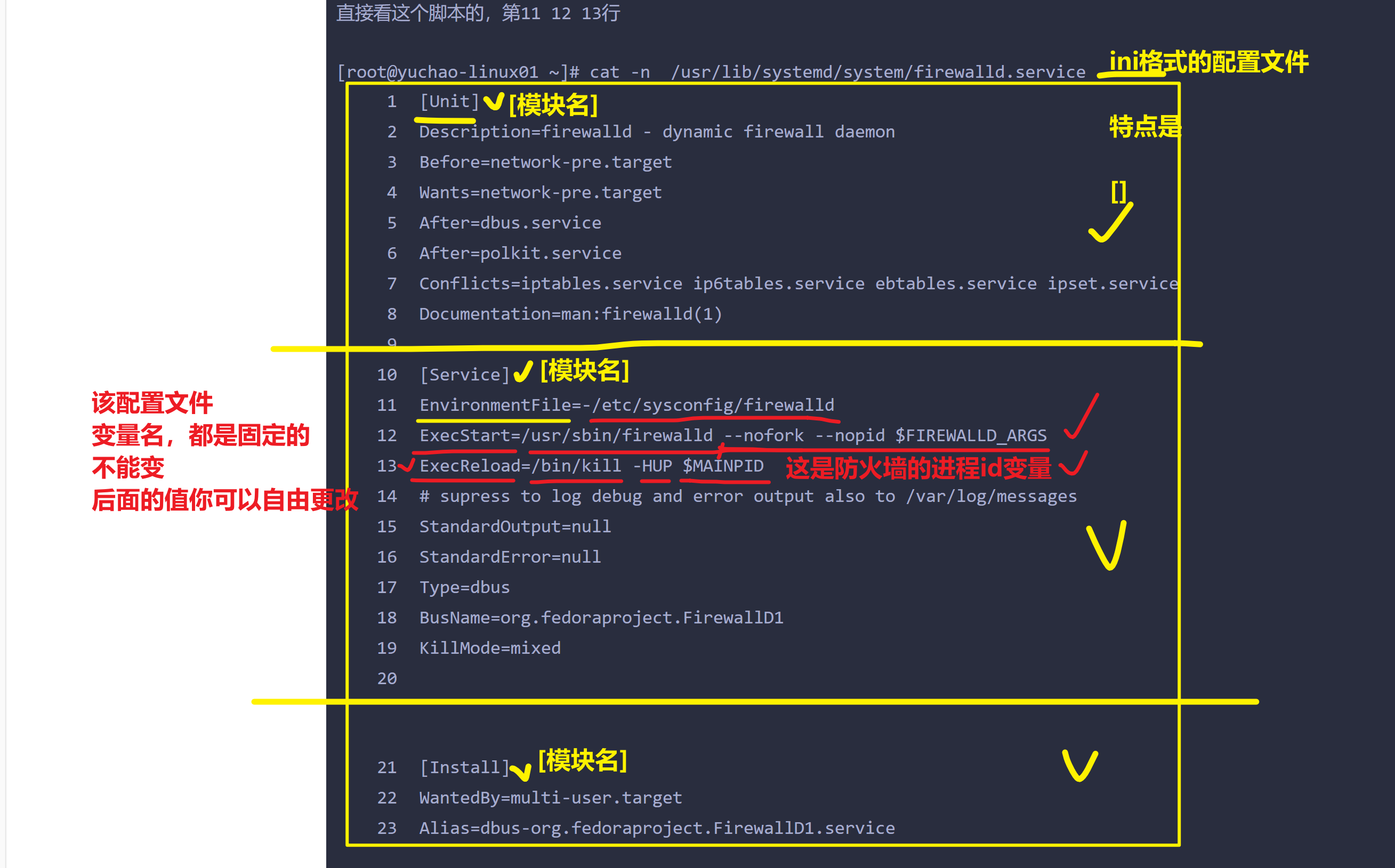
[root@yuchao-linux01 ~]# find / -type f -name 'firewalld.service'
/usr/lib/systemd/system/firewalld.service
这个脚本,其实就是执行了运行防火墙命令的一个脚本文件
直接看这个脚本的,第11 12 13行
[root@yuchao-linux01 ~]# cat -n /usr/lib/systemd/system/firewalld.service
11 EnvironmentFile=-/etc/sysconfig/firewalld
12 ExecStart=/usr/sbin/firewalld --nofork --nopid $FIREWALLD_ARGS
13 ExecReload=/bin/kill -HUP $MAINPID解释服务管理脚本的作用
其实就是帮你执行了软件提供的二进制命令
firewalld如此 /usr/sbin/fireawlld
nginx也如此 /usr/sbin/nginx
其他软件也都是这样
网络服务network
-- service [服务名] [start|stop|restart|reload|status|enable|is-enable]
service network start 启动网络服务
service network stop 关闭网络服务
service network restart 重启网络服务
service network reload 重新加载网络服务
service network status 显示网络服务状态
service network enable 开机自启网络服务(持久化)
service network is-enable 查询是否持久化(开机自启)
-- systemctl [status|stop|start|restart|disable|enable] [服务名]
systemctl status network 查看网络管理状态
systemctl stop network 关闭网络管理服务
systemctl start network 启用网络管理服务
systemctl restart network 重启网络管理服务
systemctl disable network 开机禁用网络管理服务
systemctl enable network 开机启动网络管理服务
systemctl is-enable 查看是否持久化(是否开机自启)
-- 关闭NetworkManager网络管理服务 避免和network冲突
systemctl status NetworkManager
systemctl stop NetworkManager
systemctl disable NetworkManager
systemctl is-enable NetworkManager #查看是否开机自启图形化网络服务。
[root@localhost ~]# systemctl is-enabled NetworkManager
disabled防火墙服务firewalld
[root@localhost ~]# systemctl status firewalld
Active: active (running) since Fri 2021-10-08 23:02:24 CST; 10h ago -- 防火墙在运行
systemctl start firewalld
systemctl stop firewalld 关闭防火墙
systemctl restart firewalld
systemctl disable firewalld 配置开启禁用
systemctl enable firewalld 开机关闭
systemctl status firewalld 查看防火墙服务状态
如果报错 重新安装防火墙 yum -y install firewalld.service
关闭服务器的防火墙
[root@localhost ~]# iptables -F
关闭系统默认防火墙
[root@localhost ~]# setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config防火墙的概念
区域
Cent0s6x中防火场叫做iptables CentOS7.x中默认使用的防火墙是firewalld,但是依然更多的是使用iptables,firewalld默认都关了。 friewalld增加了区域的概念,所谓区域是指,firewalld预先准备了几套防火墙策略的集合,类似于策略的模板,用户可以根据需求选择区域。
常见区域及相应策略规则
运行模式和永久模式
运行模式:此模式下,配置的防火墙策略立即生效,但是不写入配置文件 永久模式:此模式下,配置的防火墙策略写入配置文件,但是需要reload重新加载才能生效。 frewall默认采用运行模式
解释永久生效的概念

firewalld-cmd
立即生效,服务器,立马放行这个端口
添加一个http服务等于,允许客户端,去访问这个机器的80端口
弊端是,firewalld重启后,该配置丢失(这个配置,是临时生效,没有写入到文件
非立即生效
(命令执行完了,不会立即看到效果),但是永久生效(你的操作,被记录到了一个配置文件中,每次重启firewalld服务,都会再次读取这个文件,以实现永久生效)
实践
给机器,放行http服务(80端口)
立即生效,重启firewalld后丢失
firewall-cmd --zone=区域名
指定用哪个区域,默认是public区域(默认放开了ssh端口)
firewall-cmd --list-all
查看当前区域下的具体配置规则
[root@server ~]# firewall-cmd --zone=public --add-service=http
success
给public区域立即生效,打开一个http服务
systemctl restart firewalld
1.服务的运行 2.必然会去读取一个默认的配置文件,以文件中的内容,重新再运行该服务
读取文件在哪?
xml 和ini 和yaml是以后运维生涯中的 三大配置文件格式
cat /etc/firewalld/zones/public.xml
这个文件就是firewalld服务,每次重启读取的文件
想要永久生效,你得保证这个文件中存在你的服务
非立即生效,
需要重载(重新读取cat /etc/firewalld/zones/public.xml)后生效,以及重启firewalld,服务也不丢失
--permanent
有了这个参数,配置就会被记录到该文件中
firewall-cmd--permanent --add-service=http
当前不会立即生效
查看配置文件,是否写入了信息
需要重启,重载服务后,生效
systemctl restart firewalld
阻塞动作,和上面是一个概念
永久生效
非永久生效
区别在于,是否添加参数,--permanent
需要你去检查配置文件中,是否有信息
firewalld防火墙的配置
管理firewall配置
命令:firewall-cmd
作用:管理firewall具体配置
语法:firewall-cmd [参数选项1]...[参数选项n]
常用选项:
查看当前使用的区域是哪一个
[root@server ~]# firewall-cmd --get-default-zone
public查看所有可用的区域
[root@server ~]# firewall-cmd --get-zones
block dmz drop external home internal public trusted work列出当前使用区域配置
[root@server ~]# firewall-cmd --list-all
public
target: default
icmp-block-inversion: no
interfaces:
sources:
services: dhcpv6-client ssh
ports:
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules: 列出所有区域的配置信息
[root@server ~]# firewall-cmd --list-all-zones查看端口状态
对于使用
iptables的系统:
sudo iptables -L -n | grep 端口号对于使用
firewalld的系统:
sudo firewall-cmd --list-ports | grep 端口号放行端口
用法
对于iptables,可以使用以下命令来放行一个特定端口:
sudo iptables -A INPUT -p tcp --dport 端号 -j ACCEPT请将"端口号”替换为要放行的端口号。此命令将添加一个规则来放行任何TCP连接通过指定的端口。如果您还希望放行UDP连接,请将-p tcp更改为-p udp
对于firewalld,可以使用以下命令来放行一个特定端口:
sudo firewall-cmd --permanent --add-port=端口号/tcp
sudo firewall-cmd --reload同样,请将“端口号”替换为要放行的端口号。此命令将从系统的防火墙规则中添加指定端口的访问权限。
实例:
放行UDP端口123的开放设置。添加相应的规则来允许NTP流量通过。
对于iptables,添加规则的示例:
sudo iptables -I INPUT -p udp --dport 123 -j ACCEPT对于firewalld,添加规则的示例:
sudo firewall-cmd --permanent --add-port=123/udp
sudo firewall-cmd --reload阻塞端口
种常见的方式来关闭端口是通过配置防火墙,[inux系统中最常用的防火墙工具是iptables和frewald。根据您使用的Lnux发行版的不同,可以选择使用其中一种或两种 防火墙工具。
在关闭端口之前,首先需要确定要关闭的特定端口。可以通过使用以下命令来查看当前打开的端口:
sudo netstat -tuln通过执行上述命令,系统将返回当前所有开放的端口及其状态。仔细检查列表,找出需要关闭的端口。值得注意的是,在确定要关闭的端口之前,请确保您已经了解该端口所提供的服务和其关闭可能导致的影响。
用法
对于iptables,可以使用以下命令来关闭一个特定端口:
sudo iptables -A INPUT -p tcp --dport 端号 -j DROP请将"端口号”替换为要关闭的端口号。此命令将添加一个规则来禁止任何TCP连接通过指定的端口。如果您还希望禁止UDP连接,请将-p tcp更改为-p udp
对于firewalld,可以使用以下命令来关闭一个特定端口:
sudo firewall-cmd --zone=public --remove-port=端口号/tcp同样,请将“端口号”替换为要关闭的端口号。此命令将从系统的防火墙规则中删除指定端口的访问权限。
实例
例题一:Linux防火墙阻塞NTP服务端口:udp 123命令
在Linux系统中,可以使用iptables命令来阻止对NTP服务端口123的访问。以下是一个示例命令,它将阻止所有到达端口123的UDP流量:
sudo iptables -A INPUT -p udp --dport 123 -j REJECT/DROP这条命令的含义是:
iptables: 这是操作Linux防火墙的命令。-A INPUT: 添加一条规则到输入链。-p udp: 指定协议为UDP。--
--dport 123: 指定目标端口为123。-j REJECT: 拒绝匹配的流量,并返回一个拒绝的响应。
请确保你有足够的权限来执行这个命令,通常需要root权限。执行后,任何尝试通过UDP端口123访问服务器的NTP请求都会被拒绝。
例题二:添加允许通过的服务或端口(Python,ntp)
你的Linux机器,当前使用的是public区域的规则
默认信任的服务是。ssh,dhcp
准备一个web服务,通过Python提供的简单命令。

1,先运行一个80端口的服务
python -m SimpleHTTPServer 802,给当前的防火墙区域,添加一个策略,允许80端口通过
[root@server ~]# firewall-cmd --add-port=80/tcp
success
[root@server ~]# firewall-cmd --list-all
public
target: default
icmp-block-inversion: no
interfaces:
sources:
services: dhcpv6-client ssh
ports: 80/tcp 8000/tcp
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules: 
3.再添加一个8000端口的规则,我们接触的绝大多数,都是端口号/tcp 这个即可.
[root@server ~]# firewall-cmd --add-port=8000/tcp
success4.删除,添加的端口规则
[root@server ~]# firewall-cmd --remove-port=80/tcp
success
[root@server ~]# firewall-cmd --list-all
public
target: default
icmp-block-inversion: no
interfaces:
sources:
services: dhcpv6-client ssh
ports: 8000/tcp
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules: 5.针对服务名添加,比如ntp服务
[root@server ~]# firewall-cmd --add-service=ntp
success
[root@server ~]# firewall-cmd --list-all
public
target: default
icmp-block-inversion: no
interfaces:
sources:
services: dhcpv6-client ntp ssh
ports: 80/tcp
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
删除ntp服务
[root@server ~]# firewall-cmd --remove-service=ntp
success6.firewalld,作用其实是添加iptables的规则
#查看系统上所有iptables的命令
iptables -Ltcp 是一个安全可靠的连接,需要双向确认,客户端,和服务端,都要确认对方以及连接上了。
udp 是一个不可靠的额连接协议,客户端可以随便给服务端发,不需要对方确认。
比如一个很差的网络环境下,网页无法访问,无法做dns解析(网络服务,网站服务,用的都是tcp协议) 但是qq可以收发消息(qq用的是udp协议,以及ntp用的也是udp协议)
#查看到firewalld命令,添加的防火墙规则如下
[root@yuchao-linux01 ~]# iptables -L |grep ntp
ACCEPT udp -- anywhere anywhere udp dpt:ntp ctstate NEW7.清空防火墙规则
iptables -F远程登录服务sshd
#1. ssh服务
[root@localhost ~]# netstat -tnlp | grep sshd
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1116/sshd
tcp6 0 0 :::22 :::* LISTEN 1116/sshd
#2. 我可以自由启动,关闭,重启该服务,查看效果
#3. 学习centos7,启动的强大,服务管理命令
systemctl stop sshd 停止ssh服务
systemctl status sshd 查看ssh服务状态
systemctl start sshd 启动ssh服务
systemctl restart sshd 重启ssh服务
#4. sshd服务,运行后,即可去访问该服务时间同步服务ntp
NTP是网络时间协议(Network Time Protocol)它是用来同步网络中各个计算机的时间的协议在计算机的世里,时间非常地重要
例如:对于火箭发射这种科研活动,对时间的统一性和准确性要求就非常地高,是按照A这台计算机的时间,还是按照B这台计算机的时间?
NTP就是用来解决这个问题的,NTP (NetworkTime Protocol),网络时间协议)是用来使网络中的各个计算机时间同步的一种协议。
它的用途是把计算机的时钟同步到世界协调时UTC,其精度在局域网内可达0.1ms,在互联网上绝大多数的地方其精度可以达到1-50ms。
工作场景:
公司开发了一个电商网站,由于访问量很大,网站后端由100台服务器组成集群。 50台负责接收订单,50台负责安排发货,接收订单的服务器需要记录用户下订单的具体时间,把数据传给负 责发货的服务器,由于100台服务器时间各不相同,记录的时间经常不一致,甚至会出现下单时间是明天发货时间是昨天的情况。
时间是很重要的一个单位概念,很多新手、老手,都可能在时间同步服务上翻车,很多服务部署,因为时间的不同步,都会导致出错,增加排错难度。 特别是在集群下,多台服务器,需要部署联调,由于时间不正确,可能导致通信异常。 需要时间的应用。
定时任务的执行
数据同步,时间不一致等。
因此保证服务器之间的时间一致,非常重要。
1)NTP同步服务器原理
标准时间是哪里来的? 现在的标准时间是由原子钟报时的国际标准时间UTC(Universal Time Coordinated,世界协调时),所以NTP获得UTC的时间来源可以是原子钟、天文台、卫星,也可以从Internet上获取。 在NTP中,定义了时间按照服务器的等级传播,Stratum层的总数限制在15以内工作中,通常我们会直接使用各个组织提供的,现成的NTP服务器。
2)到哪里去找NTP服务器
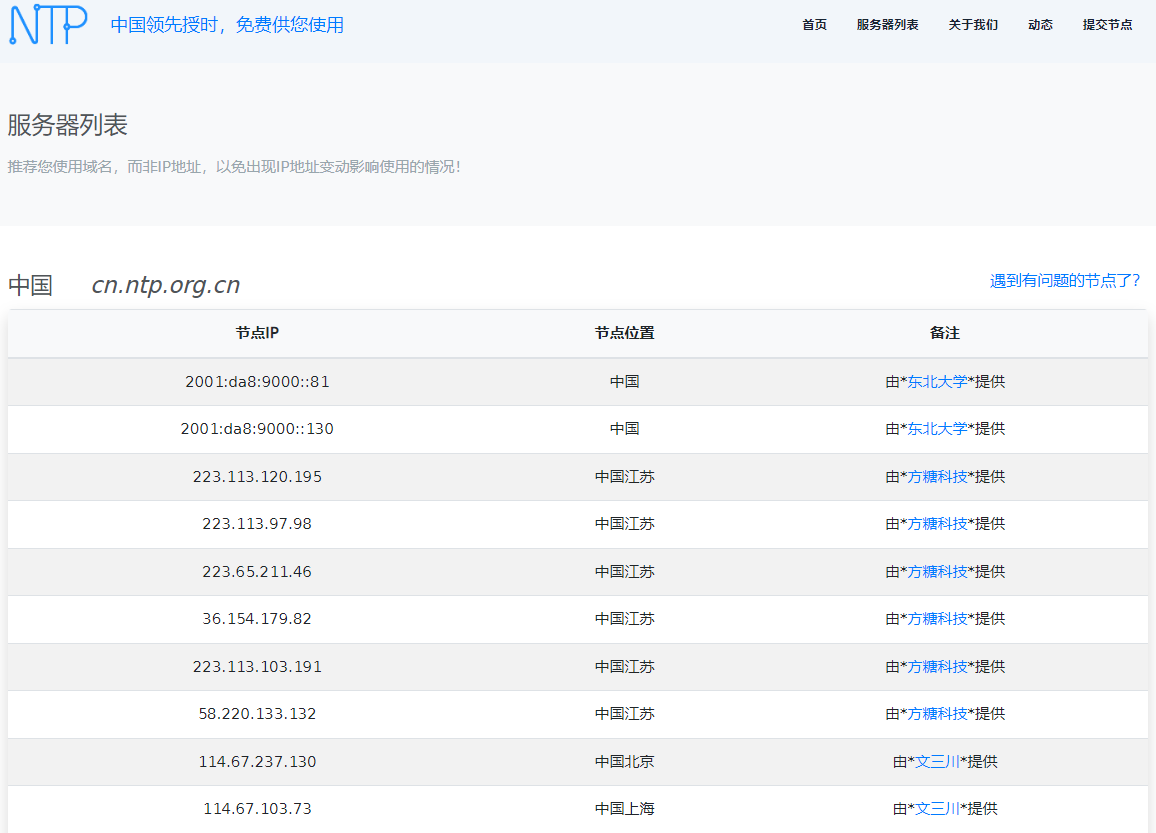
NTP授时网站:http://www.ntp.org.cn/pool
hwclock命令
hwclock命令用于显示与设定硬件时钟。
在Linux中有硬件时钟与系统时钟等两种时钟。硬件时钟是指主机板上的时钟设备,也就是通常可在BIOS画面设定的时钟。系统时钟则是指kernel中的时钟。当Linux启动时,系统时钟会去读取硬件时钟的设定,之后系统时钟即独立运作。所有Linux相关指令与函数都是读取系统时钟的设定。
用法
[root@server ~]# hwclock
2018年11月08日 星期四 10时05分32秒 -0.346864 秒
[root@server ~]# hwclock -v
hwclock from util-linux-2.12adate命令
date 命令可以用来显示或设定系统的日期与时间。
用法
[root@server ~]# date
2024年 08月 19日 星期一 16:49:41 CSTtimedatectl命令
timedatectl(英文全拼:timedate control)命令用于在 Linux 中设置或查询系统时间、日期和时区等配置
centos7,cetnso6
systemctl
service
chkconfig
在centos7提供了更强大的timedatectl命令,整合了时、时区操作。
timedatectl
date 改时间日期(软件时间,你的系统运行了,程序计算的时间)
[root@server ~]# date
2024年 08月 19日 星期一 16:49:41 CST
hwclock 改硬件时间(计算的主板上,有一个BISO系统,以及纽扣电池,提供电量)
[root@server ~]# hwclock
2018年11月08日 星期四 10时05分32秒 -0.346864 秒
centos6时代,修改系统的时区、时间,需要用到
修改时间、日期、date命令
#centos6的修改时区的操作,时区就以亚洲上海为准了
修改时区,cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# 查看系统中有哪些时区文件
ls /usr/share/zoneinfo/
ll /usr/share/zoneinfo/Asia/Shanghai
修改硬件时间、hwclock命令在 Linux 运维中,通常使用此命令来设置或更改当前的日期、时间和时区,或启用自动系统时钟与远程 NTP服务器同步,以确保 Linux 系统始终保持正确的时间。
语法
timedatectl [OPTIONS ...] COMMAND ...
命令COMMAND
status : 显示当前的时间设置。
show : 显示systemd-timedated的性。
set-time TIME : 设置系统时间。
set-timezone ZONE : 设置系统时区。
1ist-timezones : 显示已知时区。
set-local-rtc BOOL : 控制RTC是否在当地时间。(BOOL的值可以是1/true或/false)
set-ntp BOOL : 启用或禁用网络时间同步。(BOOL的值可以是1/true或/false)
timesync-status : 显示systemd-timesyncd的状态。
show-timesync : 显示systemd-timesyncd的属性。
选项OPTIONS
-h,--help : 显示帮助信息。
--version : 显示软件包版本。
--no-pager : 不用将输出通过管道传输到寻呼机(pager)。
--no-ask-password : 不提示输入常码。
-H,--host=[USER@]HOST : 在远程主机上操作。
-M,--machine=CONTAINER : 在本地容器上操作。
--adjust-system-clock : 更改本地RTC模式时调整系统时钟。
--monitor : 监控systemd-timesyncd 的状态。
-P,--property=NAME : 仅显示此名称的属性。
-a,--a11 : 显示所有属性,包括空属性。
--value : 显示属性时,只打印值。timedatectl实例
显示当前系统时间、日期 世界时间查询,http://www.stl56.com/shicha/
查看时间
[root@server ~]# timedatectl status
Local time: Mon 2024-08-19 16:01:16 CST
Universal time: Mon 2024-08-19 08:01:16 UTC
RTC time: Mon 2024-08-19 08:01:17
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: no
NTP synchronized: no
RTC in local TZ: no
DST active: n/a
解释:
当地时间
世界时间
RTC时间,本地硬件时钟(主板上的绍扣电池供电,提供机器的时间正确,在主板的集成电路上)默认以UTC为准了
时区,亚洲上海
是否启用NTP
NTP国步状态
本地时区的RTC
DST是否激活
CST解释
CST(北京时间)
北京时间,China standard Time,中国标准时间。
在时区划分上,属东八区,比协调世界时早8小时,记为UTC+8。
UTC
UTC(世界标准时间)
协调世界时,又称世界标准时间或世界协调时间,简称UTC(从英文“CoordinatedUniversal Time”)
整个地球分为二十四时区,每个时区都有自己的本地时间,在国际无线电通信场合,为了统一起见,使用一个统一的时间,称为
GMT
格林威治标准时间指位于英国伦敦郊区的皇家格林尼治天文台的标准时问,因为本初子午线被定义在通过那里的经线(UTC与GMT)
DST
夏令时指在复天太阳升起的比较早时,将时间拨快一小时,以提早日光的使用,中国不使用。列出机器上支持的所有时区
[root@server ~]# timedatectl list-timezones
Africa/Abidjan
Africa/Accra
Africa/Addis_Ababa
Africa/Algiers
...
[root@server ~]# timedatectl list-timezones | wc -l
419
#可以看到该系统支持419个时区。修改时区为America/Belem
[root@server ~]# timedatectl set-timezone America/Belem
[root@server ~]# timedatectl status
Local time: Mon 2024-08-19 05:13:54 -03
Universal time: Mon 2024-08-19 08:13:54 UTC
RTC time: Mon 2024-08-19 08:13:55
Time zone: America/Belem (-03, -0300)
NTP enabled: no
NTP synchronized: no
RTC in local TZ: no
DST active: n/a修改时间
[root@server ~]# timedatectl set-time '2018-11-8 10:00'
[root@server ~]# timedatectl status
Local time: Mon 2018-11-08 10:00:54 CST
Universal time: Mon 2018-11-08 10:00:54 UTC
RTC time: Mon 2018-11-08 10:00:55
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: no
NTP synchronized: no
RTC in local TZ: no
DST active: n/a开启上游机器的npt服务
[root@server ~]# timedatectl set-ntp on
[root@server ~]# timedatectl
Local time: 一 2024-08-19 17:40:12 CST
Universal time: 一 2024-08-19 09:40:12 UTC
RTC time: 一 2024-08-19 09:40:13
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: yes
NTP synchronized: yes
RTC in local TZ: no
DST active: n/a操作到这里,你的时间可能已经乱了。。怎么办? 向下继续看教程啊怎么办!
时间同步操作
机器时间错乱后,可以进行
时间同步,搭建ntpd服务(推荐)
时间校准,ntpdate命令(不推荐)
同步服务器时间方式有2 个:一次性同步手动同步、通过服务自动同步。
时间同步注意点(生产经验的坑)
ntpd在实际同步时间时是一点点的校准过来时间的,最终把时间慢慢的校正对 而ntpdate不会考虑其他程序是否会占用,直接调整时间。一个是校准时间,一个是调整时间。 因为许多应用程序依赖连续的时钟,而使用ntpdate这样的时钟跃变,有时候会导致很严重的问题,如数据 库事务操作等。
并且,还有如下缺陷:
安全问题
ntpdate的设置依赖于ntp服务器的安全性,攻击者可以利用一些软件设计上的缺陷,拿下ntp服务器并令与其同步的服务器执行某些消耗性的任务。
太过于暴力
ntpdate是急变,是立即修改系统时间,非常依赖于时序的程序可能会出错,比如根据时间执行备份动作的脚本,或者一些监控程序。
因此,企业服务器里一般会部署ntpd服务,让服务器自动、定期的进行时间同步,且以公共时间服务器池为准,保证服务器集群的时间正确且一致。
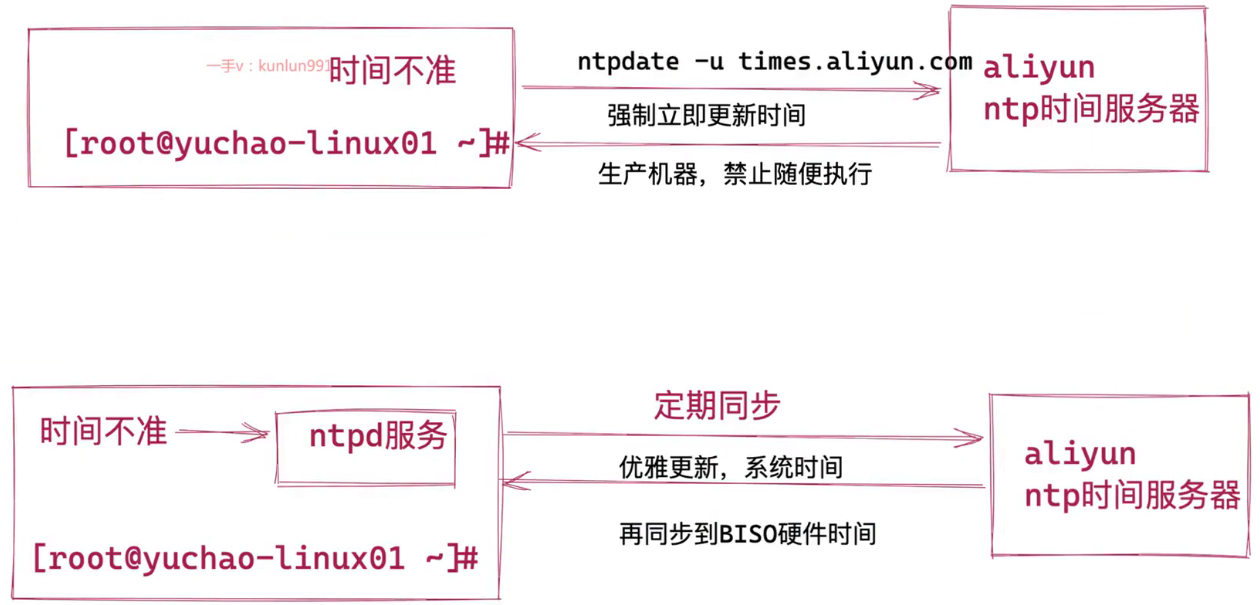
强制性ntpdate命令
[root@server ~]# ntpdate -u ntp.aliyun.com搭建ntpd服务
所有linux的软件,用法都一样
安装
改配置
启动
使用
以后,就是继续改配置,重新加载,重启
继续使用
查看是否安装ntp
rpm -qa | grep ntp
1.安装ntp软件
yum install ntp -y
2.查看ntp软件信息
[root@server ~]# ls /usr/lib/systemd/system/ |grep ntp
ntpdate.service
ntpd.service
3.找到ntp软件的配置文件
[root@server ~]# rpm -ql ntp |grep conf
/etc/ntp.conf
/etc/sysconfig/ntpd
/usr/share/man/man5/ntp.conf.5.gz
4.修改ntp配置文件,
vim /etc/ntp.conf, 做如下修改
#系统时间与BIOS时间的偏差记录
driftfile /var/lib/ntp/drift
# 添加ntp的运行日志
logfile /var/log/my_ntp.log
# 记录程序的运行进程号的,可以用于写脚本,读取这个文件,就找到了程序的进程id
pidfile /var/run/ntpd.pid
# Permit time synchronization with our time source, but do not
# permit the source to query or modify the service on this system.
restrict default nomodify notrap nopeer noquery
# Permit all access over the loopback interface. This could
# be tightened as well, but to do so would effect some of
# the administrative functions.
restrict 127.0.0.1
restrict ::1
# Hosts on local network are less restricted.
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server ntp.aliyun.com iburst prefer
server cn.pool.ntp.org iburst
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
#查看 NTP 服务端口 UDP 123 端口是否被正常监听。
[root@root yum.repos.d]# netstat -nupl
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
udp 0 0 192.168.122.1:123 0.0.0.0:* 10409/ntpd
udp 0 0 192.168.31.150:123 0.0.0.0:* 10409/ntpd
udp 0 0 127.0.0.1:123 0.0.0.0:* 10409/ntpd
udp 0 0 0.0.0.0:123 0.0.0.0:* 10409/ntpd
udp6 0 0 fe80::1b53:5dd3:4a3:123 :::* 10409/ntpd
udp6 0 0 ::1:123 :::* 10409/ntpd
udp6 0 0 :::123 :::* 10409/ntpd
5.修改机器的时间为错误时间
[root@server ~]# timedatectl set-time '2018-11-8 10:00'
6.启动ntpd服务,等待时间是否同步
关于ntpd的服务脚本文件/usr/lib/systemd/system/ntpd.service
[root@server ~]# systemctl start ntpd
[root@server ~]# systemctl status ntpd
● ntpd.service - Network Time Service
Loaded: loaded (/usr/lib/systemd/system/ntpd.service; disabled; vendor preset: disabled)
Active: active (running) since 四 2018-11-08 10:01:43 CST; 1s ago
Process: 20653 ExecStart=/usr/sbin/ntpd -u ntp:ntp $OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 20654 (ntpd)
Tasks: 1
CGroup: /system.slice/ntpd.service
└─20654 /usr/sbin/ntpd -u ntp:ntp -g
11月 08 10:01:43 yuanlai-0224 systemd[1]: Starting Network Time Service...
11月 08 10:01:43 yuanlai-0224 systemd[1]: Started Network Time Service.
11月 08 10:01:43 yuanlai-0224 ntpd[20654]: proto: precision = 0.026 usec
11月 08 10:01:43 yuanlai-0224 ntpd[20654]: 0.0.0.0 c01d 0d kern kernel time sync enabled
7.查看ntp是否和上游服务器同步
[root@server ~]# ntpstat
synchronised to NTP server (203.107.6.88) at stratum 3
time correct to within 988 ms
polling server every 64 s
8.查看时间同步的状态
[root@server ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*203.107.6.88 10.137.55.181 2 u 9 64 1 63.603 8.581 0.090
time.cloudflare .INIT. 16 u - 64 0 0.000 0.000 0.000
remote:响应这个请求的 NTP 服务器的名称。
refid:NTP 服务器使用的上一级 NTP 服务器。
st:remote 远程服务器的级别。服务器从高到低级别设定为1 - 16,为了减缓负荷和网络堵塞,原则上建议避免直接连接到级别为1的服务器。
when:上一次成功请求之后到现在的秒数。
poll:本地机和远程服务器多少时间进行一次同步(单位为秒)。初始运行 NTP 时,poll 值会比较小,和服务器同步的频率增加,建议尽快调整到正确的时间范围。调整之后,poll 值会逐渐增大,同步的频率也将会相应减小。
reach:八进制值,用来测试能否和服务器连接。每成功连接一次,reach 的值将会增加。
delay:从本地机发送同步要求到 NTP 服务器的 round trip time。
offset:主机通过 NTP 时钟同步与所同步时间源的时间偏移量,单位为毫秒(ms)。offset 越接近于0,主机和 NTP 服务器的时间越接近。
jitter:用来做统计的值。统计在特定连续的连接数里 offset 的分布情况。即 jitter 数值的绝对值越小,主机的时间就越精确。
9. 这台机器,就是一个时间服务器了,可以作为上游机器使用。
#安装ntpdate服务
yum install ntpdate -y
#启动ntpdate服务
[root@node1 yum.repos.d]# systemctl start ntpdate
#启动ntpd服务
[root@node1 yum.repos.d]# systemctl start ntpd
#修改为错误时间
[root@node1 ~]# timedatectl set-time '2018-11-8 10:00'
[root@node1 ~]# timedatectl
Local time: Thu 2018-11-08 10:00:04 CST
Universal time: Thu 2018-11-08 02:00:04 UTC
RTC time: Thu 2018-11-08 02:00:05
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: no
NTP synchronized: no
RTC in local TZ: no
DST active: n/a
[root@node1 ~]# ntpdate -u 192.168.31.125
19 Aug 20:49:32 ntpdate[15028]: adjust time server 192.168.31.125 offset -0.006382 sec
[root@node1 ~]# timedatectl
Local time: 一 2024-08-19 20:50:35 CST
Universal time: 一 2024-08-19 12:50:35 UTC
RTC time: 一 2024-08-19 12:50:34
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: no
NTP synchronized: yes
RTC in local TZ: no
DST active: n/a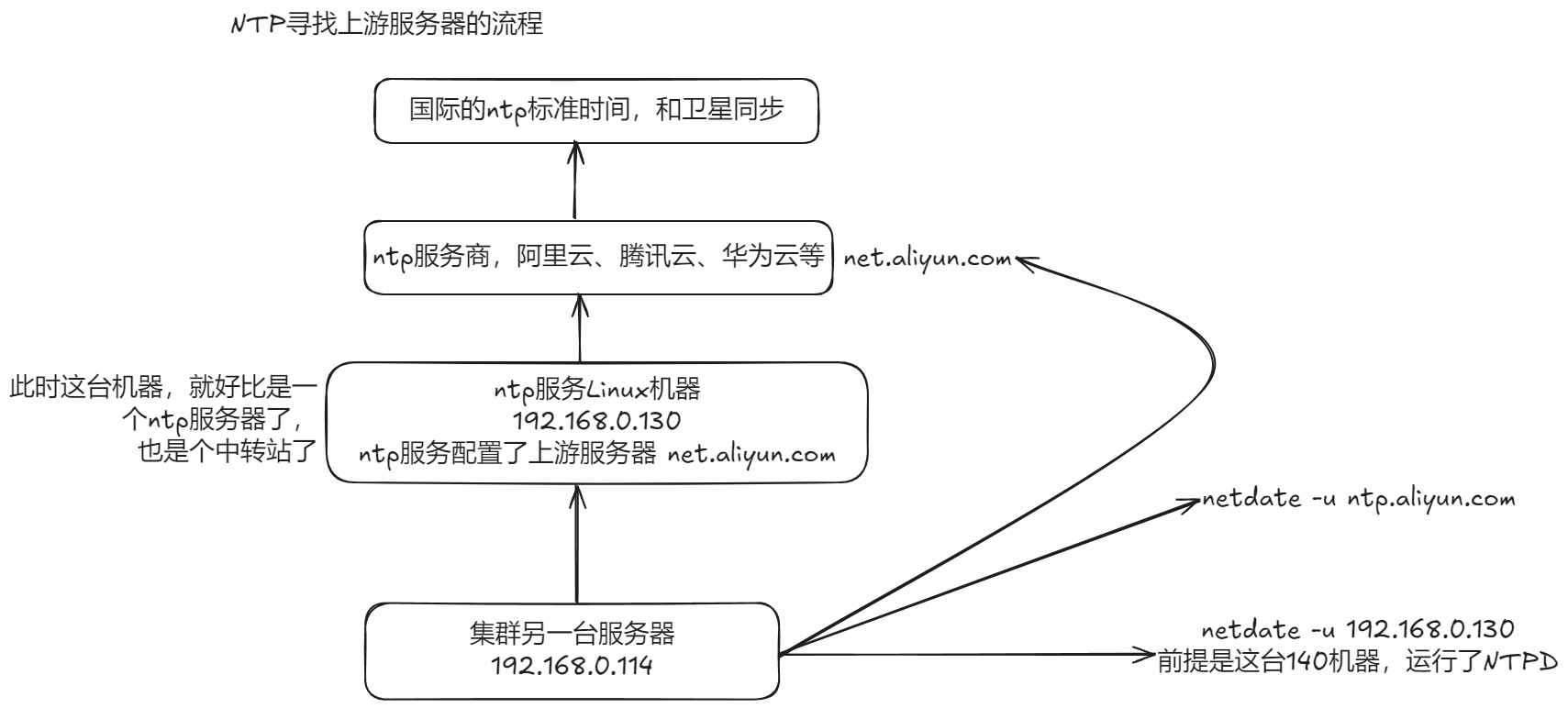
Linux软件安装篇
Linux如何下载网络资源
使用wget命令
该命令需要安装
yum install wget -y 语法
可选参数
软件包
概念
是一个将二进制命令(程序源码,经过编译后的一个单个可执行命令产物)+配置文件+数据文件,打包好的一个单个文件。
linux你会遇见的软件包格式,两种
源码包
编译型语言源码

解释型语言源码

脚本语言程序源码

二进制包
Linux的软件安装技术
centos平台下的
管理rpm包(redhat、centos、软件包格式是rpm)
手动管理这些rpm包的命令,也叫作
rpmrpm -ivh nginx-1.20.rpm
yum自动管理rpm包,处理依赖关系(redhat、centos、提供自动化管理rpm,是yum工具)
源代码编译安装
二进制程序解压即用安装
国产的麒麟系统
乌班图
系统本身支持一个通用的软件包格式,比如乌班图的
*.debnginx-1.20.deb乌班图下,安装deb包的命令是dpkg这个命令
还提供了一个自动化下载,安装deb包的命令,叫做
apt(等于centos的yum命令)
Ubuntu软件包管理

Ubuntu近些年的粉丝越来越多,Ubuntu有着漂亮的用户界面(苹果系统),完善的包管理系统,强大的软件源支持(mysql,nginx,java,python,.golang),丰富的技术社区,Ubuntu还对大多数硬件有着良好的兼容性,包括最新的图形显卡(做区块链的,需要用最新的显卡技术做计算,那么centos可能还没有对应的驱动支持,乌班图一般就有了)等等。
这一切让Ubuntu越来越向大众化方向发展。
但别忘了:你所需要的只是一个简约、稳定、易用的服务器系统而已!
Ubuntu的图形界面固然漂亮,但这也决定了它最佳的应用领域是桌面操作系统而非服务器操作系统。如何你希望在学习Linux的过程中有个沉浸式的环境,那么Ubuntu的确不错:仅仅安装在自己的电脑中而非服务器中。
乌班图适用于物联网企业,是最多的,比如智能机器人,智能输入法,智能窗帘
乌班图适合的场景
https://cn.ubuntu.com/internet-of-things
乌班图是更好看,有更多的丰富的应用程序,更适合喜欢用linux的程序员,作为个人笔记本的系统。
和centos管理方式一样,只不过软件包的格式,不是rpm包,而是deb包
但是其他管理方式,如源码编译三部曲,二进制包安装都一样。
centos ---*.rpm ================ubuntu -------*.deb
centos ---rpm -ivh xxx===========ubuntu dpkg *.deb
centos ----yum ================ubuntu --------apt dpkg命令管理deb包
dpkg -i package.deb #安装包
dpkg -r package #删除包,保留配置文件
dpkg -P package #删除包(包括配置文件)
dpkg -L package #列出与该包关联的文件
dpkg -l package #显示该包的版本
dpkg --unpack package.deb #解开 deb 包的内容
dpkg -S keyword #搜索所属的包内容
dpkg -s package #查询软件包详细信息
dpkg -l #列出当前已安装的包
dpkg -c package.deb #列出 deb 包的内容
dpkg --configure package #配置包安装ubuntu软件
nginx_1.18.0-2~focal_amd64.deb
# 下载该软件
wget yuchaoit.cn/nginx_1.18.0-2~focal_amd64.deb
#或者更新使用阿里云apt源
`https://developer.aliyun.com/mirror/ubuntu?spm=a2c6h.13651102.0.0.13af1b1176hWcS`
# 安装该nginx
# 等于 rpm -ivh nginx.rpm
sudo dpkg -i nginx_1.18.0-2~focal_amd64.deb
# 启动nginx服务
sudo service nginx start
ss -tunlp|grep 80
tcp LISTEN 0 511 0.0.0.0:80 0.0.0.0:*
# 如何访问呢rpm包安装管理命令CentOS
安装rpm
语法
rpm [选项] [参数]选项
-a:查询所有套件;
-b<完成阶段><套件档>+或-t <完成阶段><套件档>+:设置包装套件的完成阶段,并指定套件档的文件名称;
-c:只列出组态配置文件,本参数需配合"-l"参数使用;
-d:只列出文本文件,本参数需配合"-l"参数使用;
-e<套件档>或--erase<套件档>:删除指定的套件;
-f<文件>+:查询拥有指定文件的套件;
-h或--hash:套件安装时列出标记;
-i:显示套件的相关信息;
-i<套件档>或--install<套件档>:安装指定的套件档;
-l:显示套件的文件列表;
-p<套件档>+:查询指定的RPM套件档;
-q:使用询问模式,当遇到任何问题时,rpm指令会先询问用户;
-R:显示套件的关联性信息;
-s:显示文件状态,本参数需配合"-l"参数使用;
-U<套件档>或--upgrade<套件档>:升级指定的套件档;
-v:显示指令执行过程;
-vv:详细显示指令执行过程,便于排错。参数
软件包:指定要操纵的rpm软件包。
实例
如何安装rpm软件包
rpm软件包的安装可以使用程序rpm来完成。执行下面的命令:
rpm -ivh your-package.rpm其中your-package.rpm是你要安装的rpm包的文件名,一般置于当前目录下。
安装过程中可能出现下面的警告或者提示:
... conflict with ...
可能是要安装的包里有一些文件可能会覆盖现有的文件,缺省时这样的情况下是无法正确安装的可以用rpm --force -i强制安装即可
... is needed by ...
... is not installed ...此包需要的一些软件你没有安装可以用rpm --nodeps -i来忽略此信息,也就是说rpm -i --force --nodeps可以忽略所有依赖关系和文件问题,什么包都能安装上,但这种强制安装的软件包不能保证完全发挥功能。
更多实例
[root@localhost ~]# rpm -ivh ipchains-1.3.6-1.i386.rpm #安装包,并显示详细进度
[root@localhost ~]# rpm -i ftp://ftp.xxx.xxx #在线安装
[root@localhost ~]# rpm -Va #校验所有的rpm包,查找丢失的文件
[root@localhost ~]# rpm -qf /usr/bin/who #查找一个文件属于哪个rpm包
[root@localhost ~]# rpm -ql httpd #列出该软件包都生成了什么文件
[root@localhost ~]# rpm -qpi mon-0.37j-1.i386.rpm #列出一个rpm包的描述信息
[root@localhost ~]# rpm -qpl mon-0.37j-1.i386.rpm #列出一个rpm包的文件信息
[root@localhost ~]# rpm -Uvh ipchains-1.3.6-1.i386.rpm #升级包
[root@localhost ~]# rpm -q httpd #查看httpd的安装包
[root@localhost ~]# rpm -e httpd #移除安装包
[root@localhost ~]# rpm -qa #列出所有已安装的包
[root@localhost ~]# rpm -qi httpd #得到httpd安装包的信息
Name : httpd Relocations: (not relocatable)
Version : 2.2.3 Vendor: CentOS
Release : 45.el5.centos.1 Build Date: 2011年05月04日 星期三 18时54分56秒
Install Date: 2011年06月29日 星期三 08时05分34秒 Build Host: builder10.centos.org
Group : System Environment/Daemons Source RPM: httpd-2.2.3-45.el5.centos.1.src.rpm
Size : 3281960 License: Apache Software License
Signature : DSA/SHA1, 2011年05月04日 星期三 20时31分28秒, Key ID a8a447dce8562897
URL : http://httpd.apache.org/
Summary : Apache HTTP 服务器
Description :
The Apache HTTP Server is a powerful, efficient, and extensible
web server.
[root@localhost ~]# rpm -qR httpd #查询软件所需依赖安装软件的注意事项
安装方式有三种
rpm手动安装
手动解决所有依赖,难用
rpm -ql nginxrpm -e nginx手动rm删除软件的日志,配置文件目录即可
[root@server ~]# rm -rf /var/log/nginx/不知道路径可以使用find命令进行查找
find / -name 'nginx*'将找到的文件全部删除
find / -name 'nginx*' | xargs -i rm -rf {}
yum自动安装
yum就是去管理rpm包的。
自动解决侬赖关系。
源码编译安装
软件都装到了一个目录下,管理该目录即可,无法用yum去管理。
注意他们的安装路径,以及管理脚本,是否会有冲突。
安装rpm包时常见错误以及解决办法
rpm安装软件,需要解决他们之间的依赖关系

关于解决rpm依赖冲突的实践
因为你以前是yum安装的vim,这个vim是去阿里云rpm仓库拿来的版本,比你本地光盘中的更新,以及阿里云提供的vim版本,以及它的依赖,版本都比你本地的光盘的新,用yum remove vim -y卸载vim,但是你还没完全卸载完,它的一些依赖,版本可能还是新的,需要再次卸载。
rpm的依赖冲突,一定要是,一层一层去解决,不能跳级。
源码包安装管理命令
源码编译淘宝nginx
创建
wget https://tengine.taobao.org/download/tengine-2.3.3.tar.gz
tar -zxvf tengine-2.3.3.tar.gz 编译环境准备
yum install -y gcc make gcc-c++ ncurses-devel #用于编译安装c语言代码
yum install golang -y #用于编译golang代码的环境给nginx添加支持https证书的功能,nginx默认不支持https功能。
1.需要linux系统支持https的模块,就是安装openssl模块
yum -y install openssl openssl-devel pcre pcre-devel zlib zlib-devel执行编译参数,让nginx的安装,可以扩展其他功能
./configure --prefix=/opt/my_nginx0224/ --with-http_ssl_module
开始编译安装执行
make && make install
当你make命令执行成功后,自动执行 make install命令
只有 make install 成功后,才会生成你指定的nginx路径 /opt/my_nginx0224文件夹
检查你安装的nginx是否生成
编译安装的nginx全部在这个目录下了
[root@server opt]# ll
总用量 2804
drwxr-xr-x 6 root root 54 8月 23 09:38 my_nginx0224
drwxrwxr-x 14 root root 4096 8月 23 09:34 tengine-2.3.3
-rw-r--r-- 1 root root 2848144 11月 6 2023 tengine-2.3.3.tar.gz
[root@server opt]# cd my_nginx0224/
[root@server my_nginx0224]# ll
总用量 0
drwxr-xr-x 2 root root 333 8月 23 09:38 conf
drwxr-xr-x 2 root root 40 8月 23 09:38 html
drwxr-xr-x 2 root root 6 8月 23 09:38 logs
drwxr-xr-x 2 root root 19 8月 23 09:38 sbin启动nginx
[root@server my_nginx0224]# /opt/my_nginx0224/sbin/nginx
[root@server my_nginx0224]# netstat -tnlp|grep 80
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 10028/nginx: master
验证nginx信息
[root@server my_nginx0224]# curl -I 10.0.0.130
HTTP/1.1 200 OK
Server: Tengine/2.3.3
Date: Fri, 23 Aug 2024 01:46:32 GMT
Content-Type: text/html
Content-Length: 555
Last-Modified: Fri, 23 Aug 2024 01:38:48 GMT
Connection: keep-alive
ETag: "66c7e828-22b"
Accept-Ranges: bytes启动命令应该做好优化
将启动软件绝对路径添加到PATH变量中。
vim /etc/profile
PATH=/opt/my_nginx0224/sbin/:$PATH
查询
ls /opt/my_nginx0224
client_body_temp fastcgi_temp logs sbin uwsgi_temp
conf html proxy_temp scgi_temp升级
删除旧的,重新编译新的。删除
就是删除安装路径
rm -rf /opt/my_nginx0224/
清除PATH变量信息解压即用软件包实践
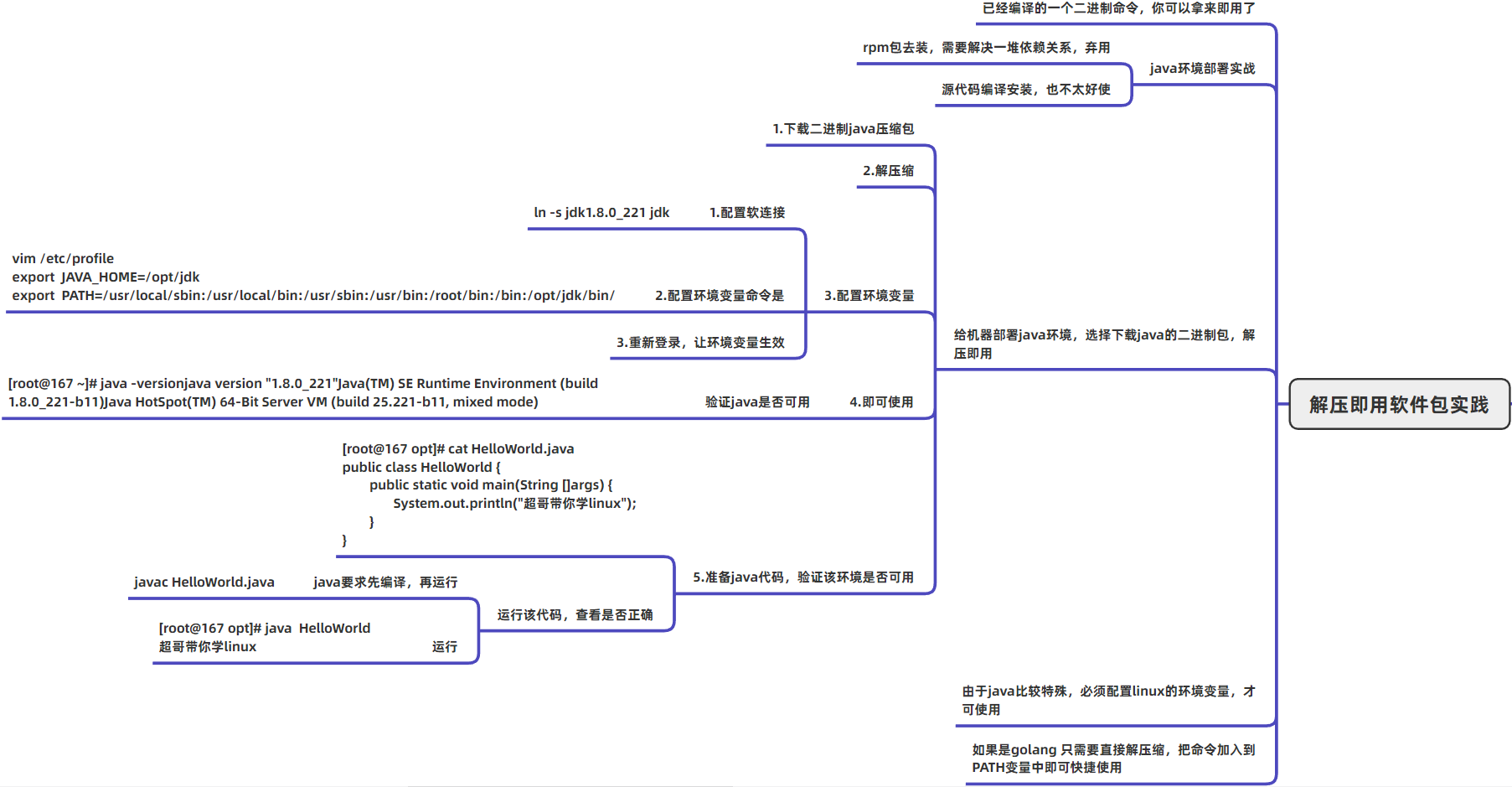
1,下载二进制java压缩包,并解压缩
2,配置软连接
ln -s jdk1.8.0_221 jdk
3,配置环境变量
vim /etc/profile
export JAVA_HOME=/opt/jdk
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/bin:/opt/jdk/bin/
4,验证java是否可用
java -versionjava version
5,准备java代码,验证该环境是否可用
[root@167 opt]# cat HelloWorld.java
public class HelloWorld {
public static void main(String []args) {
System.out.println("超哥带你学linux");
}
}
6,运行该代码,查看是否正确
6.1,java要求先编译,再运行
javac HelloWorld.java
6.2,运行
[root@167 opt]# java HelloWorld
超哥带你学linuxyum自动化软件管理命令

Linux资源管理
Linux中对需要运维去管理、去查看的资源信息,如下:
内存资源、使用率
free
磁盘资源、使用率
df
CPU资源、使用率
top
htop
glances
进程资源、使用率
ps
pstree
pidof
网络资源、使用率
lftop
所有资源的整体查看命令
top
glances
htop
进程资源管理
什么是进程
计算机核心是CPU,承担机器的计算任务,好比是一座工厂,时刻在运行着。

一个工厂(计算机),可以有多个车间,同时在工作。(计算机有多个进程,同时在运行)

进程是正在执行的一个程序或命令,每个进程都是一个运行的实体,并占用一定的系统资源。
程序是人使用计算机语言编写的可以实现特定目标或解决特定问题的代码集合。
简单来说,程序是人使用计算机语言编写的,可以实现一定功能,并且可以执行的代码集合。
进程是正在计算机执行中的程序。
举例:谷歌浏览器是一个程序,当我们打开谷歌浏览器,就会在系统中看到一个浏览器的进程,当程序被执行时,程序的代码都会被加载入内存,操作系统给这个进程分配一个ID,称为PID(进程ID)。
我们打开多个谷歌浏览器,就有多个浏览器子进程,但是这些进程使用的程序,都是chrome。
进程与程序的关系
开发把代码写好了,打个压缩包给你,还未运行的时候,这就是个静态、程序源代码,程序是数据和指令的集合。
当运维将开发的代码运行起来之后,就称之为进程(机器上一个在运行的程序)。
程序运行时,系统为了清晰的标记每一让个进程,为其分配了PID、运行的用户、内存、CPU等使用情况。
进程、线程、协程
进程fork概念
我们的操作系统都是一堆进程而已,系统运行时,就产生了0号进程,然后其他进程都是0号进程创建的子进程。
linux启动之后,第一个进程就是PID为0,然后通过0号进程fork()出其他的进程。
操作系统的运行,就是不断的创建进程、以及销毁进程。
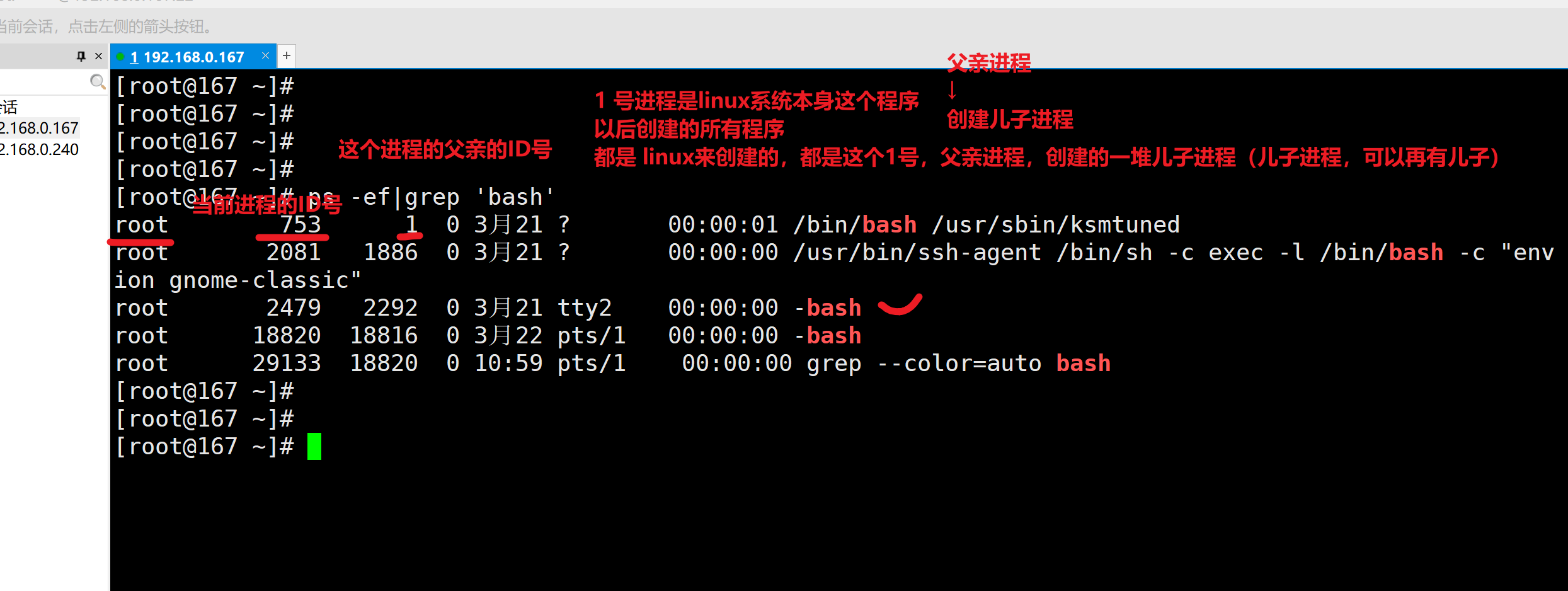
我们登录的xshell终端,是这样的流程
系统上运行了sshd服务
通过ssh客户端命令,都是去连接这个服务,产生的一堆子进程而已。
[root@server ~]# ps -auxf
root 1200 0.0 0.1 113004 4320 ? Ss 06:29 0:00 /usr/sbin/sshd -D
root 5004 0.0 0.1 163856 6196 ? Ss 09:48 0:00 \_ sshd: admin [priv]
admin 5006 0.0 0.0 163856 2552 ? S 09:48 0:00 \_ sshd: admin@pts/1
admin 5009 0.0 0.0 116744 3252 pts/1 Ss 09:48 0:00 \_ -bash
root 5062 0.0 0.1 277744 6940 pts/1 S 09:48 0:00 \_ sudo -i
root 5067 0.0 0.0 116756 3316 pts/1 S 09:48 0:00 \_ -bash
root 5164 0.0 0.0 157840 2188 pts/1 R+ 09:53 0:00 \_ ps -auxf
通过命令,查看他们的父子关系
通过他们的进程id号来确认无误
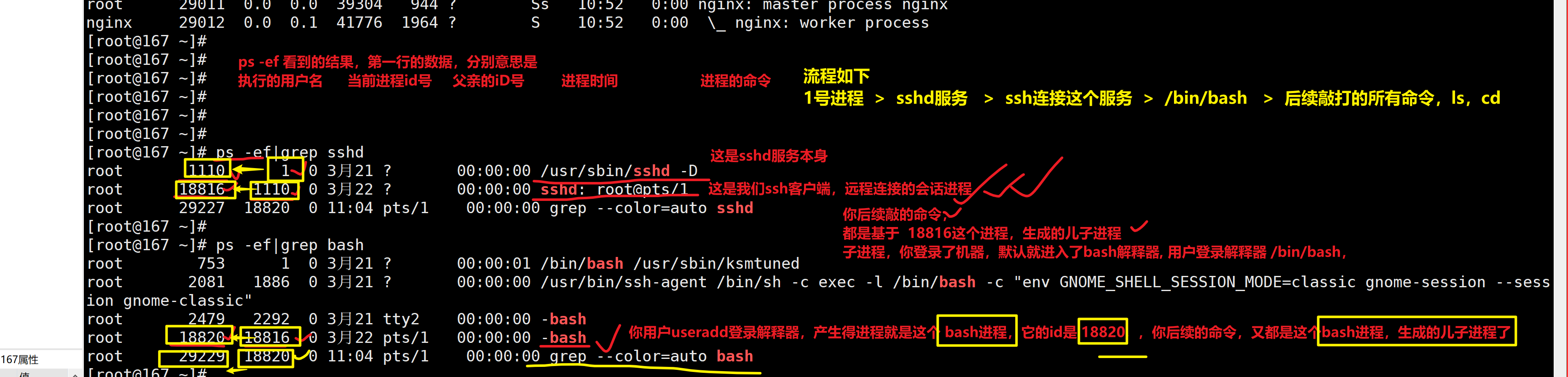
ps进程查看与管理
进程管理
管理进程命令为
ps,用于列出当前系统进程的状态。
基础用法
ps [aux] [-ef]
其中[aux]可以列出登录系统所有用户的进程信息;
列出的信息包括进程的识别符PID、CPU和已经花费的实时时间、内存、进程的优先级、进程命令、进程用户等等信息。
ps命令所列出的进程中,有以下几点需要注意的:
方括号中的进程一般是内核进程,会列在列表的最前面。
僵停进程在ps列表中显示为exiting或defunct。
ps命令只用于显示一次进程的状态信息,如果需要持续观察进程的状态,使用命令top来持续观察进程的动态。参数解释
# UNIX风格,没有短横线
a # 显示所有终端、所有用户执行的进程
u # 以用户显示出进程详细信息
x # 显示操作系统所有进程信息
f # 显示进程树形结构
o # 格式化显示进程信息,指定如pid
k # 对进程属性排序,如k %mem ,正序排序 ,k -%mem 逆序
--sort,再进行排序,如 --sort %mem 根据内存使用率显示
linux标准参数用法
-e # 显示所有进程
-f # 显示进程详细,pid,udi,进程名
-p # 指定pid,显示其信息,如 ps -fp 2609
-C # 指定进程的名字查看,如ps -fC sshd
-U # 指定用户名,查看用户进程信息 ps -Uf server[root@server ~]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 06:28 ? 00:00:01 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0 0 06:28 ? 00:00:00 [kthreadd]
#PID == process id (子进程ID)
#PPID == parent process id (父进程ID)例如查看NGINX进程信息
ps -ef | grep 'nginx'ps指定属性查看
ps axo pid,cmd,%cpu,%mem k -%cpu
[root@server ~]# ps axo pid,cmd,%cpu,%mem k -%cpu
PID CMD %CPU %MEM
1 /usr/lib/systemd/systemd -- 0.0 0.1
2 [kthreadd] 0.0 0.0
ps axfo pid,cmd,%cpu,%mem
[root@server ~]# ps axfo pid,cmd,%cpu,%mem
PID CMD %CPU %MEM
2 [kthreadd] 0.0 0.0
4 \_ [kworker/0:0H] 0.0 0.0pstree以树状图显示进程信息
以树状图显示进程信息
[root@server ~]# pstree
systemd─┬─ModemManager───2*[{ModemManager}]
├─VGAuthService
├─abrt-dbus───2*[{abrt-dbus}]
├─2*[abrt-watch-log]
├─abrtd
├─accounts-daemon───2*[{accounts-daemon}]
├─alsactl
├─at-spi-bus-laun─┬─dbus-daemon
│ └─3*[{at-spi-bus-laun}]
├─at-spi2-registr───2*[{at-spi2-registr}]
以树状图显示进程信息且显示pid
[root@server ~]# pstree -p
systemd(1)─┬─ModemManager(758)─┬─{ModemManager}(795)
│ └─{ModemManager}(797)
├─VGAuthService(768)
├─abrt-dbus(7545)─┬─{abrt-dbus}(7546)
│ └─{abrt-dbus}(7548)
├─abrt-watch-log(759)
├─abrt-watch-log(761)
├─abrtd(714)
├─accounts-daemon(724)─┬─{accounts-daemon}(731)
│ └─{accounts-daemon}(751)
├─alsactl(721)
├─at-spi-bus-laun(1821)─┬─dbus-daemon(1828)
│ ├─{at-spi-bus-laun}(1824)
│ ├─{at-spi-bus-laun}(1825)
│ └─{at-spi-bus-laun}(1827)
├─at-spi2-registr(1831)─┬─{at-spi2-registr}(1832)
│ └─{at-spi2-registr}(1833)pidof以进程名找出他的pid
[root@server ~]# pidof nginx
7901 7900 7899孤儿进程
父进程由于某原因挂了,代码写的不好,导致生成的一堆儿子进程,没有父亲了,成为了孤儿。
系统有一个1号进程,等于是一个福利院,去收养这些孤儿进程(1号进程会去接替,管理这些孤儿进程的数据)你就能看到,这些孤儿进程,的ppid,就成了1号进程了。
孤儿进程释放后,释放执行的相关文件,数据,以及释放进程id号(系统id号是有固定的数量)。
演示孤儿进程,但是需要用代码实现,一般都是代码写的垃圾,才会出现这种情况。
# 于超老师教你用python实现,孤儿进程。
# 运行一个python程序,用的是系统自带的python2语法
# 1.touch 创建脚本
# 2.写入代码
# 3. 用python解释器 去读这个程序
[root@server ~]# mkdir /opt/test_process
[root@server ~]# cd /opt/test_process/
[root@server test_process]# vim guer.py
~
~
:set paste
#由于使用的是脚本文件,粘贴需要使用插入模式::set paste
#coding:utf-8
import os
import sys
import time
pid = os.getpid()
ppid = os.getppid()
print 'im father: ', 'pid: ', pid, 'ppid: ', ppid
son_pid = os.fork()
print('now song_pid is: ',son_pid)
#执行pid=os.fork()则会生成一个子进程
#返回值pid有两种值:
# 如果返回的pid值为0,表示在子进程当中
# 如果返回的pid值>0,表示在父进程当中
if son_pid > 0:
print 'father going die...'
# 让老父亲,主动退出,挂掉
sys.exit(0)
# 保证主线程退出完毕
# 程序延迟了1秒,还在运行中,儿子进程还未挂,成了孤儿
time.sleep(20)
print 'im child: ', os.getpid(),'now my father is: ', os.getppid()
~
~
-- INSERT (paste) --查看孤儿进程
[root@server test_process]# ps -ef |grep guer
root 5674 5067 0 10:30 pts/1 00:00:00 grep --color=auto guer
运行脚本
[root@server test_process]# python guer.py #程序运行,由当前bash终端 5067 执行py脚本
im father: pid: 5675 ppid: 5067 #父亲pid是5675
('now song_pid is: ', 5676) #生成子进程pid是5676
father going die... #然后父亲进程主动挂掉
('now song_pid is: ', 0)
查看孤儿进程
[root@server test_process]# ps -ef |grep guer
root 5676 1 0 10:31 pts/1 00:00:00 python guer.py
root 5678 5067 0 10:31 pts/1 00:00:00 grep --color=auto guer
#通过如上信息可以看到子进程 5676 变成了孤儿,自动被 1 号进程收养。
等待20秒
[root@server test_process]# im child: 5676 now my father is: 1
#20 秒后程序退出,子进程自动也退出了。
再次查看guer进程
[root@server test_process]# ps -ef |grep guer
root 5688 5067 0 10:31 pts/1 00:00:00 grep --color=auto guer
#1号进程释放 5676 孤儿进程,进程消失。僵尸进程
父亲进程创建出子进程后,如果子进程先挂了,父进程却不知道儿子进程挂了这件事,就无法正确送走儿子进程,清楚它在系统中的信息,那么这个儿子进程就成了可怕的僵尸进程,会对系统产生危害。
当系统中有了僵尸进程,你可以通过ps命令找到它,并且它的状态是(Z,zombie僵尸进程)。
如果系统中产生大量僵尸进程,占据了系统中大量可分配的资源,如进程id号,系统就无法再正确创建新进程,完成任务,导致系统无法使用的危害。
演示僵尸进程
[root@server ~]# vim /opt/test_process/zombie.py
#coding;utf-8
from multiprocessing import Process
import time,os
def run():
print('son_pid:",os.getpid())
if __name__ == '__main__':
p=Process(target=run)
p.start()
print("father_pid:',os.getpid())
time.sleep(1000)查看僵尸进程
[root@server test_process]# python zombie.py
('father_pid: ', 6681) #父亲进程pid
('son_pid: ', 6682) #儿子进程pid
[root@server ~]# ps -ef | grep 6681 #看到如下进程状态,就是僵尸进程
root 6681 6420 0 16:26 pts/0 00:00:00 python zombie.py
root 6682 6681 0 16:26 pts/0 00:00:00 [python] <defunct> #可以看到儿子进程已经挂了注:还可以用top命令去看,有几个僵尸进程zombie
[root@server ~]# top
top - 16:32:01 up 4:37, 3 users, load average: 0.00, 0.02, 0.05
Tasks: 189 total, 1 running, 187 sleeping, 0 stopped, 1 zombie #这里可以看到有一个僵尸进程如何解决僵尸进程问题
杀死父进程
优化代码,不要再写这种垃圾代码了,把unix高级编程,好好学学。
开除、换一个更懂操作系统的程序员。
可以主动
kill父亲进程pid 如果程序会自动结束的话,比如time.sleep()时间到期,也会退出所有进程。
强制中断有问题的脚本后,僵尸进程zombie消失。
[root@server test_process]# python zombie.py
('father_pid: ', 6681)
('son_pid: ', 6682)
^CTraceback (most recent call last):
File "zombie.py", line 13, in <module>
time.sleep(1000)
KeyboardInterrupt
[root@server ~]# top
top - 16:36:08 up 4:41, 3 users, load average: 0.00, 0.01, 0.05
Tasks: 187 total, 2 running, 185 sleeping, 0 stopped, 0 zombie快速理解僵尸进程
全中国的中国移动网络好比是一个操作系统,控制着全中国的移动用户通信,每一个中国百姓就是一个进程,每一个百姓都有一个手机号,该号码就好比进程的pid,对应这个进程。
如果这个人再也不用手机了,不要手机号了,应该去移动注销手机号(告诉操作系统,回收pid)。
如果不去注销(不回收pid),这个手机号依然被你保留着,毫无意义不说,且占用了一个号码,浪费手机(浪费系统中pid的资源),应该去释放手机号。
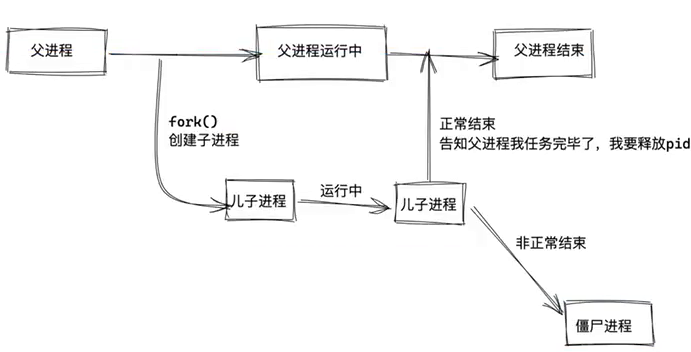
进程的生命周期
当程序运行的时候,通过父进程fork创建子进程去处理任务。
子进程被创建后开始处理任务,任务处理完毕后就退出了,子进程应该去通知父进程,将儿子进程销毁,别浪费资源。
如果子进程没有正确告知父进程,回收自己的系统资源,且父进程还未结束,导致该子进程成为僵尸进程。
ps aux说明
[root@localhost ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.6 128156 6780 ? Ss 16:27 0:01 /usr/lib/systemd/systemd --switched-
root 2 0.0 0.0 0 0 ? S 16:27 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 16:27 0:00 [ksoftirqd/0]
root 5 0.0 0.0 0 0 ? S< 16:27 0:00 [kworker/0:0H]ps -ef和ps aux主要区别
1、ps -ef用于查看全格式的全部进程,ps -aux也是用于查看进程。其中"ps"是在Linux中是查看进程的命令,"-e ”参数代表显示所有进程,"-f” 参数代表全格式。
2、ps -ef和ps aux,这两者的输出结果差别不大,但展示风格不同。aux 是BSD风格,显示的项目有: USER, PID , %CPU , %MEM, VSZ, RSS, TTY, STAT , START , TIME,COMMAND。而-ef 是System V风格,显示的项目有: UID , PID, PPID, C, STIME,TTY ,TIME , CMD。
3、COMMADN列如果过长,aux 会截断显示,而ef不会。综上,如果想查看进程的CPU占用率和内存占用率,可以使用aux,如果想查看进程的父进程ID和完整的COMMAND命令,可以使用ef。
kill常用信号及杀死进程
信号是进程之间通信的一种方式
杀死进程
命令名称: kill
说明:用来删除执行中的程序或工作。
常用命令
kill -[信号编号] [pid] #结束指定pid的进程
killall [进程名] #根据进程名杀死(不建议使用,容易误杀)
pkill [进程名] #根据进程名杀死(不建议使用,容易误杀)实例
杀死nginx进程
[root@server ~]# ps -ef |grep nginx
root 9359 1 0 22:06 ? 00:00:00 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
nginx 9360 9359 0 22:06 ? 00:00:00 nginx: worker process
nginx 9362 9359 0 22:06 ? 00:00:00 nginx: worker process
root 9647 8712 0 22:25 pts/1 00:00:00 grep --color=auto nginx
[root@server ~]# kill -9 9359后台命令
程序运行可以有2种
前台运行
程序运行在当前的终端,所有的信息都输出到屏幕上,占用你的终端,你也无法继续使用。
如果终端异常关闭,导致程序会自动退出。
后台运行
不会占用你的终端,程序在系统后台跑着,你该干啥干啥,终端关了,程序也继续运行。
后台运行命令
命令集合
[命令]& #未启动的命令放入后台去运行
jobs #查看后台进程列表
ctrl+z #暂停进程
bg #程序放入后台运行,和&一样
fg #将后台任务放入前台执行实例
1.命令直接放入后台运行,注意日志写入到黑洞文件
[root@server ~]# ping www.taobao.com > /dev/null &
[1] 97292.查看后台任务列表
[root@server ~]# jobs
[1]+ Running ping www.taobao.com > /dev/null &3.可以将后台任务,放入前台执行,然后ctrl+z再次暂停程序,放入后台
[root@server ~]# fg 1
ping www.taobao.com > /dev/null
^Z
[1]+ Stopped ping www.taobao.com > /dev/null
的确发现了一个停止的程序
[root@server ~]# jobs
[1]+ Stopped ping www.taobao.com > /dev/null4.可以再次让程序运行起来,并且依然是运行在后台
[root@server ~]# bg 1
[1]+ ping www.taobao.com > /dev/null &
[root@server ~]# jobs
[1]+ Running ping www.taobao.com > /dev/null &nohup
nohup 英文全称 no hang up(不挂起),用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行。 nohup的特点是
nohup 命令,在默认情况下(非重定向时),会输出一个名叫nohup.out的文件到当前目录下。
如果当前目录的 nohup.out文件不可写,输出重定向到$HOME/nohup.out文件中。
一般和&后台符,结合使用。
记住一个标准用法
no
语法:
nohup [command] [选项] [&]Command:要执行的命令
Arg:一些参数,可以指定输出文件。
&:让命令在后台执行,终端退出后命令仍旧执行。
实例
简单用法:
[root@server opt]# nohup ping taobao.com &
[2] 2246
[root@server opt]# nohup: 忽略输入并把输出追加到"nohup.out"
[root@server opt]# tail -f nohup.out
64 bytes from 59.82.43.234 (59.82.43.234): icmp_seq=14 ttl=87 time=46.4 ms
64 bytes from 59.82.43.234 (59.82.43.234): icmp_seq=15 ttl=87 time=46.4 ms
64 bytes from 59.82.43.234 (59.82.43.234): icmp_seq=16 ttl=87 time=46.5 ms
64 bytes from 59.82.43.234 (59.82.43.234): icmp_seq=17 ttl=87 time=46.7 ms
#中断 nohup ping taobao.com &
[root@server opt]# jobs -l
[1] 2221 运行中 nohup ping taobao.com &
[2]- 2246 运行中 nohup ping taobao.com &
[3]+ 2247 停止 tail -f nohup.out
[root@server opt]# kill 2221
[root@server opt]# kill 2246
[1] 已终止 nohup ping taobao.com
[root@server opt]# jobs -l
[2]- 2246 已终止 nohup ping taobao.com
[3]+ 2247 停止 tail -f nohup.outnohup不加&符号不好用
有些命令会前台运行,占用一个会话窗口,无法做其他事,且关闭窗口后,该任务会结束,导致工作中断。
lsof查看进程开打的文件
lsof(list open files)是一个列出当前系统打开文件的工具。
在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。
所以如传输控制协议 (TCP) 和用户数据报协议 (UDP) 套接字等,系统在后台都为该应用程序分配了一个文件描述符,无论这个文件的本质如何,该文件描述符为应用程序与基础操作系统之间的交互提供了通用接口。
因为应用程序打开文件的描述符列表提供了大量关于这个应用程序本身的信息,因此通过lsof工具能够查看这个列表对系统监测以及排错将是很有帮助的。
lsof 命令可显示系统打开的文件,因为 lsof 需要访问核心内存和各种文件,所以必须以 root 用户的身份运行它才能够充分地发挥其功能。
用法
losf [选项] 进程名选项
-a:列出打开文件存在的进程;
-c<进程名>:列出指定进程所打开的文件;
-g:列出GID号进程详情;
-d<文件号>:列出占用该文件号的进程;
+d<目录>:列出目录下被打开的文件;
+D<目录>:递归列出目录下被打开的文件;
-n<目录>:列出使用NFS的文件;
-i<条件>:列出符合条件的进程。(ipv4、ipv6、协议、:端口、 @ip )
-p<进程号>:列出指定进程号所打开的文件;
-u:列出UID号进程详情;显示指定用户uid打开的文件,以及具体进程信息
[root@server ~]# lsof -u admin
-h:显示帮助信息;
-v:显示版本信息。
-s:列出文件大小
实例
列出所有正在使用文件
[root@server ~]# lsof
COMMAND PID TID USER FD TYPE DEVICE SIZE/OFF NODE NAME
systemd 1 root cwd DIR 253,0 238 64 /
systemd 1 root rtd DIR 253,0 238 64 /
systemd 1 root txt REG 253,0 1632960 34361530 /usr/lib/systemd/systemd
systemd 1 root mem REG 253,0 20064 58844 /usr/lib64/libuuid.so.1.3.0
systemd 1 root mem REG 253,0 265576 97583 /usr/lib64/libblkid.so.1.1.0
systemd 1 root mem REG 253,0 90160 58556 /usr/lib64/libz.so.1.2.7
systemd 1 root mem REG 253,0 157440 58872 /usr/lib64/lilsof输出各列信息的意义如下:
COMMAND:进程的名称
PID:进程标识符
PPID:父进程标识符(需要指定-R参数)
USER:进程所有者
PGID:进程所属组
FD:文件描述符,应用程序通过文件描述符识别该文件。
一般在标准输出、标准错误、标准输入后还跟着文件状态模式:
u:表示该文件被打开并处于读取/写入模式。
r:表示该文件被打开并处于只读模式。
w:表示该文件被打开并处于。
空格:表示该文件的状态模式为unknow,且没有锁定。
-:表示该文件的状态模式为unknow,且被锁定。
文件类型:
DIR:表示目录。
CHR:表示字符类型。
BLK:块设备类型。
UNIX: UNIX 域套接字。
FIFO:先进先出 (FIFO) 队列。
IPv4:网际协议 (IP) 套接字。
DEVICE:指定磁盘的名称
SIZE:文件的大小
NODE:索引节点(文件在磁盘上的标识)
NAME:打开文件的确切名称
找出谁在使用某个文件
[root@server ~]# lsof /usr/sbin/nginx
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 7899 root txt REG 253,0 1407480 97706 /usr/sbin/nginx
nginx 7900 nginx txt REG 253,0 1407480 97706 /usr/sbin/nginx
nginx 7901 nginx txt REG 253,0 1407480 97706 /usr/sbin/nginx查看占用文件进程
[root@server ~]# lsof /var/log/nginx/access.log
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 7899 root 5w REG 253,0 0 18239529 /var/log/nginx/access.log
nginx 7900 nginx 5w REG 253,0 0 18239529 /var/log/nginx/access.log
nginx 7901 nginx 5w REG 253,0 0 18239529 /var/log/nginx/access.log列出所有udp网络连接
[root@server ~]# lsof -i udp
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rpcbind 709 rpc 6u IPv4 19779 0t0 UDP *:sunrpc
rpcbind 709 rpc 7u IPv4 19780 0t0 UDP *:884
rpcbind 709 rpc 9u IPv6 19782 0t0 UDP *:sunrpc
rpcbind 709 rpc 10u IPv6 19783 0t0 UDP *:884
avahi-dae 723 avahi 12u IPv4 23236 0t0 UDP *:mdns
avahi-dae 723 avahi 13u IPv4 23237 0t0 UDP *:33219
chronyd 729 chrony 5u IPv4 21463 0t0 UDP localhost:323
chronyd 729 chrony 6u IPv6 21464 0t0 UDP localhost:323
dnsmasq 1790 nobody 3u IPv4 29189 0t0 UDP *:bootps
dnsmasq 1790 nobody 5u IPv4 29192 0t0 UDP server:domain
dhclient 6282 root 6u IPv4 69510 0t0 UDP *:bootpc 通过nginx进程pid号找出nginx的日志文件所在目录
方法一:
[root@server ~]# ps -ef |grep nginx
root 7899 1 0 19:30 ? 00:00:00 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
nginx 7900 7899 0 19:30 ? 00:00:00 nginx: worker process
nginx 7901 7899 0 19:30 ? 00:00:00 nginx: worker process
root 8490 7774 0 20:06 pts/2 00:00:00 grep --color=auto nginx
[root@server ~]# lsof -p 7899 |grep log
nginx 7899 root 2w REG 253,0 568 18239540 /var/log/nginx/error.log
nginx 7899 root 4w REG 253,0 568 18239540 /var/log/nginx/error.log
nginx 7899 root 5w REG 253,0 0 18239529 /var/log/nginx/access.log方法二:
[root@server ~]# lsof -c nginx |grep log
nginx 7899 root 2w REG 253,0 568 18239540 /var/log/nginx/error.log
nginx 7899 root 4w REG 253,0 568 18239540 /var/log/nginx/error.log
nginx 7899 root 5w REG 253,0 0 18239529 /var/log/nginx/access.log
nginx 7900 nginx 2w REG 253,0 568 18239540 /var/log/nginx/error.log
nginx 7900 nginx 4w REG 253,0 568 18239540 /var/log/nginx/error.log
nginx 7900 nginx 5w REG 253,0 0 18239529 /var/log/nginx/access.log
nginx 7901 nginx 2w REG 253,0 568 18239540 /var/log/nginx/error.log
nginx 7901 nginx 4w REG 253,0 568 18239540 /var/log/nginx/error.log
nginx 7901 nginx 5w REG 253,0 0 18239529 /var/log/nginx/access.log不小心删除了nginx的access.log文件,如何恢复?
[root@server ~]# rm -rf /var/log/nginx/access.log
查看nginx进程pid号
[root@server ~]# ps -ef |grep nginx
root 7899 1 0 21:03 ? 00:00:00 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
nginx 7900 7899 0 21:03 ? 00:00:00 nginx: worker process
nginx 7901 7899 0 21:03 ? 00:00:00 nginx: worker process
root 8772 8712 0 21:52 pts/1 00:00:00 grep --color=auto nginx
查看数据删除目录下/proc的nginx进程7899文件夹
[root@server ~]# ls /proc/7899
attr coredump_filter gid_map mountinfo oom_score sched statm
autogroup cpuset io mounts oom_score_adj schedstat status
auxv cwd limits mountstats pagemap sessionid syscall
cgroup environ loginuid net patch_state setgroups task
clear_refs exe map_files ns personality smaps timers
cmdline fd maps numa_maps projid_map stack uid_map
comm fdinfo mem oom_adj root stat wchan
找到fd文件,可以看到`/proc/7899/fd/5 -> /var/log/nginx/access.log (deleted)`是被删除状态。
[root@server ~]# ls -l /proc/7899/fd/*
lrwx------ 1 root root 64 Aug 21 19:40 /proc/7899/fd/0 -> /dev/null
lrwx------ 1 root root 64 Aug 21 19:40 /proc/7899/fd/1 -> /dev/null
l-wx------ 1 root root 64 Aug 21 19:40 /proc/7899/fd/2 -> /var/log/nginx/error.log
lrwx------ 1 root root 64 Aug 21 19:40 /proc/7899/fd/3 -> socket:[91939]
l-wx------ 1 root root 64 Aug 21 19:40 /proc/7899/fd/4 -> /var/log/nginx/error.log
l-wx------ 1 root root 64 Aug 21 19:40 /proc/7899/fd/5 -> /var/log/nginx/access.log (deleted)
lrwx------ 1 root root 64 Aug 21 19:40 /proc/7899/fd/6 -> socket:[92569]
lrwx------ 1 root root 64 Aug 21 19:40 /proc/7899/fd/7 -> socket:[91940]
lrwx------ 1 root root 64 Aug 21 19:40 /proc/7899/fd/8 -> socket:[91941]
lrwx------ 1 root root 64 Aug 21 19:40 /proc/7899/fd/9 -> socket:[91942]
将进程access.log对应的pid文件内容重新重定向到 /var/log/nginx/access.log中,完成数据恢复。
[root@server ~]# cat /proc/7899/fd/5 > /var/log/nginx/access.log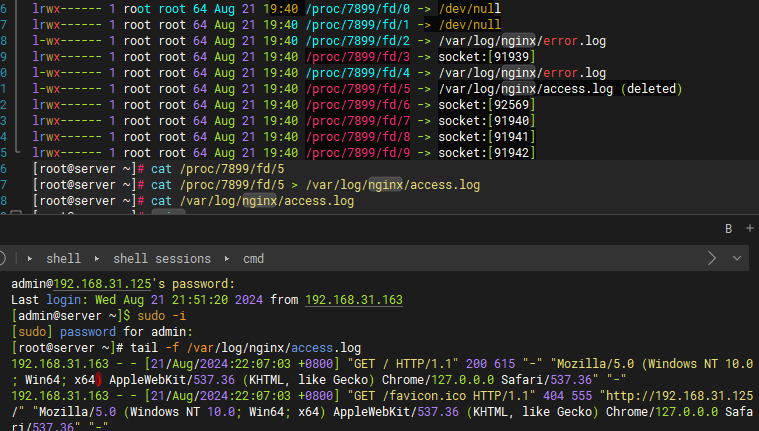
top默认资源管理器
1、top命令:相当于Windows' 下的资源管理器,能够动态实时的显示系统中进程的资源占用情况。
2、在Linux终端上输入top命令出现的结果及其表示的含义如下图:
top操作快捷键
z:打开,关闭颜色。
M:表示将结果按照内存(MEM)从高到低进行降序排列。
m:切换内存memmory的显示格式。
P:表示将结果按照CPU 使用率从高到低进行降序排列。
1:当服务器拥有多个cpu 的时候可以使用1快捷键来切换是否展示显示各个cpu 的详细信息。
q:退出
htop更好用的资源管理
yum install htop -y
[root@server ~]# htop
glances更更更好用的资源管理器
glances工具是基于Python开发的,可移植性强,且使用于Linux、macOS、Windows操作系统。
此外glances还提供了web可视化界面。
yum install glances -y
[root@server ~]# glances
内存资源管理
free查看内存使用情况
命令:free
作用:查看内存使用情况
语法:#free -m
选项:
-m 表示以mb为单位查看(1g=1024mb,1mb=1024kb)
-h 以可读形式显示容量,需要
free -V显示版本大于3.3
默认free命令是KB单位
[root@server ~]# free
total used free shared buff/cache available
Mem: 3861076 494736 2627012 14772 739328 3110804
Swap: 2097148 0 2097148free 命令主要是用来查看内存和 swap 分区的使用情况的,其中:
total:是指物理内存总大小,信息来自于/proc/meminfo
used:是指已经使用的内存,userd=tota1-free-buffers-cache
free:是指空闲的;free:total-used-buff-cache
shared:是指共享的内存;用于tmpfs系统
buff/cache
buffers:缓冲区,写入缓冲,用于内存和磁盘之间的数据写入缓冲,存放内存需要写入到磁盘的数据。
cached:缓存区,读取缓存,加快CPU和内存数据交换,存放内存已经读取完毕的数据。
关于第二行的swap,现状是完全关掉这个功能的。
第2行数据是Swap交换分区,也就是我们通常所说的虚拟内存(硬件交换分区)
防止内存用完导致系统崩溃,临时拿硬盘的一些空间当做内存使。
buff和cache
buffer,==缓冲区==,buffers是给==写入数据==时加速的
Cache,==缓存==,Cached是给==读取数据==时加速的
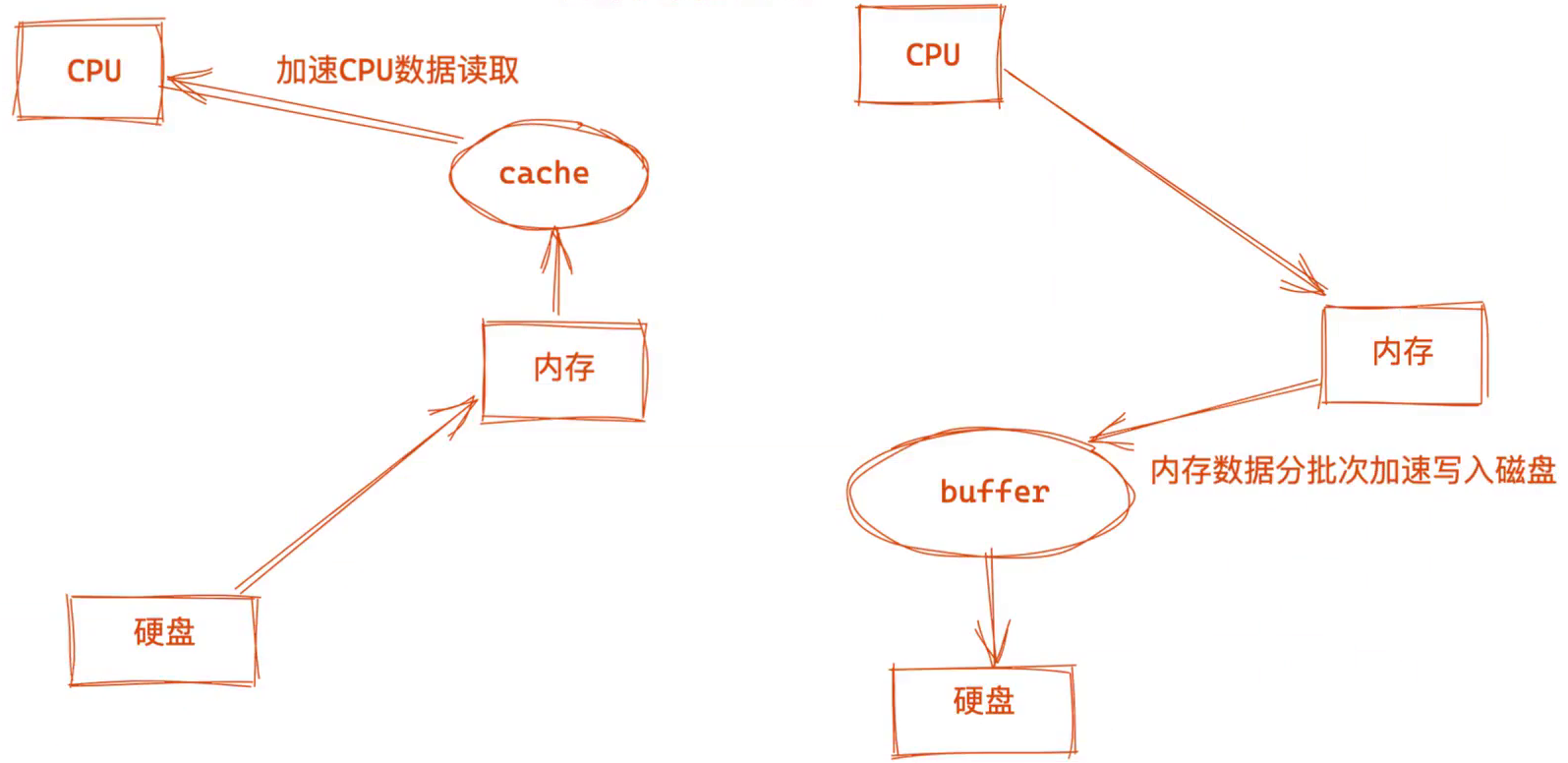
CPU压力负载
uptime系统平均负载查看
系统负载指的是在单位时间内,系统分配给CPU处理的进程数量,必然是数量越多,负载值越高,机器的压力越大。
[root@server ~]# uptime
10:26:45 up 42 min, 1 user, load average: 0.08, 0.07, 0.06
这个load average表示平均负载,多少数值比较合适?
4核,最理想,最大化发挥作用。
4核,每一个核,都在干活中(讲究,高并发编程,说的就是,如何让你的代码,让所有cpu同时起来工作)。
4个cpu,你的代码,只让一个cpu在干活。
1.最理想化的状态是每个CPU都在运行着进程,充分让cpu工作起来,效率最大化,你得先看看你机器上有几个CPU(几个核,就是有几个cpu可以工作)。
# 发现是2核的
[root@server ~]# lscpu |grep -i '^cpu(s)'
CPU(s): 2
# 以及用top命令,按下数字1,查看几核。
top
2. 如何理解uptime看到的负载
分别是1、5、15分钟内的平均负载情况,表示是1~15分钟内CPU的负载变化情况。
1. 三个值如果差不多,表示系统很稳定的运行中,15分钟以内,CPU都没有很忙
2. 如果1分钟内的值,远大于15分钟的值,表示机器在1分钟内压力在直线上升
3. 如果1分钟内的值,小于15分钟的值,表示系统的负载正在下降中CPU压力测试
cpu的压力手来自于高频的计算任务,比如数值计算等,我们可以用bash程序,python程序,以及各种编程语
言,来实现复杂的高频率计算。
这里我们用几个工具
stress stress是一个1inux的压力测试工具,专门用于对设备的CPU、IO、内存、负载、磁盘等进行压测。
mpstat 多核CPU性能分析。
pidstat 实时查看cpu、内存、IO等指标。
实践
1.安装stress工具
yum install stress -y
2.使用stress命令,给机器进行压力测试,这个命令会让你的机器,cpu达到100%,以此实现最高压的环境
# --cpu 2 让2个c
stress --cpu 1 --timeout 600
#如下图可以看到CPU1已经跑满了
sysstat工具包
sysstat是一个软件包,包含监测系统性能及效率的一组工具,这些工具对于我们收集系统性能数据,比如:
CPU 使用率、硬盘和网络吞吐数据;这些数据的收集和分析,有利于我们判断系统是否正常运行,是提高系统运行效率、安全运行服务器的得力助手。
磁盘资源管理
df查看磁盘使用情况
[root@server ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 1.9G 0 1.9G 0% /dev
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 1.9G 13M 1.9G 1% /run
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
/dev/mapper/centos-root 17G 5.9G 12G 35% /
/dev/sda1 1014M 233M 782M 23% /boot
tmpfs 378M 20K 378M 1% /run/user/1000
/dev/sr0 4.2G 4.2G 0 100% /run/media/admin/CentOS 7 x86_64磁盘io监控(iotop)
iotop命令 是一个用来监视磁盘I/O使用状况的top类工具, iotop具有与top相似的UI,其中包括PID、用户、IO、进程等相关信息。
iotop工具需要额外安装
yum install iotop -y语法
iotop -[参数]常用命令参数
-o:只显示有io操作的进程
-b:批量量示,无交互,主要用作记录到文件。
-n NUM:显示NUM次,主要用于非交互式模式
-d SEC:问隔SEC秒显示一次。
-P PID:监控的进程pid.
-U USER:监控的进程用户。
-k 以KB单位显示读写数据信息。
常用快捷键
左右箭头←→:改变排序方式,默认是按IO排序
r:改变排序顺序
o:只显示有IO输出的进程
P:进程/线程的显示方式的切换,切换pid、tid
a:显示累积使用量
q:退出
网络资源管理
网络模型
OSI模型
OSI 模型(Open System Interconnection Model)是一个由国际标准化组织(ISO)提出的概念模型,试图提供一个使各种不同的计算机和网络在世界范围内实现互联的标准框架。
它将计算机网络体系结构划分为七层,每层都可以提供抽象良好的接口。了解 OSI 模型有助于理解实际上互联网络的工业标准——TCP/IP 协议。
OSI 模型各层间关系和通讯时的数据流向如图所示: 
显然,如果一个东西想包罗万象、一般是不可能的;在实际的开发应用中一般是在此模型的基础上进行裁剪、整合!
七层模型介绍
七层模型小结 由于OSI是一个理想的模型,因此一般网络系统只涉及其中的几层,很少有系统能够具有所有的7层,并完全遵循它的规定。
在7层模型中,每一层都提供一个特殊的网络功能。从网络功能的角度观察:下面4层(物理层、数据链路层、网络层和传输层)主要提供数据传输和交换功能,即以节点到节点之间的通信为主;第4层作为上下两部分的桥梁,是整个网络体系结构中最关键的部分;而上3层(会话层、表示层和应用层)则以提供用户与应用程序之间的信息和数据处理功能为主。简言之,下4层主要完成通信子网的功能,上3层主要完成资源子网的功能。
TCP/IP分层模型
TCP/IP 协议族常用协议
应用层:TFTP,HTTP,SNMP,FTP,SMTP,DNS,Telnet 等等。
传输层:TCP,UDP。
网络层:IP,ICMP,OSPF,EIGRP,IGMP。
数据链路层(网络接口层):SLIP,CSLIP,PPP,MTU。
重要的 TCP/IP 协议族协议介绍如下:
IP(Internet Protocol,网际协议)是网间层的主要协议,任务是在源地址和和目的地址之间传输数据。IP 协议只是尽最大努力来传输数据包,并不保证所有的包都可以传输到目的地,也不保证数据包的顺序和唯一。
IP 定义了 TCP/IP 的地址,寻址方法,以及路由规则。现在广泛使用的 IP 协议有 IPv4 和 IPv6 两种:IPv4 使用 32 位二进制整数做地址,一般使用点分十进制方式表示,比如 192.168.0.1。
IP 地址由两部分组成,即网络号和主机号。故一个完整的 IPv4 地址往往表示为 192.168.0.1/24 或 192.168.0.1/255.255.255.0 这种形式。
IPv6 是为了解决 IPv4 地址耗尽和其它一些问题而研发的最新版本的 IP。使用 128 位整数表示地址,通常使用冒号分隔的十六进制来表示,并且可以省略其中一串连续的 0,如 fe80::200:1ff:fe00:1。目前使用并不多。
ICMP(Internet Control Message Protocol,网络控制消息协议)是 TCP/IP 的核心协议之一,用于在 IP 网络中发送控制消息,提供通信过程中的各种问题反馈。ICMP 直接使用 IP 数据包传输,但 ICMP 并不被视为 IP 协议的子协议。常见的联网状态诊断工具依赖于 ICMP 协议。
TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的,可靠的,基于字节流传输的通信协议。TCP 具有端口号的概念,用来标识同一个地址上的不同应用。
UDP(User Datagram Protocol,用户数据报协议)是一个面向数据报的传输层协议。UDP 的传输是不可靠的,简单的说就是发了不管,发送者不会知道目标地址的数据通路是否发生拥塞,也不知道数据是否到达,是否完整以及是否还是原来的次序。它同 TCP 一样有用来标识本地应用的端口号。所以应用 UDP 的应用,都能够容忍一定数量的错误和丢包,但是对传输性能敏感,比如流媒体、DNS 等。
ECHO(Echo Protocol,回声协议)是一个简单的调试和检测工具。服务器会原样回发它收到的任何数据,既可以使用 TCP 传输,也可以使用 UDP 传输。端口号为 7 。
DHCP(Dynamic Host Configration Protocol,动态主机配置协议)是用于局域网自动分配 IP 地址和主机配置的协议,可以使局域网的部署更加简单。
DNS(Domain Name System,域名系统)是互联网的一项服务,可以简单的将用“.”分隔的一般会有意义的域名转换成不易记忆的 IP 地址。一般使用 UDP 协议传输,也可以使用 TCP,默认服务端口号为53。
FTP(File Transfer Protocol,文件传输协议)是用来进行文件传输的标准协议。FTP 基于 TCP,使用端口号 20 来传输数据,21 来传输控制信息。
TFTP(Trivial File Transfer Protocol,简单文件传输协议)是一个简化的文件传输协议,其设计非常简单,通过少量存储器就能轻松实现,所以一般被用来通过网络传输小文件。
SSH(Secure Shell,安全Shell),因为传统的网络服务程序比如TELNET本质上都极不安全,明文传输数据和用户信息包括密码。SSH 被开发出来避免这些问题,它其实是一个协议框架,有大量的扩展冗余能力,并且提供了加密压缩的通道可以为其他协议使用。
POP(Post Office Protocol,邮局协议)是支持通过客户端访问电子邮件的服务,现在版本是 POP3,也有加密的版本 POP3S。协议使用 TCP,端口为110。
SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)是现在在互联网上发送电子邮件的事实标准。使用 TCP 协议传输,端口号为 25。
HTTP(Hyper Text Transfer Protocol,超文本传输协议)是现在广为流行的 WEB 网络的基础,HTTPS 是 HTTP 的加密安全版本。协议通过 TCP 传输,HTTP 默认使用端口 80,HTTPS 使用 443。
3次握手和4次挥手的过程
三次握手的过程
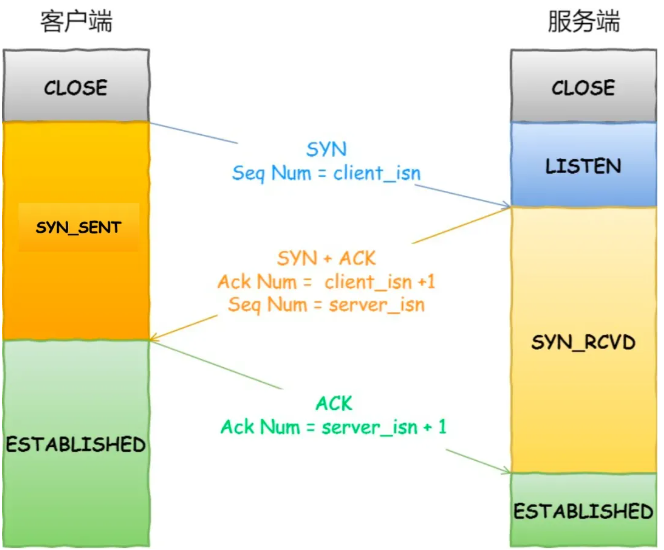
① CLOES(关闭状态);
② SYN(synchronous 建立连接请求);
③ ACK(acknowledgement 确认连接请求);
④ established(确认连接)
1、第⼀个SYN报文:
客户端随机初始化序列号client_isn,放进TCP⾸部序列号段, 然后把SYN置1。把SYN报文发送给服务端,表示发起连接, 之后客户端处于SYN-SENT状态。
2、第⼆个报文SYN+ACK报文:
服务端收到客户端的SYN报文,把自己的序号server_isn放进TCP首部序列号段, 确认应答号填⼊client_ins + 1,把SYN+ACK置1。 把SYN+ACK报⽂发送给客户端,然后进入SYNRCVD状态。
3、第三个报文ACK:
客户端收到服务端报⽂后,还要向服务端回应最后⼀个应答报⽂。
首先应答报文 TCP 首部 ACK 标志位置为 1 ,
其次「确认应答号」字段填入 server_isn + 1 ,
最后把报文发送给服务端, 这次报文可以携带客户到服务器的数据,之后客户端处于 ESTABLISHED 状态。 服务器收到客户端的应答报文后,也进入 ESTABLISHED 状态
三次握手的过程:
一开始,客户端和服务端都处于 CLOSED 状态。客户端主动打开连接,服务端被动打卡连接,结束CLOSED z状态,开始监听,进入 LISTEN状态。
一次握手
客户端会随机初始化序号(client_isn),将此序号置于 TCP 首部的「序号」字段中,同时把 SYN 标志位置为 1 ,表示 SYN 报文。
接着把第一个 SYN 报文发送给服务端,表示向服务端发起连接,该报文不包含应用层数据,之后客户端处于 SYN-SENT 状态。
二次握手
服务端收到客户端的 SYN 报文后,首先服务端也随机初始化自己的序号(server_isn),将此序号填入 TCP 首部的「序号」字段中;
其次把 TCP 首部的「确认应答号」字段填入 client_isn + 1, 接着把 SYN 和 ACK 标志位置为 1;
最后把该报文发给客户端,该报文也不包含应用层数据,之后服务端处于 SYN-RCVD 状态。
三次握手
客户端收到服务端报文后,还要向服务端回应最后一个应答报文,首先该应答报文 TCP 首部 ACK 标志位置为 1 ;
其次「确认应答号」字段填入 server_isn + 1 ;
最后把报文发送给服务端,这次报文可以携带客户到服务器的数据,之后客户端处于 ESTABLISHED 状态。
好了,经过三次握手的过程,客户端和服务端之间的确定连接正常,接下来进入ESTABLISHED状态,服务端和客户端就可以快乐地通信了。
为什么需要三次握手?
总结:
三次握手才可以防止重复历史连接的初始化(主因)
三次握手才可以同步双方的初始序列号
三次握手才可以避免资源浪费
TCP 四次挥手过程
具体过程:
假设客户端打算关闭连接,发送⼀个TCP首部FIN被置1的FIN报文给服务端。
服务端收到以后,向客户端发送ACK应答报文。
等待服务端处理完数据后,向客户端发送FIN报文。
客户端接收到FIN报文后回⼀个ACK应答报文。
服务器收到ACK报文后,进入close状态,服务器完成连接关闭。
客户端在经过 2MSL ⼀段时间后,自动进⼊close状态,客户端也完成连接的关闭。
为什么挥手需要四次?
关闭连接时,客户端发送FIN报文,表示其不再发送数据,但还可以接收数据。
客户端收到FIN报文,先回⼀个ACK应答报文,服务端可能还要数据需要处理和发送,
等到其不再发送数据时,才发送FIN报文给客户端表示同意关闭连接。
为什么 TIME_WAIT 等待的时间是 2MSL?
MSL是 Maximum Segment Lifetime,报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
等待MSL两倍:网络中可能存在发送⽅的数据包,当这些发送⽅的数据包被接收方处理后又会向对⽅发送响应,所以一来一回需要等待 2 倍的时间。
2MSL 的时间是从客户端接收到 FIN 后发送 ACK 开始计时的。
如果在 TIME-WAIT时间内,因为客户端的 ACK 没有传输到服务端,客户端又接收到了服务端重发的FIN 报文,那么 2MSL 时间将重新计时。
OSI七层模型与TCP/IP四层模型的对应关系
应用层(OSI模型第7层) 对应 应用层(TCP/IP模型第4层):提供用户接口,支持特定应用程序的协议和数据格式。
表示层(OSI模型第6层) 和 会话层(OSI模型第5层) 在TCP/IP模型中并没有明确的对应层次,这些功能通常由应用层协议自行处理。
传输层(OSI模型第4层) 对应 传输层(TCP/IP模型第3层):提供端到端的数据传输服务,确保数据的可靠性和流量控制。
网络层(OSI模型第3层) 对应 网络层(TCP/IP模型第2层):负责数据包的路由和转发,确保数据从源主机传输到目标主机。
数据链路层(OSI模型第2层) 和 物理层(OSI模型第1层) 在TCP/IP模型中合并为 网络接口层(TCP/IP模型第1层):处理物理介质和数据帧的传输。
网络协议之TCP、UDP

TCP:
相对较慢,但可靠
典型应用:文件传输
UDP:
速度快,但不可靠
典型应用:网络视频播放、DDoS攻击(bushi)
iftop动态的掌握服务器的流量情况
工具需要额外安装
yum install iftop -y用法
[root@server ~]# iftop
系统内置变量
设置变量与取消变量赋值set,unset
环境变量PATH
PATH,让你输入linux命令,系统优先去PATH中定义的目录中寻找,是否有该命令,有则执行,无则报错。
解读PATH变量
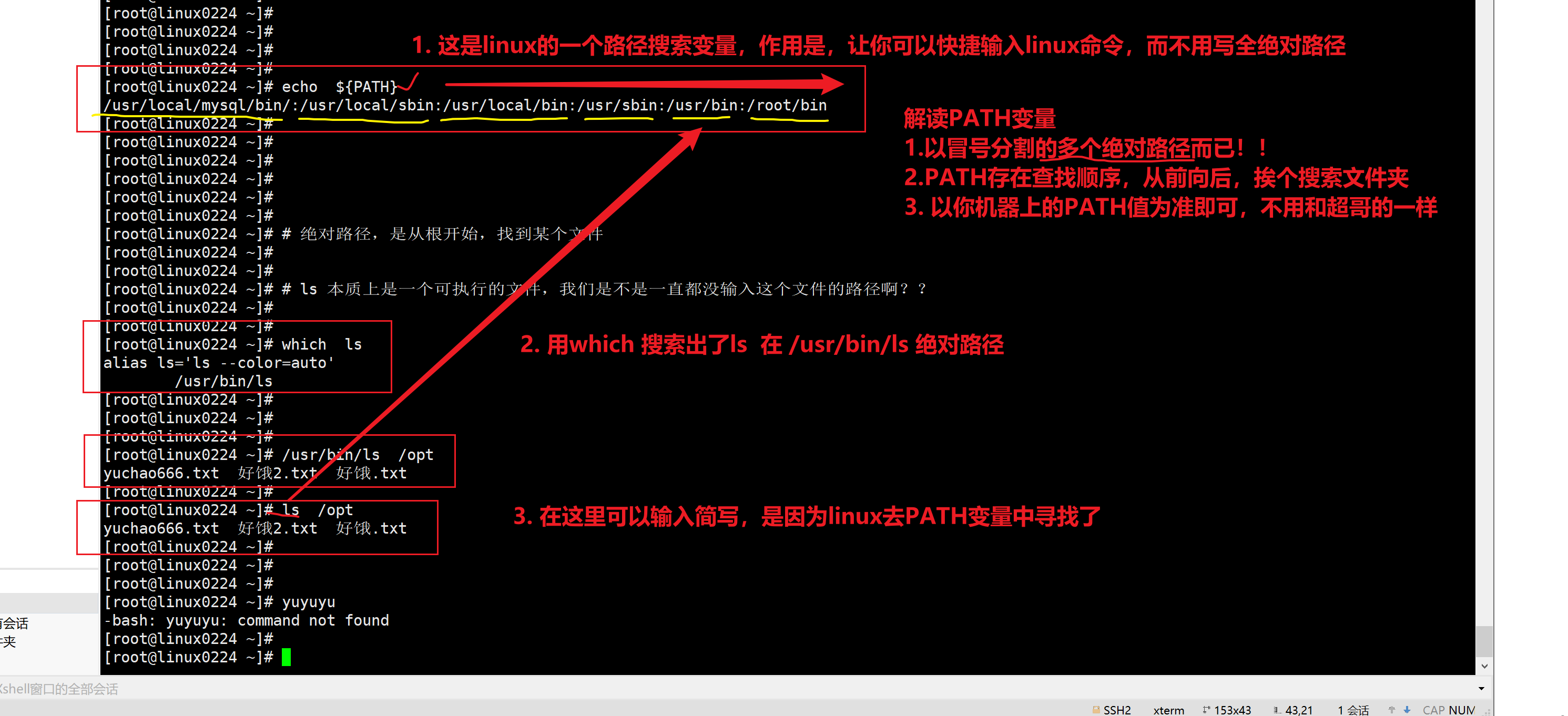
修改PATH变量
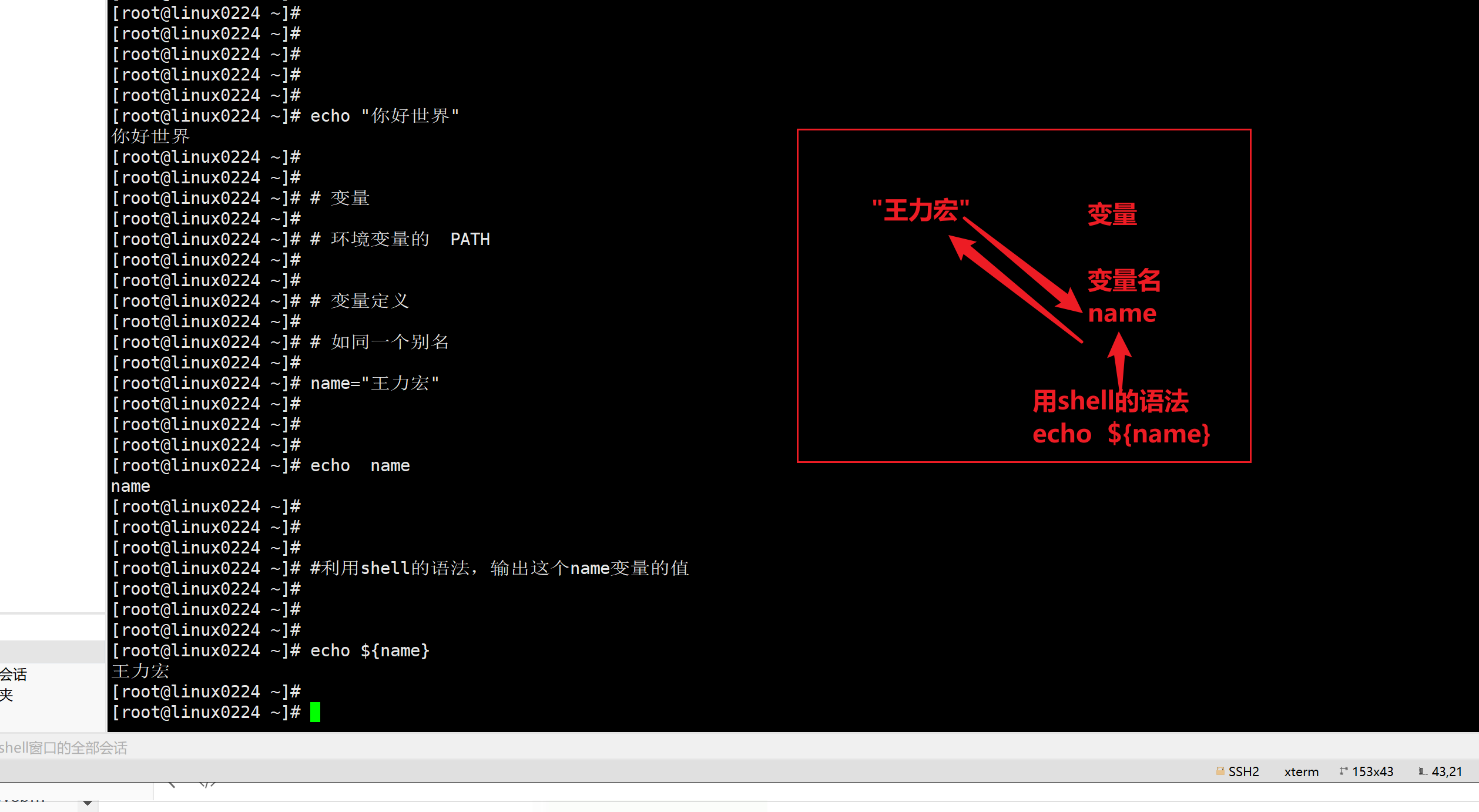
变量的取值
${变量名}
简单的shell脚本演示变量用法
[root@root ~]# vim hello.sh
[root@root ~]# cat hello.sh
name="心海!!!"
echo "我将点燃 ${name}"
echo "我将点燃 ${name}"
echo "我将点燃 ${name}"
#vim操作————奇巧淫技:在阅读模式下按两下y然后按p,复制光标所在句子。'yy->p'
#删除一行文字:dd
#撤销修改:u
#:wq(保存并退出)
[root@root ~]# bash hello.sh
我将点燃 心海!!!
我将点燃 心海!!!
我将点燃 心海!!!查看PATH值
[root@localhost ~]# echo ${PATH}
/usr/local/sbin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin查看ls命令所在文件夹
which ls
[root@localhost ~]# which ls
alias ls='ls --color=auto'
/bin/ls删除PATH里的ls路径,给PATH重新赋值即可
PATH=/usr/local/sbin:/sbin:/usr/sbin:/usr/bin:/root/bin
[root@localhost ~]# which ls
alias ls='ls --color=auto'
/usr/bin/ls
发现ls命令文件夹变成/usr/bin/了,继续删除。
PATH=/usr/local/sbin:/sbin:/usr/sbin:/root/bin
[root@localhost ~]# ls /opt/
bash: ls: command not found...
Similar command is: 'lz'
发现ls命令执行不了了,但可以写全ls路径执行ls命令。
[root@localhost ~]# /usr/bin/ls /opt/
rh修复PAHT变量,加入ls的那个目录
PATH="/usr/local/sbin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin"
[root@localhost ~]# ls /opt/
rh
好了成功执行。LANG变量(修改Linux中英文切换)
LANG ,系统中的变量,是有它的作用的,如这个LANG,可以修改系统的中英文字符集。
[root@root ~]# echo ${LANG}
en_US.UTF-8
[root@root ~]# LANG="zh_CN.UTF-8"PS1变量
# PS1变量是Linux系统中控制命令提示符的。
[root@localhost ~]# set | grep PS1
PS1='[\u@\h \W]\$ '
# 其中各参数含义:
\u 用户名
\h 主机名
\W 显示用户所处目录的最后一级
\w 显示用户所处的绝对路径
\t 以24小时制,显示时间
\$ 显示用户的身份提示符,自动识别root(#)还是普通用户($)
# 修改PS1,使用赋值法重新定义PS1变量即可
如何永久修改PS1变量⽣效?
分别演示root、和普通⽤户的配置。
在linux命令行中,变量的临时赋值操作,是临时生效,对当前ssh会话生效,用户切换,注销登录,变量都丢失
如果想永久生效,配置信息,写入到文件中(要求系统每次一登录就加载这个文件,实现永久生效)
针对整个系统的,全局的配置文件(所有root用户,以及普通用户,登录这个机器,都会加载这个文件)
/etc/profile针对用户个人的,该文件,存在于用户家目录下的,环境变量配置文件,名字是?
特点是,只有该用户,登录后,系统加载他的 /home/username家目录下的文件,方可生效
~/.bash_profile
PS1变量临时敲打临时生效,重新登录后系统重新加载用户用户环境变量,设置丢失,无法永久生效
1.写入到系统全局环境变量配置文件中 /etc/profile
2.写入到用户个人的配置文件(用户家目录下的.bash_profile文件)
RANDOM随机数变量
[root@localhost opt]# echo $RANDOM
20408
[root@localhost opt]#
[root@localhost opt]# echo $RANDOM
25104
[root@localhost opt]# echo $RANDOM
6836
[root@localhost opt]# echo `expr $RANDOM / 1000 `
19
[root@localhost opt]# echo `expr $RANDOM / 1000 `
27实例
生成5个随机数,并写入t2.txt文本中
[root@localhost opt]# for i in {1..5};do echo $(expr $RANDOM / 1000 ) ;done > t2.txt
[root@localhost opt]# cat t2.txt
9
31
10
24
32sort排序
用法
sort [选项]... [文件]...
或:sort [选项]... --files0-from=F参数
-b 忽略每行前面开始出的空格字符。
-c 检查文件是否已经按照顺序排序。
-d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
-f 排序时,将小写字母视为大写字母。
-i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
-m 将几个排序好的文件进行合并。
-M 将前面3个字母依照月份的缩写进行排序。
-n 依照数值的大小排序。
-u 意味着是唯一的(unique),输出的结果是去完重了的。
-o<输出文件> 将排序后的结果存入指定的文件。
-r 以相反的顺序来排序。
-t<分隔字符> 指定排序时所用的栏位分隔字符。
+<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
--help 显示帮助。
--version 显示版本信息。
[-k field1[,field2]] 按指定的列进行排序。
实例
从小到大排序
[root@localhost opt]# cat t2.txt |sort -n
9
10
24
31
32
从大到小排序
[root@localhost opt]# cat t2.txt |sort -n -r
32
31
24
10
9uniq去重
用法
uniq [选项]... [文件]
从输入文件或者标准输入中筛选相邻的匹配行并写入到输出文件或标准输出。参数
-c或--count 在每列旁边显示该行重复出现的次数。
-d或--repeated 仅显示重复出现的行列。
-f<栏位>或--skip-fields=<栏位> 忽略比较指定的栏位。
-s<字符位置>或--skip-chars=<字符位置> 忽略比较指定的字符。
-u或--unique 仅显示出一次的行列。
-w<字符位置>或--check-chars=<字符位置> 指定要比较的字符。
--help 显示帮助。
--version 显示版本信息。
[输入文件] 指定已排序好的文本文件。如果不指定此项,则从标准读取数据;
[输出文件] 指定输出的文件。如果不指定此选项,则将内容显示到标准输出设备(显示终端)。
实例
实例
从小到大排序,并去除重复的数据。
[root@localhost opt]# cat t1.txt |sort -n |uniq
0
1
3
5
8
11
12
13
14
15
19
21
22
27
28
29
31
32
从小到大排序,去除重复的数据并列出重复次数。
[root@localhost opt]# cat t1.txt |sort -n |uniq -c
2 0
2 1
1 3
2 5
1 8
2 11
3 12
2 13
1 14
1 15
1 19
4 21
1 22
1 27
1 28
2 29
2 31
1 32查看nginx访问IP数
[root@server ~]# grep -oE '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' /var/log/nginx/access.log |sort |uniq -c
1 101.200.78.64
2 103.41.52.94
1 106.185.47.161
2 113.240.250.155
260 13.0.782.215
2 185.130.5.231
26 192.168.10.16
6 192.168.10.17
148 192.168.10.2
189 192.168.10.202
270 192.168.10.222
25 192.168.10.235
291 192.168.10.3
12 192.168.10.5
2 23.251.63.45
20 7.0.11.0磁盘管理
磁盘是 Linux 系统中一项非常重要的资源,如何对其进行有效的管理直接关系到整个系统的性能问题 Linux 磁盘管理常用以下命令为 df、du 和 fdisk、lsblk、parted(容量>2T) 使用。
磁盘管理概念
硬件角度
存储的读写性能
固态硬盘、机械磁盘的抉择
存储的数据备份,数据安全性
raid磁盘阵列技术
存储的数据扩容,合理的磁盘容量管理,磁盘满了怎么办
软件角度
系统对存储的优化参数
数据库类软件的优化参数
任务背景
运维超哥突然接到公司的微信告警通知,说数据库服务器 根分区 磁盘使用率超过了85%、该机器主要存储博 客的用户文章、用户信息等数据。
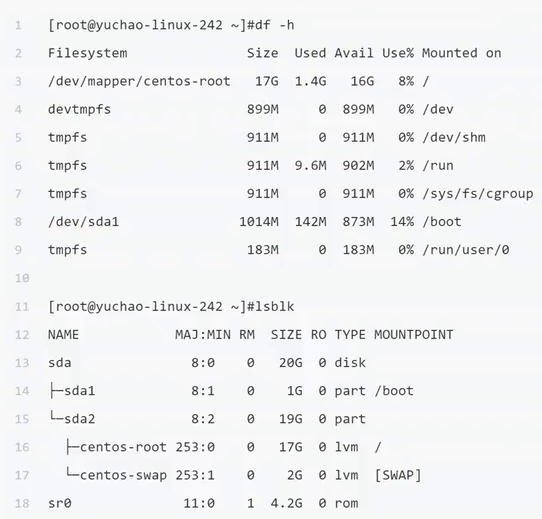
运维查看后,发现mysql的数据目录放在了 /usr/1ocal/mysql中,占用了根文件系统空间,经过研究讨论,决定把用户博客数据单独存放在另外一块磁盘里,并且实现逻辑卷管理。
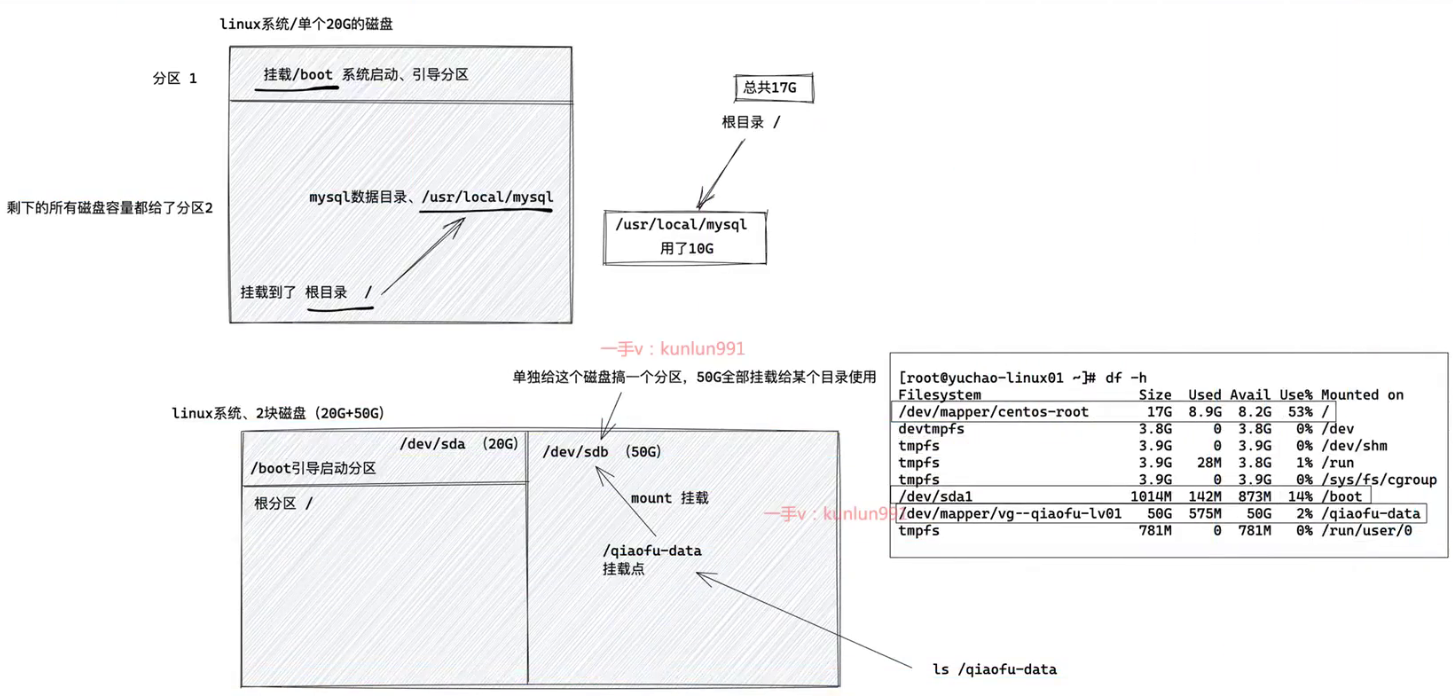
任务拆解
1,保证数据库数据完整的情况下,将用户数据,迁移到另外一块新硬盘中。 2,考虑到数据会不断增长,用户产生大量博客,新磁盘采用Ivm逻辑卷管理,方便日后动态扩容。
知识储备
1,需要一块新硬盘(虚拟机可添加) 2,新硬盘需要做lvm管理 3,数据库迁移(夜间停机维护 凌晨2点)
停止数据库监控
停止前端(关闭前端数据入口,比如停用博客发表功能)
停止后端(可选)
停止mysql数据库(防止数据还在写入、或者锁表)
备份数据库(全备)
迁移数据到新硬盘(rsync),新硬盘已经做好了Ivm,且挂载好了。
启动数据库
启动前端入口
测试数据读写
博客功能重新恢复上线。
打开数据库监控
新知识储备
添加新磁盘、以及后续磁盘配置命令。
Ivm逻辑卷管理。
学习目标
使用fdisk命令管理磁盘分区
格式化分区文件系统
磁盘分区挂载(手动、开机启动、自动挂载)
理解lvm原理
物理卷、卷组、逻辑卷
创建物理卷
创建卷组
创建逻辑卷
熟练掌握lvm的命令。
linux磁盘命名规则(重要)
不同硬盘(不同接口)插入到系统中,有不同的名字
多块硬盘的名字
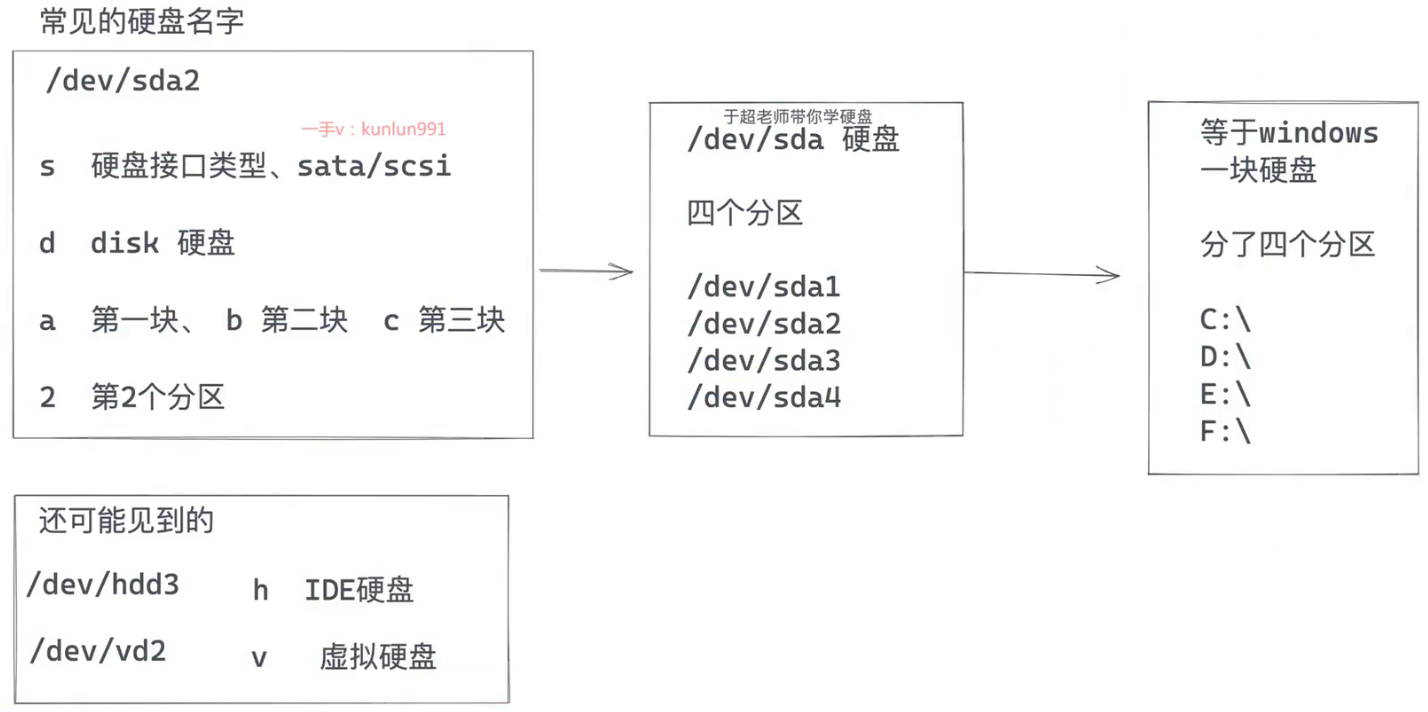
磁盘分区
MBR分区特点
不支持2T以上硬盘
最多支持4个主分区
fdisk命令只能创建MBR分区
实例
描述如下分区的具体含义
/dev/sda1
答:第一块硬盘的第一个主分区
/dev/sdb2
答:第二块硬盘的第二个主分区
/dev/sdc6
答:第三块硬盘的第二个逻辑分区
GPT分区特点
支持2T以上硬盘
GPT格式的磁盘相当于原来MBR磁盘中原来保留4个partition table的416个字节,只留第一个16个字节,类似于扩展分区,真正的partition table在512字节之后。
GPT分区方式没有四个主分区的限制,最多可达到128个主分区。
parted工具可以划分单个分区大于2T的GPT格式的分区,也可以划分普通的MBR分区。
查看分区命令
fdisk命令
fdisk是Linux 的磁盘分区表操作工具。
-l: 输出后面接的装置所有的分区内容。若仅有fdisk -l 时,则系统将会把整个系统内能够搜寻到的装置的分区均列出来。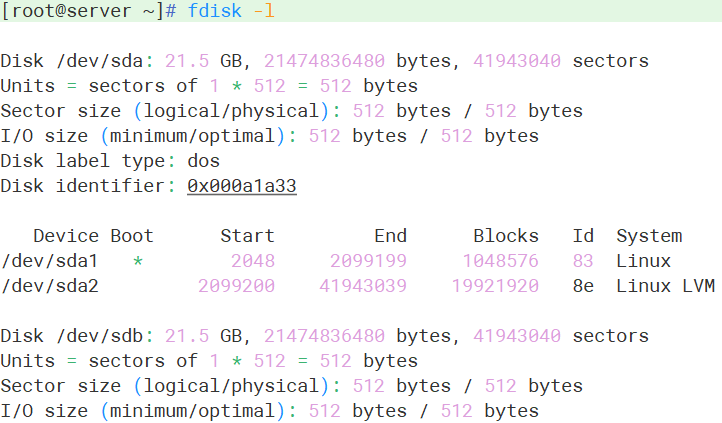
lsblk,ls /dev/sd*命令
此外还可以使用如下命令查看当前系统有哪些分区
lsblk
ls /dev/sd*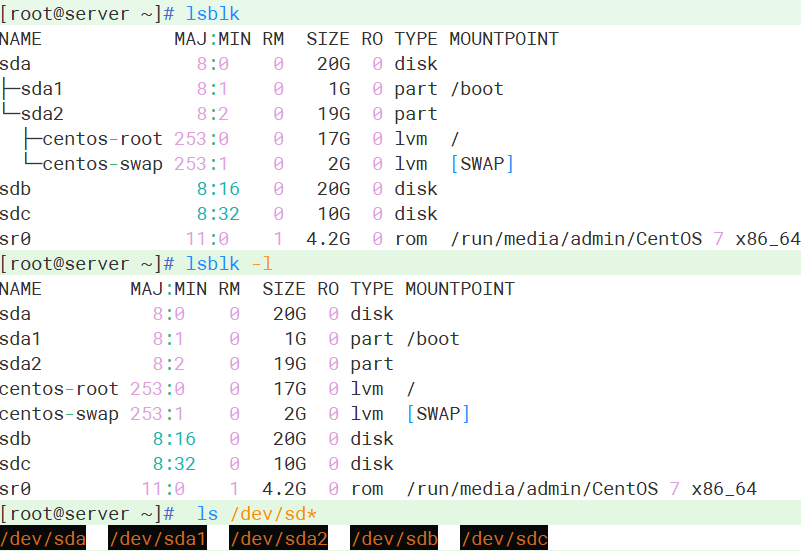
磁盘分区步骤
执行
fdisk /dev/sdb命令,给硬盘创建分区/dev/sdb1、/dev/sdb2.刷新分区表
格式化分区文件系统、
mkfs.ext4/dev/sdb1挂载使用该分区,
mount开机自动挂载、autofs自动挂载
磁盘分区结构(重要)
主分区
一个硬盘的主分区也就是包含操作系统启动所必需的文件和数据的硬盘分区,要在硬盘上安装操作系统,则该硬盘必须得有一个主分区。
主分区,也称为主磁盘分区,和扩展分区、逻辑分区一样,是一种分区类型。
主分区中不能再划分其他类型的分区。
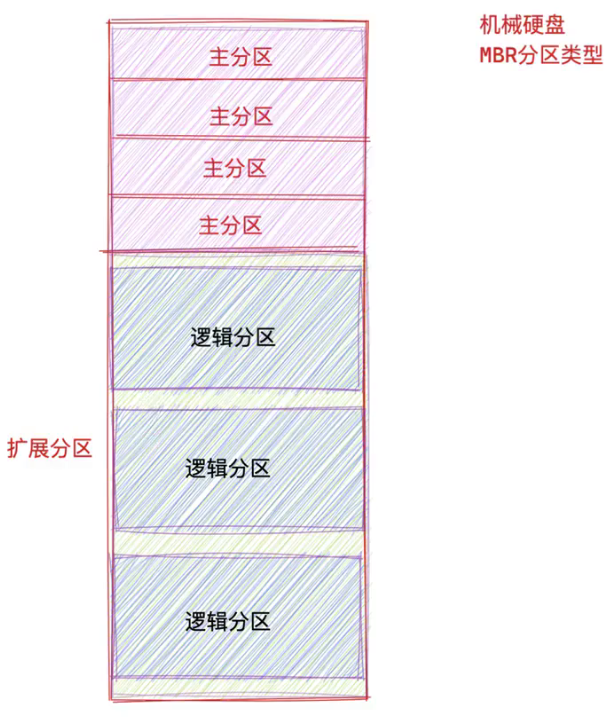
扩展分区/逻辑分区
扩展分区也就是除主分区外的分区,但它不能直接使用,必须再将它划分为若干个逻辑分区才行。
逻辑分区也就是我们平常在操作系统中所看到的D、E、F等盘。
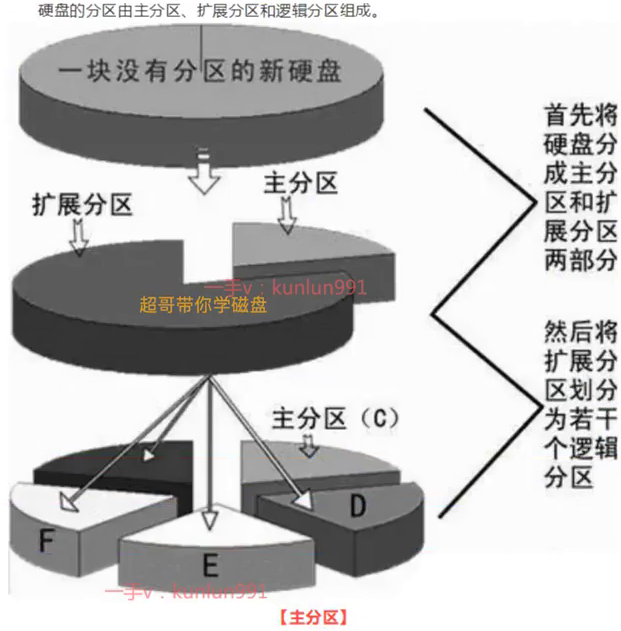
主分区,primary partitic
扩展分区,extended
逻辑分区
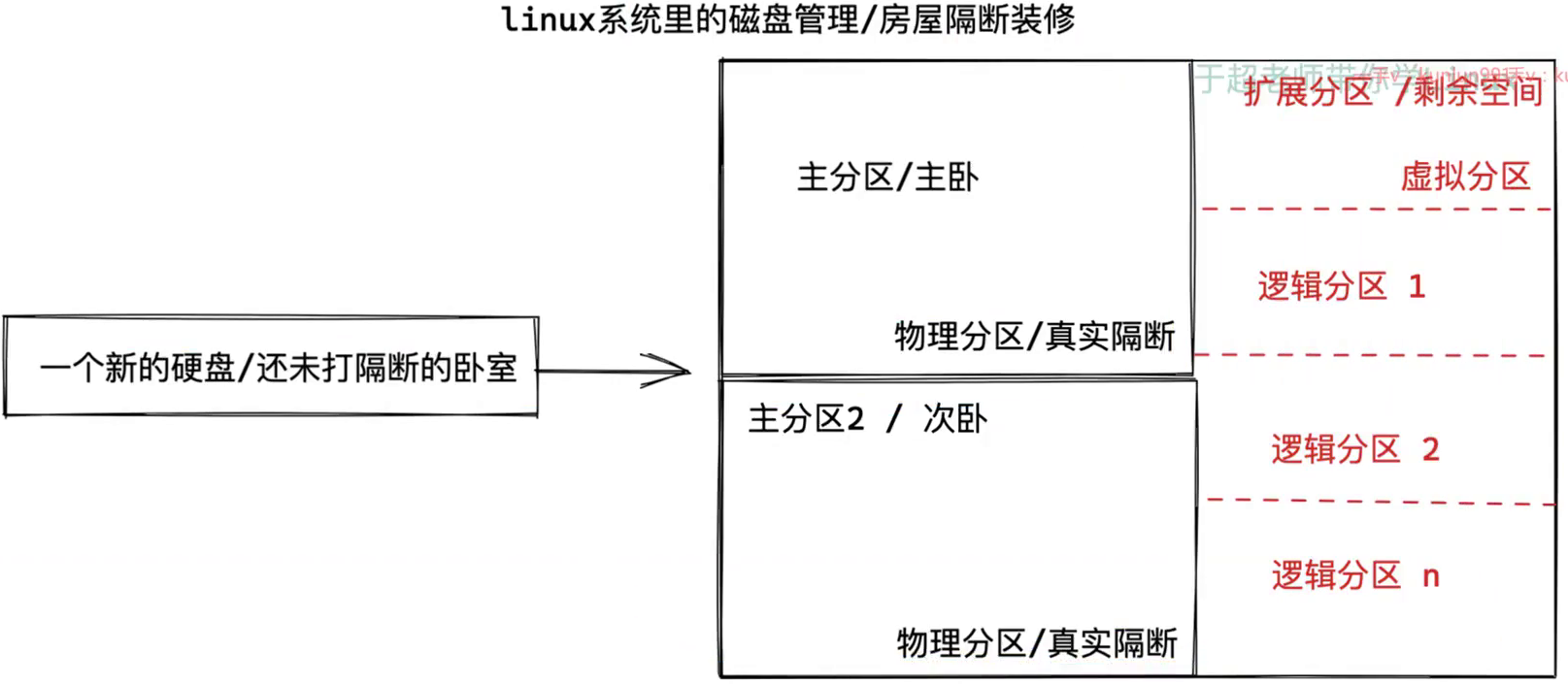
系统默认分区1~4留给了主分区和扩展分区
主分区1 *(星号代表是引导分区,引导分区装在这里)
主分区2
主分区3
主分区4(extended)
逻辑分区n
分区须知(记忆)
最多只能分4个主分区,主分区编号1-4
逻辑分区大小总和不能超过扩展分区大小,逻辑分区分区编号从5开始
如果删除扩展分区,下面的逻辑卷分区也被删除
扩展分区的分区编号(1-4)
fdisk分区实战(MBR)
任务:将sdb硬盘分区(20G)
1个主分区 (2G)
1个扩展分区 (剩下的全给他) 18G
2个逻辑分区
逻辑分区1,10G
逻辑分区2,剩下的都给他 8G
分区参数解释
Command (m for help): m 输出帮助信息
Command action
a toggle a bootable flag 设置启动分区
b edit bsd disklabel 编辑分区标签
c toggle the dos compatibility flag 切换dos兼容性标志
d delete a partition 删除一个分区
g create a new empty GPT partition table 创建新的GPT分区表
G create an IRIX (SGI) partition table
l list known partition types 列出分区类型
m print this menu 帮助
n add a new partition 建立一个新的分区
o create a new empty DOS partition table 创建一个新的空白DOS分区表
p print the partition table 打印分区表
q quit without saving changes 退出不保存设置
s create a new empty Sun disklabel 创建一个新的空的SUN标示
t change a partition's system id 修改分区id
u change display/entry units 修改容量单位
v verify the partition table 检查验证分区表
w write table to disk and exit 保存分区表
x extra functionality (experts only) 额外功能(仅限专家)开始分区
[root@server ~]# fdisk /dev/sdb
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table
Building a new DOS disklabel with disk identifier 0xdfe91351.
Command (m for help): p
Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0xdfe91351
Device Boot Start End Blocks Id System
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p): p #主分区
Partition number (1-4, default 1): 1
First sector (2048-41943039, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-41943039, default 41943039): +2G
Partition 1 of type Linux and of size 2 GiB is set
Command (m for help): p
Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0xdfe91351
Device Boot Start End Blocks Id System
/dev/sdb1 2048 4196351 2097152 83 Linux
Command (m for help): n
Partition type:
p primary (1 primary, 0 extended, 3 free)
e extended
Select (default p): e #扩展分区
Partition number (2-4, default 2):
First sector (4196352-41943039, default 4196352):
Using default value 4196352
Last sector, +sectors or +size{K,M,G} (4196352-41943039, default 41943039):
Using default value 41943039
Partition 2 of type Extended and of size 18 GiB is set
Command (m for help): p
Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0xdfe91351
Device Boot Start End Blocks Id System
/dev/sdb1 2048 4196351 2097152 83 Linux
/dev/sdb2 4196352 41943039 18873344 5 Extended
Command (m for help): n
Partition type:
p primary (1 primary, 1 extended, 2 free)
l logical (numbered from 5)
Select (default p): l #逻辑分区1
Adding logical partition 5
First sector (4198400-41943039, default 4198400):
Using default value 4198400
Last sector, +sectors or +size{K,M,G} (4198400-41943039, default 41943039): +10G
Partition 5 of type Linux and of size 10 GiB is set
Command (m for help): p
Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0xdfe91351
Device Boot Start End Blocks Id System
/dev/sdb1 2048 4196351 2097152 83 Linux
/dev/sdb2 4196352 41943039 18873344 5 Extended
/dev/sdb5 4198400 25169919 10485760 83 Linux
Command (m for help): n
Partition type:
p primary (1 primary, 1 extended, 2 free)
l logical (numbered from 5)
Select (default p): l #逻辑分区2
Adding logical partition 6
First sector (25171968-41943039, default 25171968):
Using default value 25171968
Last sector, +sectors or +size{K,M,G} (25171968-41943039, default 41943039):
Using default value 41943039
Partition 6 of type Linux and of size 8 GiB is set
Command (m for help): p
Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0xdfe91351
Device Boot Start End Blocks Id System
/dev/sdb1 2048 4196351 2097152 83 Linux
/dev/sdb2 4196352 41943039 18873344 5 Extended
/dev/sdb5 4198400 25169919 10485760 83 Linux
/dev/sdb6 25171968 41943039 8385536 83 Linux
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.查看分区情况
[root@server ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 19G 0 part
├─centos-root 253:0 0 17G 0 lvm /
└─centos-swap 253:1 0 2G 0 lvm [SWAP]
sdb 8:16 0 20G 0 disk
├─sdb1 8:17 0 2G 0 part #主分区
├─sdb2 8:18 0 1K 0 part #扩展分区
├─sdb5 8:21 0 10G 0 part #逻辑分区1
└─sdb6 8:22 0 8G 0 part #逻辑分区2
sdc 8:32 0 10G 0 disk
sr0 11:0 1 4.2G 0 rom /run/media/admin/CentOS 7 x86_64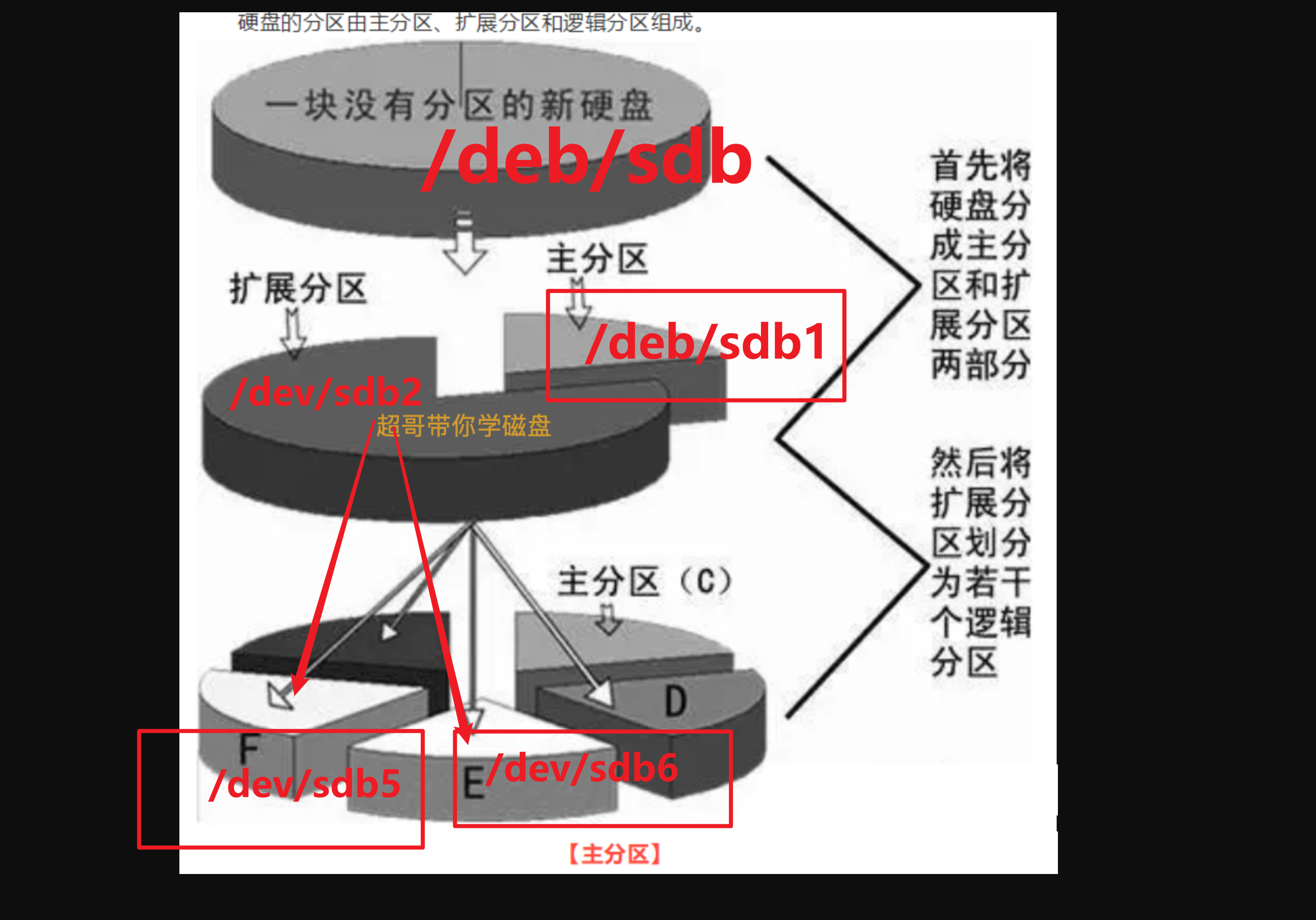
partx重读分区表
当你fdisk分区完了之后,看不到分区的信息,是因为linux内核,还未更新分区表得使用命令,重新读取磁盘的分区
[root@server ~]# partx /dev/sdb
NR START END SECTORS SIZE NAME UUID
1 2048 4196351 4194304 2G
2 4196352 41943039 37746688 18G
5 4198400 25169919 20971520 10G
6 25171968 41943039 16771072 8G partprobe命令也能更新系统的分区表的变化
查看磁盘的分区表类型
[root@server ~]# fdisk -l /dev/sdb
Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos # 看到dos就是mbr类型
Disk identifier: 0xa07c9f25
Device Boot Start End Blocks Id System
/dev/sdb1 2048 4196351 2097152 83 Linux
/dev/sdb2 4196352 41943039 18873344 5 Extended
/dev/sdb5 4198400 25169919 10485760 83 Linux
/dev/sdb6 25171968 41943039 8385536 83 Linuxparted命令(MBR & GPT)
我这里删除了/dev/sdb磁盘的所有分区,使用的是20G的硬盘模拟,同学们可以自己添加新硬盘。
gpt分区表,没有扩展分区的类型,只有主分区、逻辑分区。
可以用parted命令对磁盘分区为GPT,但是比较麻烦
可以用parted命令,修改磁盘分区表类型(gpt改为mbr)
fdisk命令是专门针对mbr分区格式的,无法操作GPT格式硬盘。
是使用parted命令,可以修改硬盘的分区表类型
msdos #这是mbr类型的名字
mklabel msdos
mktable msdos
gpt #这是GUID分区表的类型名字
mklabel gpt
mktable gpt[root@server ~]# parted /dev/sdb
GNU Parted 3.1
Using /dev/sdb
Welcome to GNU Parted! Type 'help' to view a list of
commands.
(parted) mklabel gpt
Warning: The existing disk label on /dev/sdb will be
destroyed and all data on this disk will be lost. Do
you want to continue?
Yes/No? yes #修改当前硬盘的分区表类型,改为gpt,注意如下操作会摧毁原有的数据
(parted) print #使用print指令,查看分区表信息,以及分区表类型
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdb: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags[root@server ~]# fdisk -l /dev/sdb
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt #可以看到磁盘分区类型已经变为gpt类型了
Disk identifier: 39087ADD-14A3-4099-A069-05DF71624BEA因为parted没有太多交互式的提醒,不用它进行分区了,换为gdisk命令去操作超过2TB的硬盘分区动作。
gdisk命令(GPT)
安装gdisk工具
yum install gdisk -y列出硬盘分区信息
[root@server ~]# gdisk -l /dev/sdb
GPT fdisk (gdisk) version 0.8.10
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present任务:将sdb硬盘分区(20G)
1个主分区 (5G)
1个扩展分区 (剩下的全给他) 15G
2个逻辑分区
逻辑分区1,10G
逻辑分区2,剩下的都给他 5G
分区参数解释
Command (? for help): ?
b back up GPT data to a file 将GPT数据备份到一个文件
c change a partition's name 更改分区名称
d delete a partition 删除一个分区
i show detailed information on a partition 显示分区详细信息
l list known partition types 列出已知分区类型
n add a new partition 增加一个新的分区
o create a new empty GUID partition table (GPT) 创建一个新的空白的GPT分区表
p print the partition table 显示当前磁盘的分区表
q quit without saving changes 退出gdisk程序,不保存任何修改
r recovery and transformation options (experts only) 恢复和转换选项(仅限专家)
s sort partitions 排序分区
t change a partition's type code 改变分区的类型
v verify disk 验证磁盘分区表
w write table to disk and exit 将分区表保存并退出
x extra functionality (experts only) 额外功能(仅限专家)
? print this menu 显示帮助信息开始分区
[root@server ~]# gdisk /dev/sdb #设备文件
GPT fdisk (gdisk) version 0.8.10
Partition table scan:
MBR: not present
BSD: not present
APM: not present
GPT: not present
Creating new GPT entries.
Command (? for help): n #新建分区
Partition number (1-128, default 1): #选择第几个分区,默认按顺序分区,enter确认
First sector (34-41943006, default = 2048) or {+-}size{KMGTP}:
Last sector (2048-41943006, default = 41943006) or {+-}size{KMGTP}: +5G #选择容量
Current type is 'Linux filesystem'
Hex code or GUID (L to show codes, Enter = 8300): L #列出分区类型,这里默认就行enter确认
Press the <Enter> key to see more codes: 8300
ef00 EFI System ef01 MBR partition scheme ef02 BIOS boot partition
fb00 VMWare VMFS fb01 VMWare reserved fc00 VMWare kcore crash p
fd00 Linux RAID
Hex code or GUID (L to show codes, Enter = 8300):
Changed type of partition to 'Linux filesystem'
Command (? for help): p
Disk /dev/sdb: 41943040 sectors, 20.0 GiB
Logical sector size: 512 bytes
Disk identifier (GUID): 39087ADD-14A3-4099-A069-05DF71624BEA
Partition table holds up to 128 entries
First usable sector is 34, last usable sector is 41943006
Partitions will be aligned on 2048-sector boundaries
Total free space is 20971453 sectors (10.0 GiB)
Number Start (sector) End (sector) Size Code Name
1 2048 20973567 10.0 GiB 8300 Linux filesystem
Command (? for help): n
Partition number (2-128, default 2):
First sector (34-41943006, default = 20973568) or {+-}size{KMGTP}:
Last sector (20973568-41943006, default = 41943006) or {+-}size{KMGTP}: +5G
Current type is 'Linux filesystem'
Hex code or GUID (L to show codes, Enter = 8300):
Changed type of partition to 'Linux filesystem'
Command (? for help): p
Disk /dev/sdb: 41943040 sectors, 20.0 GiB
Logical sector size: 512 bytes
Disk identifier (GUID): 39087ADD-14A3-4099-A069-05DF71624BEA
Partition table holds up to 128 entries
First usable sector is 34, last usable sector is 41943006
Partitions will be aligned on 2048-sector boundaries
Total free space is 10485693 sectors (5.0 GiB)
Number Start (sector) End (sector) Size Code Name
1 2048 20973567 10.0 GiB 8300 Linux filesystem
2 20973568 31459327 5.0 GiB 8300 Linux filesystem
Command (? for help): n
Partition number (3-128, default 3):
First sector (34-41943006, default = 31459328) or {+-}size{KMGTP}:
Last sector (31459328-41943006, default = 41943006) or {+-}size{KMGTP}:
Current type is 'Linux filesystem'
Hex code or GUID (L to show codes, Enter = 8300):
Changed type of partition to 'Linux filesystem'
Command (? for help): p
Disk /dev/sdb: 41943040 sectors, 20.0 GiB
Logical sector size: 512 bytes
Disk identifier (GUID): 39087ADD-14A3-4099-A069-05DF71624BEA
Partition table holds up to 128 entries
First usable sector is 34, last usable sector is 41943006
Partitions will be aligned on 2048-sector boundaries
Total free space is 2014 sectors (1007.0 KiB)
Number Start (sector) End (sector) Size Code Name
1 2048 20973567 10.0 GiB 8300 Linux filesystem
2 20973568 31459327 5.0 GiB 8300 Linux filesystem
3 31459328 41943006 5.0 GiB 8300 Linux filesystem
Command (? for help): w #保存并退出
Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING
PARTITIONS!!
Do you want to proceed? (Y/N): y #再次确认是否以GPT类型写入分区表
OK; writing new GUID partition table (GPT) to /dev/sdb.
The operation has completed successfully.查看分区情况
[root@server ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 19G 0 part
├─centos-root 253:0 0 17G 0 lvm /
└─centos-swap 253:1 0 2G 0 lvm [SWAP]
sdb 8:16 0 20G 0 disk
├─sdb1 8:17 0 10G 0 part
├─sdb2 8:18 0 5G 0 part
└─sdb3 8:19 0 5G 0 part
sdc 8:32 0 10G 0 disk
sr0 11:0 1 4.2G 0 rom /run/media/admin/CentOS 7 x86_64mkfs命令格式化文件系统
文件系统分类
目前常见的系统平台就3类,分别是微软的 Windows,苹果的 macOS ,开源社区的 Linux,每个操作系统都有设计
自己的文件系统,以本文讨论的几款文件系统来说,他们的归属如下:
不同文件系统的区别
总之不同的文件系统,区别在于
兼容性,不同系统平台,不一定识别、或者无法读写操作。
我们经常需要跨平台工作,例如从 Win10 拷贝个文件到U盘,然后插入到 Mac Book中,或者 Linux 电脑中,这时候如果U盘的文件系统兼容性不够好,就会导致有的平台能识别U盘的文件,有的电脑无法识别。
不同系统之间的文件系统不兼容,就得通过一些第三方工具来实现读写,否则可能只能读取,无法写入。
容量大小、支持硬盘最大容量有限制。
利用mkfs命令进行分区,格式化文件系统
操作步骤
1.把机器上的/dev/sdc硬盘,重新分区一个单个分区,是10G
fdisk /dev/sdc
2.给这个分区,格式化为xfs文件系统
mkfs.xfs /dev/sdc1
3.挂载一个目录`/opt/my_sdc1`,到这个分区,即可使用该分区,存储数据了
[root@server ~]# mkdir /opt/my_sdc1
[root@server ~]# mount /dev/sdc1 /opt/my_sdc1
4.查看挂载情况
mount -l
[root@server ~]# mount -l |grep sdc1
/dev/sdc1 on /opt/my_sdc1 type xfs (rw,relatime,attr2,inode64,noquota)
5.设置永久挂载
上述的mount挂载命令是临时生效,需要开机就让系统自动挂载,方可实现,永久生效
编辑`/etc/fstab`文件即可
vim /etc/fstab
/dev/sdc1 /opt/my_sdc xfs defaults 0 0
6.重启机器,查看是否开机就能自动挂载,读取到/dev/sdc1磁盘的数据
再次使用 mount -l |grep sdc 查看磁盘的挂载情况
以及去访问挂载点,是否能读到分区的数据即可。磁盘挂载与卸载
挂载原理
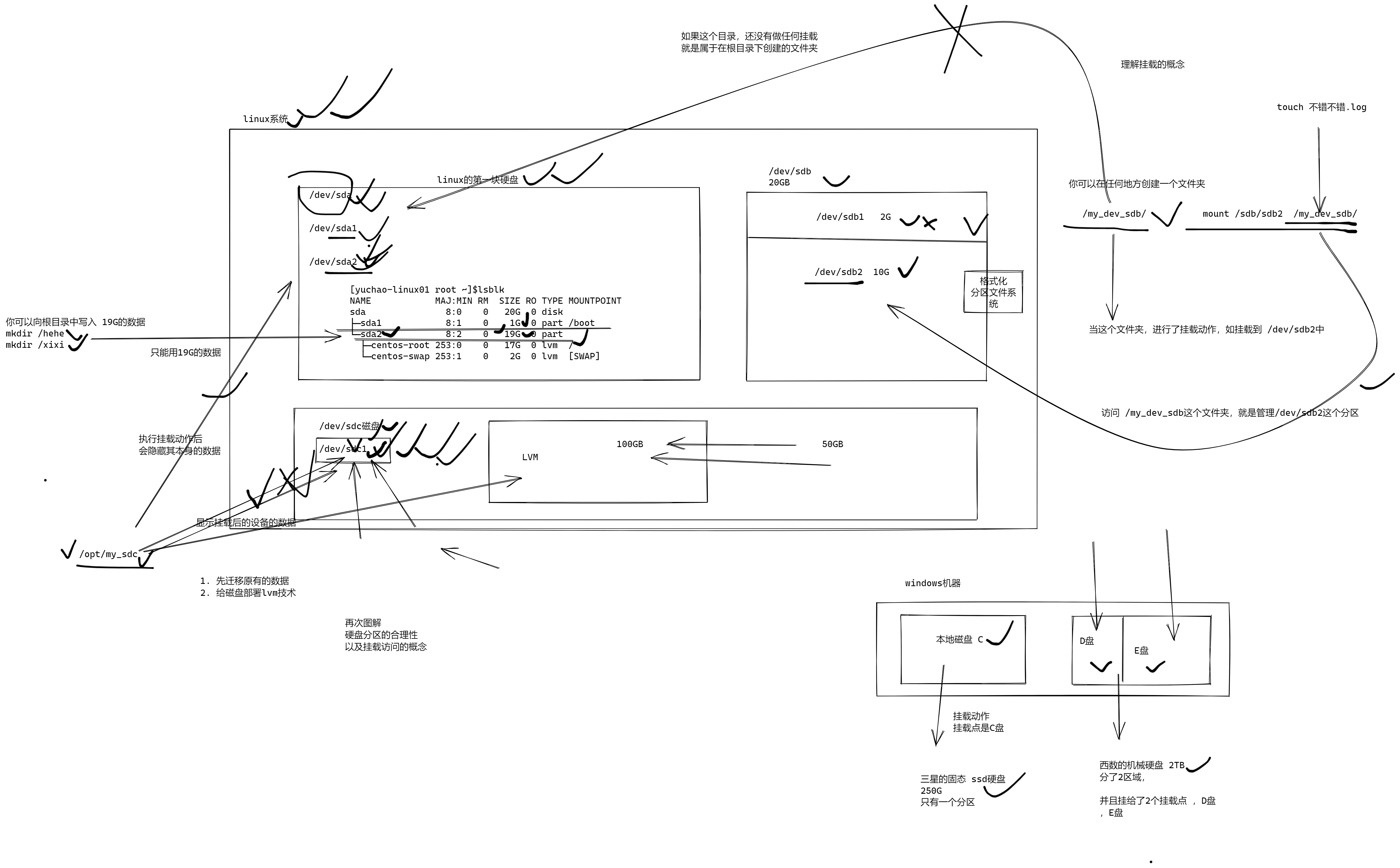
mount命令
挂载语法:
mount [硬件名] [挂载点]
mount /dev/sdb1 /mnt/sdb1选项
语法:
mount [选项]
-a 加载文件/etc/fstab中设置的所有设备。
-f 不实际加载设备。可与-v等参数同时使用以查看mount的执行过程。
-F 需与-a参数同时使用。所有在/etc/fstab中设置的设备会被同时加载,可加快执行速度。
-h 显示在线帮助信息。
-L<标签> 加载文件系统标签为<标签>的设备。
-l 显示已加载的文件系统列表(同直接执行mount)
-n 不将加载信息记录在/etc/mtab文件中。
-o<选项> 指定加载文件系统时的选项。有些选项也可在/etc/fstab中使用。
-r 以只读方式加载设备。
-t<文件系统类型> 指定设备的文件系统类型。
-v 执行时显示详细的信息。
-V 显示版本信息。
-w 以可读写模式加载设备,默认设置。mount -o选项详解
挂载光盘文件
mount -o loop tstack-v6.2-hygon-20220608-2258.iso /tmp umount命令
卸载挂载
umount [硬件名]
umount /dev/sdb1fstab文件设置永久挂载
文件路径/etc/fatab
设置永久挂载(开机挂载)
vim /etc/fatab
方法一:设备名挂载
/dev/sdc1 /opt/my_sdc xfs defaults 0 0
#要挂载的硬盘名 #挂载点 #文件格式 #挂载参数
方法二:设备UUID挂载
#查看UUID
blkid /dev/sdc1
UUID=c07b71e0-a0a4-41e5-9c12-24646b84c73f /opt/my_sdc xfs defaults 0 0磁盘后期管理命令
df命令
df(全称:disk free):列出文件系统中的整体磁盘使用量。查看磁盘挂载之后的信息。
第一列表示系统文件系统对应的设备文件的路径名(一般是硬盘上的分区);
第二列给出分区包含的数据块(1024字节)的数据;
第三、四列分别表示已用的和可用的数据块数目。
Mountted on列表示文件系统的安装点。
具体参数
-a: 显示所以文件系统的磁盘使用情况,包括0块(block)的系统文件系统,如/proc文件系统。
-k: 以k字节为单位显示。
-i: 显示i节点信息,而不是磁盘块。
-t: 显示各指定类型的文件系统的磁盘空间使用情况。
-x: 列出不是某一指定类型文件系统的磁盘的空间使用情况(与t选项相反)
-T: 显示文件系统类型。
-h: 表示以高可读性的形式进行显示,如果不写-h,默认以KB的形式显示文件大小。常用选项
-h -T
du命令
du (英文全称: disk usage) :显示磁盘空间的使用情况,统计目录(或文件)所占磁盘空间的大小。该命令的功能是逐级进入指定目录的每一个子目录并显示该目录占用文件系统数据块(1024 字节)的情况。若没有给出指定目录,则对当前目录进行统计。
具体参数
-s: 查看该目录下总的文件大小。#du命令默认加上-s
-a: 递归地显示指定目录中各文件及子目录中各文件占用的数据块数。若既不指定-s也不指定-a,则只显示每一个目录及 其中的各子目录所占的磁盘块数。
-b: 以字节为单位列出磁盘空间使用情况(系统默认以k字节为单位)。
-k: 以1024字节为单位列出磁盘空间使用情况。
-c: 最后再加上一一个总计(系统默认设置)。
-h: 表示以高可读性的形式进行显示,如果不写-h,默认以KB的形式显示文件大小。常用选项
du -sh ./*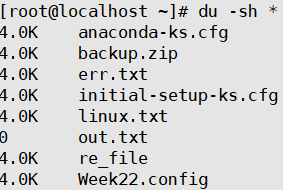
du -ah ./* #递归查看例题查找大文件或目录
du -ahx .|sort -rh |head -5blkid命令
blkid 命令用于显示块设备的标识信息,例如文件系统类型、UUID、标签等。以下是使用 blkid 命令的一些常见用法:
显示设备的标识信息
要查看特定设备的标识信息,可以执行以下命令:
[root@server ~]# blkid /dev/sda1
/dev/sda1: UUID="436692f9-2c62-49a3-a236-69ea7da7a6db" TYPE="xfs"
[root@server ~]# blkid /dev/sdc
/dev/sdc: PTTYPE="dos" Raid磁盘冗余阵列
概念
RAID,全称为RedundantArrays ofIndependent Drives,即磁盘冗余阵列。
这是由多块独立磁盘(多为硬盘)组合的一个超大容量磁盘组。
计算机一直是在飞速的发展,更新,整体计算机硬件也得到极大的提升,由于磁盘的特性,需要持续、频繁、大量的读写操作,相比较于其他硬件设备,很容易损坏,导致数据丢失。
图解Raid

不同的Raid级别
Raid 0
RAID0磁盘总容量
将两个或两个以上相同型号容量的硬盘组合,磁盘阵列的总容量便是多个硬盘的总和。
RAID 0的特点:
至少需要两块磁盘
数据条带化分布到磁盘,高的读写性能,100%高存储空间利用率。
数据没有冗余策略,一块磁盘故障,数据将无法恢复。
应用场景:
对性能要求高但对数据安全性和可靠性要求不高的场景,比如音频、视频等的存储。
备注
条带化技术就是一种自动的将I/0的负载均衡到多个物理磁盘上的技术
磁盘条带化是指利用条带化技术就是将一块连续的数据分成很多小部分并把它们分别存储到不同磁盘上去。
数据 依次 写入物理硬盘,理想状态下,硬盘读写性能会翻倍,性能大于单个硬盘。
但是raid 0任意一块硬盘故障都会导致整个系统数据被破坏,数据分别写入两个硬盘设备,没有数据备份的功能。
raid 0使用场景
Raid 0 适用于对于数据安全性不太关注,追求性能的场景。
好比你有一些小秘密,不想放云盘,数据量又比较大,可以快速写入raid 0。
本来读写都是一块硬盘,数据都得排队,效率肯定低
raid0把数据打散,好比多了条队同时排,效率一下子就提升了,因此raid 0可以大幅度的提升,硬盘的读写能力。
Raid 1
由于Raid 0的特性,数据依次写入到各个物理硬盘中,数据是分开放的,因此损坏任意一个硬盘,都会对完整的数据破坏,对于企业数据来说,肯定是不允许。
Raid 1技术,是将 两块以上 硬盘绑定,数据写入时,同时写入多个硬盘,因此即使有硬盘故障,也有数据备份。
但是这种方式,无疑极大降低磁盘利用率,假设两块硬盘一共4T,真实数据只有2TB,利用率50%,如果是三块硬盘组成raid1,利用率只有33%,也是不可取的。
Raid 1的特点:
至少需要2块磁盘。
数据镜像备份写到磁盘上(工作盘和镜像盘),可靠性高,磁盘利用率为50%。
读性能可以,但写性能不佳,写入数据要同步,因此速度很慢。
一块磁盘故障,不会影响数据的读写,因为是镜像盘,冗余性好,只要有一块是好的,数据还是玩转的。
应用场景:
对数据安全可靠要求较高的场景,比如邮件系统、交易系统等。
Raid 5
RAID5特点:
至少需要3块磁盘。
数据条带化存储在磁盘,读写性能好,磁盘利用率为(n-1)/n。
一块磁盘故障,可根据其他数据块和对应的校验数据重构损坏数据(消耗性能)。
校验算法是计算机二进制的的异或运算(了解即可)。
只能允许坏掉一块盘。
是目前综合性能最佳的数据保护解决方案。
兼顾了存储性能、数据安全和存储成本等各方面因素(性价比高)。
适用于大部分的应用场景。
可以看到raid 5 是两两数据就会计算出一个校验值,存储在一个硬盘上。
如果遇见磁盘损坏,且只能挂掉一块,还是可以用其他磁盘恢复数据的。
Raid 6
比起raid5提供的数据校验,又多了一层校验,双层校验。
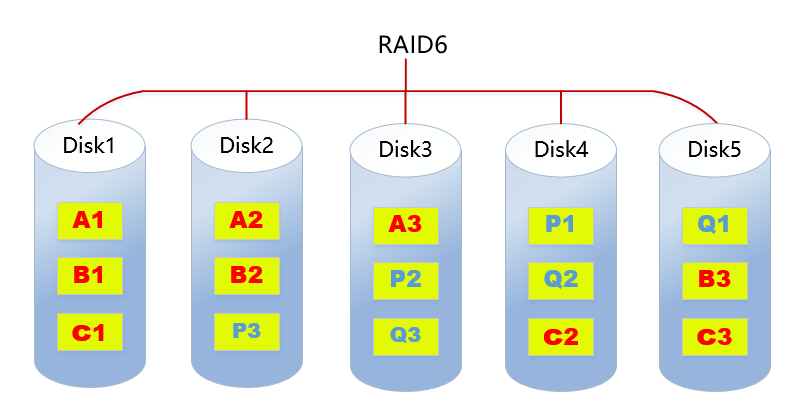
RAID6特点:
至少需要4块磁盘。
数据条带化存储在磁盘,读取性能好,容错能力强。
采用双重校验方式保证数据的安全性。
如果2块磁盘同时故障,可以通过两个校验数据来重建两个磁盘的数据。
成本要比其他等级高,并且更复杂。
一般用于对数据安全性要求非常高的场合。
Raid 10
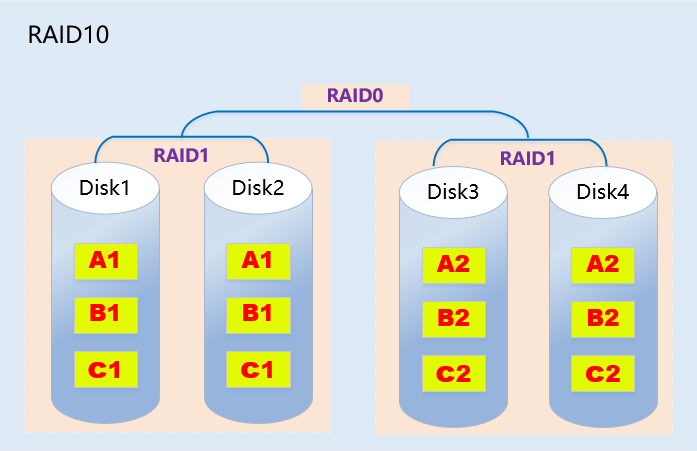
RAID10特点:
RAID 10是Raid 1+Raid 0的组合。至少需要4块磁盘。
两块硬盘为一组先做Raid1,再将做好Raid1的两组做Raid0。
兼顾数据的冗余(raid1镜像)和读写性能(raid0数据条带化)
磁盘利用率为50%,成本较高。
只要坏的不是同一个组中,所有的硬盘,就算坏掉一半硬盘都不会丢数据。
因此Raid10是最实用的方案。
总结Raid级别
生产环境下的raid选择
可能用,只会是硬件的磁盘阵列卡
可能不用,现在的存储技术,都发展到了分布式该年,比如主流的共有云服务器,都不用raid技术了,即使人家用了,基本你也完全管不着
只有当你需要拿到一堆服务器,进行服务器从零初始化
对磁盘,做raid技术,4块硬盘,将其采用raid技术搭建
只能是用硬件的raid卡
只能用linux软raid技术,查看它的效果
物理服务器、使用物理raid卡来实现
云服务器、完全不用关心raid搭建,云厂商会给你提供靠谱的高性能、高安全性的磁盘底层技术。
阿里云,他们已经不用raid了,而是用2种方式
现在的磁盘,读写速度都很快,阿里的云盘,可以不考虑这些
1.本地高性能硬盘,nvme技术
如https://search.jd.com/Search?keyword=nvme&enc=utf-8
2.分布式存储技术,具体看阿里云文档
https://help.aliyun.com/document_detail/25383.html?source=5176.11533457&userCode=r3yteowb&type=copy硬Raid、软Raid
软件Raid与硬件Raid的差异
软件控制的Raid磁盘冗余阵列
由CPU去控制硬盘驱动器进行数据转换、计算的过程就是软件RAID。
硬件控制
由专门的RAID卡上的主控芯片操控,就是硬件RAID。
软RAID
软RAID运行于操作系统底层,将SCSI或者IDE控制器提交上来的物理磁盘,虚拟成虚拟磁盘,再提交给管理程序来进行管理。软RAID有以下特点:
节省成本,系统支持就可以使用相应功能
占用内存空间
占用CPU资源
如果程序或者操作系统故障就无法运行
硬RAID
通过用硬件来实现RAID功能的就是硬RAID,独立的RAID卡,主板集成的RAID芯片都是硬RAID。RAID卡就是用来实现RAID功能的板卡。硬RAID的特点:
硬RAID有独立的运算单元,性能好
可能需要单独购买额外的硬件
不同RAID卡支持的功能不同,需要根据自己的需求选择
认识Raid卡
阵列卡的全称叫磁盘阵列卡 是用来做 RAID(廉价冗余磁盘阵列)的。磁盘阵列是一种把若干硬磁盘驱动器按照一定要求组成一个整体,整个磁盘阵列由阵列控制器管理的系统。




软Raid 10 实战
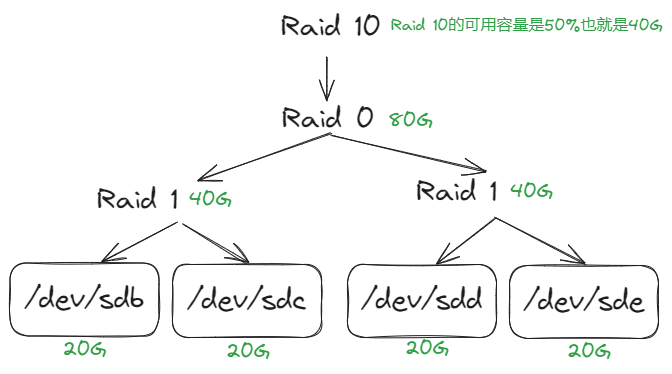
准备4块硬盘,切记,是新的四块硬盘,没有任何分区的,你可以用parted命令清除原有的分区
[root@server ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 19G 0 part
├─centos-root
253:0 0 17G 0 lvm /
└─centos-swap
253:1 0 2G 0 lvm [SWAP]
sdb 8:16 0 20G 0 disk
sdc 8:32 0 20G 0 disk
sdd 8:48 0 20G 0 disk
sde 8:64 0 20G 0 disk
sr0 11:0 1 4.2G 0 rom /run/media/admin/CentOS 7 x86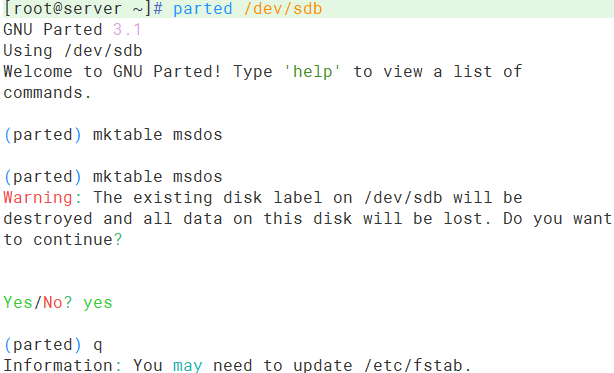
安装mdadm命令
yum install mdadm -y参数
创建Raid 10命令
创建Raid 10这个硬盘组,这个硬盘组的名字 /dev/md0
mdadm -Cv /dev/md0 -a yes -n 4 -l 10 /dev/sdb /dev/sdc /dev/sdd /dev/sde可能会遇到如下报错
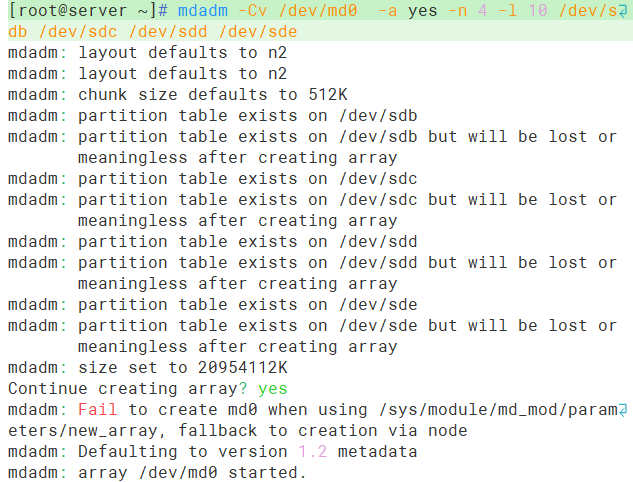
问题原因
可能不是新硬盘,需要格式化。
有挂载了。
分了区或者分区类型不同。
解决办法
取消挂载
umount /dev/sdb [挂载点]删除分区
fdisk /dev/sdb
d使用parted命令修改分区类型
parted /dev/sdb
(parted) mktable msdos
(parted) yes
(parted) q查看Raid 10信息
[root@server ~]# fdisk -l |grep md0
Disk /dev/md0: 42.9 GB, 42914021376 bytes, 83816448 sectors[root@server ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Aug 29 19:53:30 2024
Raid Level : raid10
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Aug 29 20:10:19 2024
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Name : server:0 (local to host server)
UUID : 31b210f2:868edc2b:e517377b:c965d2d7
Events : 17
Number Major Minor RaidDevice State
0 8 16 0 active sync set-A /dev/sdb
1 8 32 1 active sync set-B /dev/sdc
2 8 48 2 active sync set-A /dev/sdd
3 8 64 3 active sync set-B /dev/sde创建文件系统
[root@server ~]# mkfs.xfs /dev/md0
meta-data=/dev/md0 isize=512 agcount=16, agsize=654720 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=10475520, imaxpct=25
= sunit=128 swidth=256 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=5120, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0进行挂载分区
创建挂载目录
[root@server ~]# mkdir /yang_linux挂载分区
[root@server /]# mount /dev/md0 /yang_linux/
[root@server /]# mount -l |grep md0
/dev/md0 on /yang_linux type xfs (rw,relatime,attr2,inode64,sunit=1024,swidth=2048,noquota)查看挂载后磁盘使用情况
[root@server /]# df -hT /dev/md0
Filesystem Type Size Used Avail Use% Mounted on
/dev/md0 xfs 40G 33M 40G 1% /yang_linux写入数据
[root@server ~]# ls /yang_linux/
[root@server ~]# touch /yang_linux/带你飞.txt
[root@server ~]# ls /yang_linux/
带你飞.txt加入开机自动挂载
vim /etc/fatab
方法一:设备名挂载
/dev/md0 /yang_linux/ xfs defaults 0 0
#要挂载的硬盘名 #挂载点 #文件格式 #挂载参数
方法二:设备UUID挂载
#查看UUID
[root@server ~]# blkid /dev/md0
/dev/md0: UUID="0021f09e-582e-4c8e-853d-b3df15561fce" TYPE="xfs"
[root@server ~]# vim /etc/fatab
UUID=0021f09e-582e-4c8e-853d-b3df15561fce /yang_linux/ xfs defaults 0 0剔除一块硬盘
停止 & 删除阵列
当阵列没有文件系统或者其他存储应用以及高级设备使用的话,可以使用--stop(或者其缩写-S)停止阵列;如果命令返回设备或者资源忙类型的错误,说明/dev/md0正在被上层应用使用,暂时不能停止,必须要首先停止上层的应用,这样也能保证阵列上数据的一致性。
[root@test ~]# mdadm --stop /dev/md0
mdadm: fail to stop array /dev/md0: Device or resource busy
[root@test ~]# umount /dev/md0
[root@test ~]# mdadm --stop /dev/md0
mdadm: stopped /dev/md0上面只是停止阵列,阵列其中的设备还存在着阵列元数据信息,如果需要彻底删除阵列,还需要--zero-superblock将阵列中所有设备的元数据块删除。
[root@test ~]# mdadm --zero-superblock /dev/sdb[root@server ~]# mdadm /dev/md0 -f /dev/sdd
mdadm: hot removed /dev/sdd
[root@server ~]# cd /yang_linux/
[root@server ~]# ls
带你飞.txt
#可以看到即使有一块盘挂了仍可以访问数据。重新加入/dev/sdd硬盘
第7步是模拟的一块硬盘损坏了,你还得重新加入一个新的硬盘,继续恢复Raid 10的状态,因此你得买硬盘,reboot重启机器,重新修复Raid10。
注意:重启得把/etc/fatab文件里的自动挂载代码删除,不然开机会出错。!!!
然后添加硬盘到阵列组中
[root@server ~]# mdadm /dev/md0 -a /dev/sdd
mdadm: added /dev/sdd再去验证磁盘组 /dev/md0的状态,是否都恢复了
[root@server ~]# mdadm -D /dev/md0
Number Major Minor RaidDevice State
4 8 16 0 spare rebuilding /dev/sdb
1 8 32 1 active sync set-B /dev/sdc
2 8 48 2 active sync set-A /dev/sdd
3 8 64 3 active sync set-B /dev/sde常见磁盘故障
LVM卷管理(重点)
LVM概念
LVM,即 Logical Volume Manager ,逻辑卷管理器,是一种将一个或多个硬盘的分区在逻辑上集合,相当于一个大硬盘来使用,当硬盘的空间不够使用的时候,可以继续将其它的硬盘的分区加入其中,这样可以事项一种磁盘空间的动态管理,相对于普通的磁盘分区有很大的灵活性。
使用普通的磁盘分区,当一个磁盘的分区空间不够使用的时候,可能就会带来很大的麻烦。
逻辑卷(LVM):它是Linux环境下对磁盘分区进行管理的一种机制。 它是建立在物理存储设备之上的一个抽象层,优点在于灵活管理。
基于分区创建Ivm
硬盘的
多个分区由lvm统一为卷组,可以弹性的调整卷组的大小,充分利用硬盘容量。文件系统创建在逻辑卷上,逻辑卷可以根据需求改变大小(卷组总容量范围内)。
基于硬盘创建lvm
多块硬盘做成逻辑卷,将整个逻辑卷同意管理,可以动态对分区进行扩缩空间容量。
LVM与Raid的区别
图解lvm工作流程
LVM的架构体系中,有三个很重要的概念
PV,物理卷,即实际存在的硬盘、分区或者RAID。
VG,卷组,是由多个物理卷组合行成的大的整体的卷组。
LV,逻辑卷,是从卷组上分割出来的,可以使用使用的逻辑存储设备。
PE,物理区域
每一个物理卷被划分为称为PE(Physical Extents)的基本单元,具有唯一编号的PE是能被LVM寻址的最小单元。PE的大小可指定,默认为4 MB。PE的大小一旦确定将不能改变,同一个卷组中的所有物理卷的PE的大小是一致的。4MB=4096kb=4096kb/4kb=1024个bock
说明:
1.硬盘读取数据最小单位1个扇区512字节
2.操作读取数据最小单位1个数据块=8*512字节=4096字节=4KB
3.Ivm寻址最小单位1个PE=4MB
lvm扩容原理
LVM是通过 交换PE 的方式,达到弹性变更文件系统大小的。
剔除原本LV中的PE,就可以减少LV的容量
把其他PE添加到LV,就可以扩容LV容量
一般默认PE大小是4M,LVM最多有65534个PE,所以LVM最大的VG是256G单位
PE是LVM最小的存存储单位,类似文件系统的block单位,因此PE大小影响VG容量。
LV如同
/dev/sd[a-z]的分区概念。
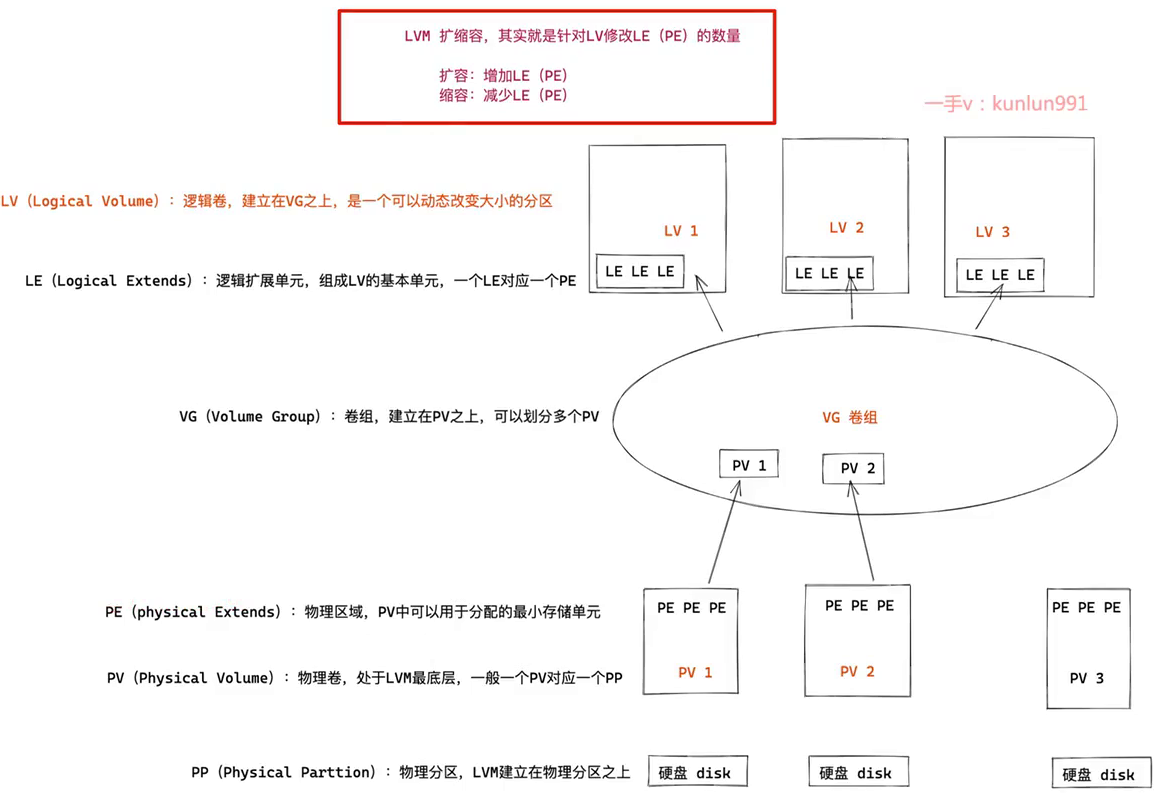
LVM创建和管理命令
在部署LVM时,要依次配置PV物理卷、VG卷组、LV逻辑卷。常用的LVM部署命令如下表所示:
LVM使用实例
前提是安装LVM工具
yum install lvm2 -y要求
使用2块硬盘/dev/sdb、/dev/sdc,容量分别是20G,20G
创建卷组,名字是vg1-2024
创建3个lv,名字依次是 lv1、lv2、lv3,容量分别是5G,10G,15G
3个逻辑卷,挂载点分别是 /t1 、/t2、 /t3,文件系统分别是xfs、xfs、ext4
实现开机自动挂载
要求分别查看3个逻辑卷的文件系统信息
xfs:
xfs_info /dev/sdb |grep -Ei '^inode|^block'ext4:
dumpe2fs /dev/sdb |grep -Ei '^inode|^block'
要求扩容2024-lv1,扩大到10G容量
xfs_growfs
要求扩容2024-lv3,扩大到30G容量
resize2fs
创建LVM
1.查看pv
[root@server ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sda2 centos lvm2 a-- <19.00g 0
2.创建pv
[root@server ~]# pvcreate /dev/sdb /dev/sdc
WARNING: dos signature detected on /dev/sdb /dev/sdc at offset 510. Wipe it? [y/n]: y
Wiping dos signature on /dev/sdb /dev/sdc.
Physical volume "/dev/sdb" successfully created.
Physical volume "/dev/sdc" successfully created.
3.查看创建后的pv
[root@server ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sda2 centos lvm2 a-- <19.00g 0
/dev/sdb lvm2 --- 20.00g 20.00g
/dev/sdc lvm2 --- 20.00g 20.00g
4.查看vg
[root@server ~]# vgs
VG #PV #LV #SN Attr VSize VFree
centos 1 2 0 wz--n- <19.00g 0
5.创建vg sdb sdc创建为卷组,名字是 vg1-2024
[root@server ~]# vgcreate vg1-2024 /dev/sdb /dev/sdc
Volume group "vg1-2024" successfully createdd
6.查看创建后的vg
[root@server ~]# vgs
VG #PV #LV #SN Attr VSize VFree
centos 1 2 0 wz--n- <19.00g 0
vg1-2024 2 0 0 wz--n- 39.99g 39.99g
7.查看lv
[root@server ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
root centos -wi-ao---- <17.00g
swap centos -wi-ao---- 2.00g
8.创建lv(创建分区)`lv1 5G、lv2 10G、lv3 15G`
[root@server ~]# lvcreate -n lv1 -L 5G vg1-2024
Logical volume "lv1" created.
[root@server ~]# lvcreate -n lv2 -L 10G vg1-2024
Logical volume "lv2" created.
[root@server ~]# lvcreate -n lv3 -L 15G vg1-2024
Logical volume "lv3" created.
[root@server ~]# ls /dev/vg1-2024/
lv1 lv2 lv3
9.查看创建后的lv
[root@server ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
root centos -wi-ao---- <17.00g
swap centos -wi-ao---- 2.00g
lv1 vg1-2024 -wi-a----- 5.00g
lv2 vg1-2024 -wi-a----- 10.00g
lv3 vg1-2024 -wi-a----- 15.00g
10.查看磁盘设备信息
通过如下命令,查看lvm设备的信息
[root@server ~]# blkid |grep 'sd[bc]'
/dev/sdc: UUID="OXuCw6-Bfsl-8XT1-lQnO-0149-jXTP-bc3lA7" TYPE="LVM2_member"
/dev/sdb: UUID="Z4LWCE-6sz1-dAhJ-1jzX-XMC0-2Meg-4jqdCP" TYPE="LVM2_member"
11.给lv格式化文件系统
`lv1 5G ---xfs`
`lv2 10G ---xfs`
`lv3 15G ----ext4`
[root@server ~]# mkfs.xfs /dev/vg1-2024/lv1
[root@server ~]# mkfs.xfs /dev/vg1-2024/lv2
[root@server ~]# mkfs.ext4 /dev/vg1-2024/lv3
12.挂载lv
[root@server ~]# mount /dev/vg1-2024/lv1 /t1
[root@server ~]# mount /dev/vg1-2024/lv2 /t2
[root@server ~]# mount /dev/vg1-2024/lv3 /t3
13.查看挂载
[root@server ~]# mount -l |grep t1
/dev/mapper/vg1--2024-lv1 on /t1 type xfs (rw,relatime,attr2,inode64,noquota)
[root@server ~]# mount -l |grep t2
/dev/mapper/vg1--2024-lv1 on /t2 type xfs (rw,relatime,attr2,inode64,noquota)
[root@server ~]# mount -l |grep t3
/dev/mapper/vg1--2024-lv2 on /t3 type ext4 (rw,relatime,data=ordered)
[root@server ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/centos-root xfs 17G 5.4G 12G 32% /
/dev/mapper/vg1--2024-lv1 xfs 5.0G 33M 5.0G 1% /t1
/dev/mapper/vg1--2024-lv2 xfs 10G 33M 10G 1% /t2
/dev/mapper/vg1--2024-lv3 ext4 15G 41M 14G 1% /t3
[root@server ~]# lsblk -f
尝试写入数据
[root@server ~]# touch /t1/昨天是美好的一天
[root@server ~]# touch /t2/今天也是美好的一天
[root@server ~]# touch /t3/明天更是美好的一天
14.开机自动挂载
一定切记,如果你的设备发生了变化,一定要去修改/etc/fstab
否则系统开机,读取该fstab文件,找不到设备,无法正确挂载就会报错
进入紧急模式,直到你再次修复fstab文件
重启即可
#查询 分区名和UUID
[root@server ~]# blkid | grep 'lv[1,2,3]'
/dev/mapper/vg1--2024-lv1: UUID="5dcfd588-84d3-4af0-8cae-3ae628ccee1b" TYPE="xfs"
/dev/mapper/vg1--2024-lv2: UUID="37555744-5fac-46a5-a055-e0bbead3a2f3" TYPE="xfs"
/dev/mapper/vg1--2024-lv3: UUID="24a6de08-0c2f-4993-acd4-9e33d4080cc3" TYPE="ext4"
把t1 t2 t3设置为开机自动挂载
[root@server ~]# tail -3 /etc/fstab
UUID=5dcfd588-84d3-4af0-8cae-3ae628ccee1b /t1 xfs defaults 0 0
UUID=37555744-5fac-46a5-a055-e0bbead3a2f3 /t2 xfs defaults 0 0
UUID=24a6de08-0c2f-4993-acd4-9e33d4080cc3 /t3 ext4 defaults 0 0
15.重启
reboot卷组报错:Device devsdc excluded by a filter.解决办法
1.问题描述
vgextend myvg /dev/sdc # 将/dev/sdc磁盘不分区直接扩容至myvg卷组
# 报错: Device /dev/sdc excluded by a filter.
fdisk -l /dev/sdc # 查看磁盘标签类型2.问题分析 由于之前对/dev/sdc磁盘进行过分区,磁盘标志类型为gpt,所以扩容卷组时检测到分区中已存在分区表,于是放弃新建,遂报错:Device /dev/sdc excluded by a filter.设备/dev/sdc已被过滤器过滤。
3.解决方案
parted /dev/sdc
mklabel msdos
yes
q退出
vgextend myvg /dev/sdc
y确认擦去dos签名
vgs查看卷组可用容量
LVM动态扩容
需求:
把逻辑卷 lv1 扩容到10G。
先查看当前机器的lv情况,确定你要扩容的设备。
[root@server ~]# df -h |grep t1
/dev/mapper/vg1--2024-lv1 5.0G 33M 5.0G 1% /t1思路:
查看该挂载点
df -h,对应的逻辑卷是哪一个/dev/mapper/vg1--2024-lv1查看该逻辑卷所在的卷组
vgs,是否还有剩余空间。如果vg1空间不够,就得先扩容卷组,再扩容逻辑卷。
如果vg1空间足够,直接扩容逻辑卷。
方案1,卷组容量够
1.确认vg够不够
[root@server ~]# vgs
VG #PV #LV #SN Attr VSize VFree
centos 1 2 0 wz--n- <19.00g 0
vg1-2024 2 3 0 wz--n- 39.99g 9.99g
2.确认够用,直接lvextend扩容lv逻辑卷即可.`给lv1增加到10G`
[root@server ~]# lvextend -L 10G /dev/vg1-2024/lv1
Size of logical volume vg1-2024/lv1 changed from 5.00 GiB (1280 extents) to 10.00 GiB (2560 extents).
Logical volume vg1-2024/lv1 successfully resized.
[root@server ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
root centos -wi-ao---- <17.00g
swap centos -wi-ao---- 2.00g
lv1 vg1-2024 -wi-ao---- 10.00g
lv2 vg1-2024 -wi-ao---- 10.00g
lv3 vg1-2024 -wi-ao---- 15.00g
3.虽然你调整了 lv2逻辑卷的大小,但是文件系统它不知道,你得告诉文件系统,也跟着调整分区的容量,以及重新设置block的数量
`ext4文件系统,使用resize2fs命令`
`xfs文件系统,使用xfs_growfs调整大小`
4.调整lv1 xfs文件系统的大小
[root@server ~]# xfs_growfs /dev/mapper/vg1--2024-lv1
meta-data=/dev/mapper/vg1--2024-lv1 isize=512 agcount=4, agsize=327680 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0 spinodes=0
data = bsize=4096 blocks=1310720, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 1310720 to 2621440
[root@server ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/centos-root xfs 17G 5.4G 12G 32% /
/dev/mapper/vg1--2024-lv1 xfs 10G 33M 10G 1% /t1
/dev/mapper/vg1--2024-lv2 xfs 10G 33M 10G 1% /t2
/dev/mapper/vg1--2024-lv3 ext4 15G 41M 14G 1% /t3方案2,卷组容量不够
1.调整lv3的文件系统,调整到30G
[root@server ~]# vgs
VG #PV #LV #SN Attr VSize VFree
centos 1 2 0 wz--n- <19.00g 0
vg1-2024 2 3 0 wz--n- 39.99g 4.99g
#发现卷组不够用了,得加新硬盘
2.先把物理设备,制作为物理卷
[root@server ~]# pvcreate /dev/sdd
Physical volume "/dev/sdd" successfully created.
[root@server ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sda2 centos lvm2 a-- <19.00g 0
/dev/sdb vg1-2024 lvm2 a-- <20.00g 0
/dev/sdc vg1-2024 lvm2 a-- <20.00g 4.99g
/dev/sdd lvm2 --- 20.00g 20.00g
3.添加物理卷到卷组(卷组扩容)
[root@server ~]# vgextend vg1-2024 /dev/sdd
Volume group "vg1-2024" successfully extended
[root@server ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sda2 centos lvm2 a-- <19.00g 0
/dev/sdb vg1-2024 lvm2 a-- <20.00g 0
/dev/sdc vg1-2024 lvm2 a-- <20.00g 4.99g
/dev/sdd vg1-2024 lvm2 a-- <20.00g <20.00g
注意:
正常情况下,应该先将/dev/sdb5物理设备创建为物理卷再加入到卷组中;如果直接加入卷组,系统会自动帮你将其做成物理卷。
4.查看扩容后的卷组
[root@server ~]# vgs
VG #PV #LV #SN Attr VSize VFree
centos 1 2 0 wz--n- <19.00g 0
vg1-2024 3 3 0 wz--n- <59.99g <24.99g
5.扩容逻辑卷,从15G增加到30G
[root@server ~]# lvextend -L +15G /dev/vg1-2024/lv3
Size of logical volume vg1-2024/lv3 changed from 15.00 GiB (3840 extents) to 30.00 GiB (7680 extents).
Logical volume vg1-2024/lv3 successfully resized.
[root@server ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
root centos -wi-ao---- <17.00g
swap centos -wi-ao---- 2.00g
lv1 vg1-2024 -wi-ao---- 10.00g
lv2 vg1-2024 -wi-ao---- 10.00g
lv3 vg1-2024 -wi-ao---- 30.00g
[root@server ~]# df -h |grep 'lv3'
/dev/mapper/vg1--2024-lv3 15G 41M 14G 1% /t3
#可以看到内存还是没变,需要调整文件系统大小
6.调整lv3 ext4文件系统的大小
[root@server ~]# resize2fs /dev/mapper/vg1--2024-lv3
resize2fs 1.42.9 (28-Dec-2013)
Filesystem at /dev/mapper/vg1--2024-lv3 is mounted on /t3; on-line resizing required
old_desc_blocks = 2, new_desc_blocks = 4
The filesystem on /dev/mapper/vg1--2024-lv3 is now 7864320 blocks long.
7.查看结果
[root@server ~]# df -h |grep 'lv3'
/dev/mapper/vg1--2024-lv3 30G 44M 28G 1% /t3删除lvm
1.考虑/etc/fstab,清除开机自动挂载的配置
2.取消挂载
[root@server ~]# umount /t1
[root@server ~]# umount /t2
[root@server ~]# umount /t3
3.依次删除lvm的组件
[root@server ~]# lvremove /dev/vg1-2024/lv1
Do you really want to remove active logical volume vg1-2024/lv1? [y/n]: y
Logical volume "lv1" successfully removed
[root@server ~]# lvremove /dev/vg1-2024/lv2
Do you really want to remove active logical volume vg1-2024/lv2? [y/n]: y
Logical volume "lv2" successfully removed
[root@server ~]# lvremove /dev/vg1-2024/lv3
Do you really want to remove active logical volume vg1-2024/lv3? [y/n]: y
Logical volume "lv3" successfully removed
4.删除vg
[root@server ~]# vgremove vg1-2024
Volume group "vg1-2024" successfully removed
[root@server ~]# vgs
VG #PV #LV #SN Attr VSize VFree
centos 1 2 0 wz--n- <19.00g 0
5.删除pv,还原磁盘原本类型
[root@server ~]# pvremove /dev/sdb /dev/sdc /dev/sdd
Labels on physical volume "/dev/sdb" successfully wiped.
Labels on physical volume "/dev/sdc" successfully wiped.
Labels on physical volume "/dev/sdd" successfully wiped.
6.最后,磁盘就还原为了不可动态调整的磁盘了,你可以格式化后,挂载使用该设备
[root@server ~]# mkfs.xfs /dev/sdb
meta-data=/dev/sdb isize=512 agcount=4, agsize=1310720 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=5242880, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@server ~]# mount /dev/sdb /t1
[root@server ~]# df -hT |grep sdb
/dev/sdb xfs 20G 33M 20G 1% /t1inode与block、软链接与硬链接
inode
文件属性查看
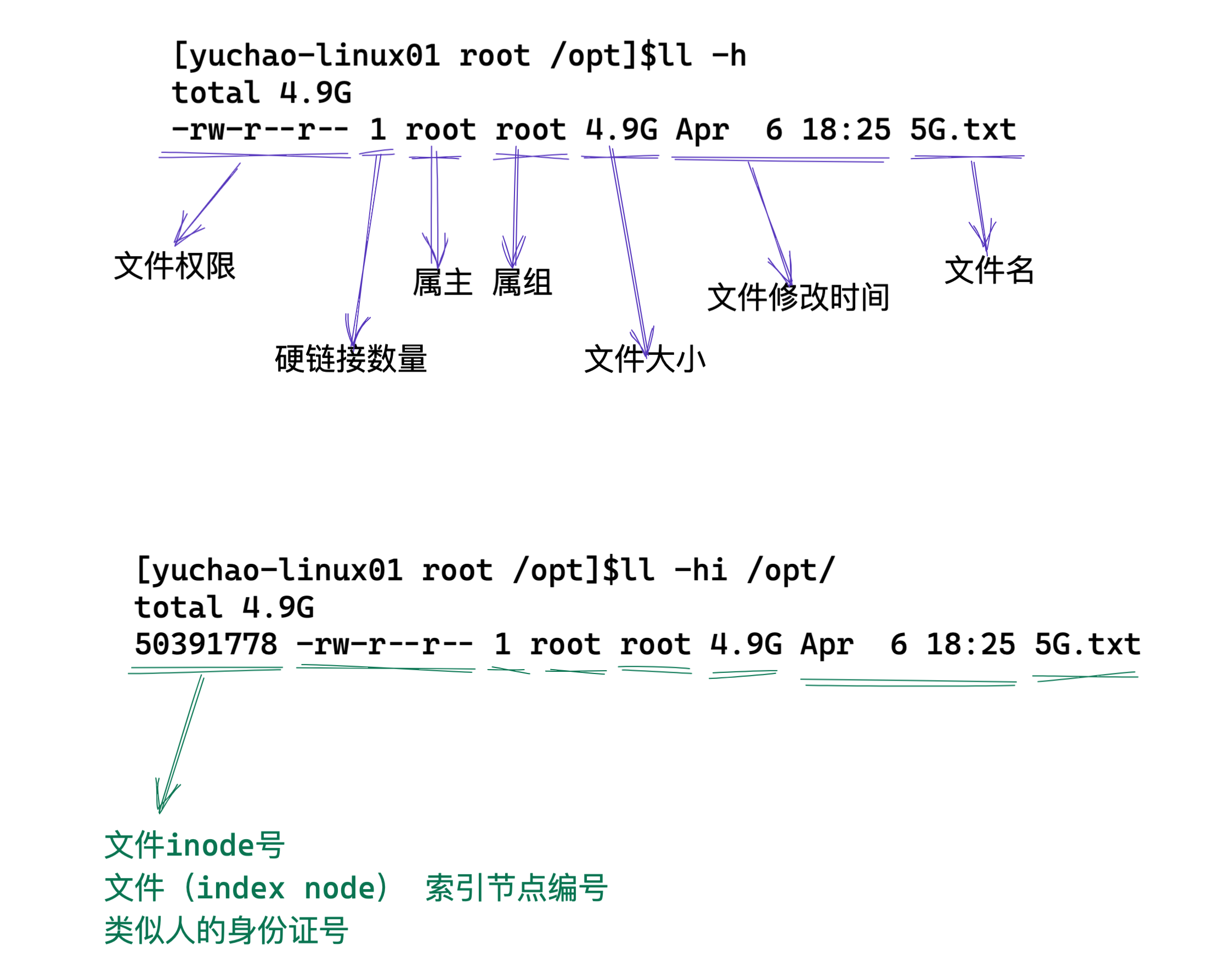
什么是inode
Linux的文件名,其实是分为了【元数据】+【文件内容】,两部分。
元数据,也就是文件的属性信息,可以通过stat命令查看到
一个新的磁盘,格式化文件系统后,就有了2个存储空间,一个叫做`inode`存储空间,存储设备上,所有文件名,对应的元数据信息(文件的属性信息)
一个叫做`block`存储空间(存储设备上,所有的文件的内容,数据都在这)
`存储元数据信息的空间,被称之为Inode`
`存储文件数据的空间,被称之为block`
linux读取文件内容,其实是 以 文件名 > inode编号 > block 的顺序来读取
在你创建文件前必须先要分区、格式化(创建文件系统)
创建文件系统后inode和block的数量就会固定下来。
mkfs.xfs /dev/sdc 格式化xfs文件系统后,inode和block的数量就固定下来了
可以通过xfs_info查看
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。
[yuchao-linux01 root /test1]$ls -l -i /tmp/c*
16777294 -rw-r--r-- 1 root root 0 Apr 7 11:01 /tmp/c1
16777702 -rw-r--r-- 1 root root 0 Apr 7 11:01 /tmp/c2
通过ls -i参数,查看文件,文件夹的inode号码
/opt/t1.log
/opt/t2.log
这里值得重复一遍,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。
表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。使用如下命令,查看文件的inode号
s -i 5G.txt
50391778 5G.txt为什么Linux要设计inode
理解inode,要从文件储存说起。
文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。
inode存储的内容
文件的字节数
文件拥有者的User ID
文件的Group ID
文件的读、写、执行权限
文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
链接数,即有多少文件名指向这个inode
文件数据block的位置
可以用stat命令,查看某个文件的具体inode信息
[root@server opt]# stat t1.txt
File: ‘t1.txt’
#字节数 #扇区数量 #块大小
Size: 82 Blocks: 8 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 54060438 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-08-17 23:09:20.379674309 +0800
Modify: 2024-08-17 23:06:27.558685623 +0800
Change: 2024-08-17 23:06:27.558685623 +0800
Birth: -图解文件访问原理
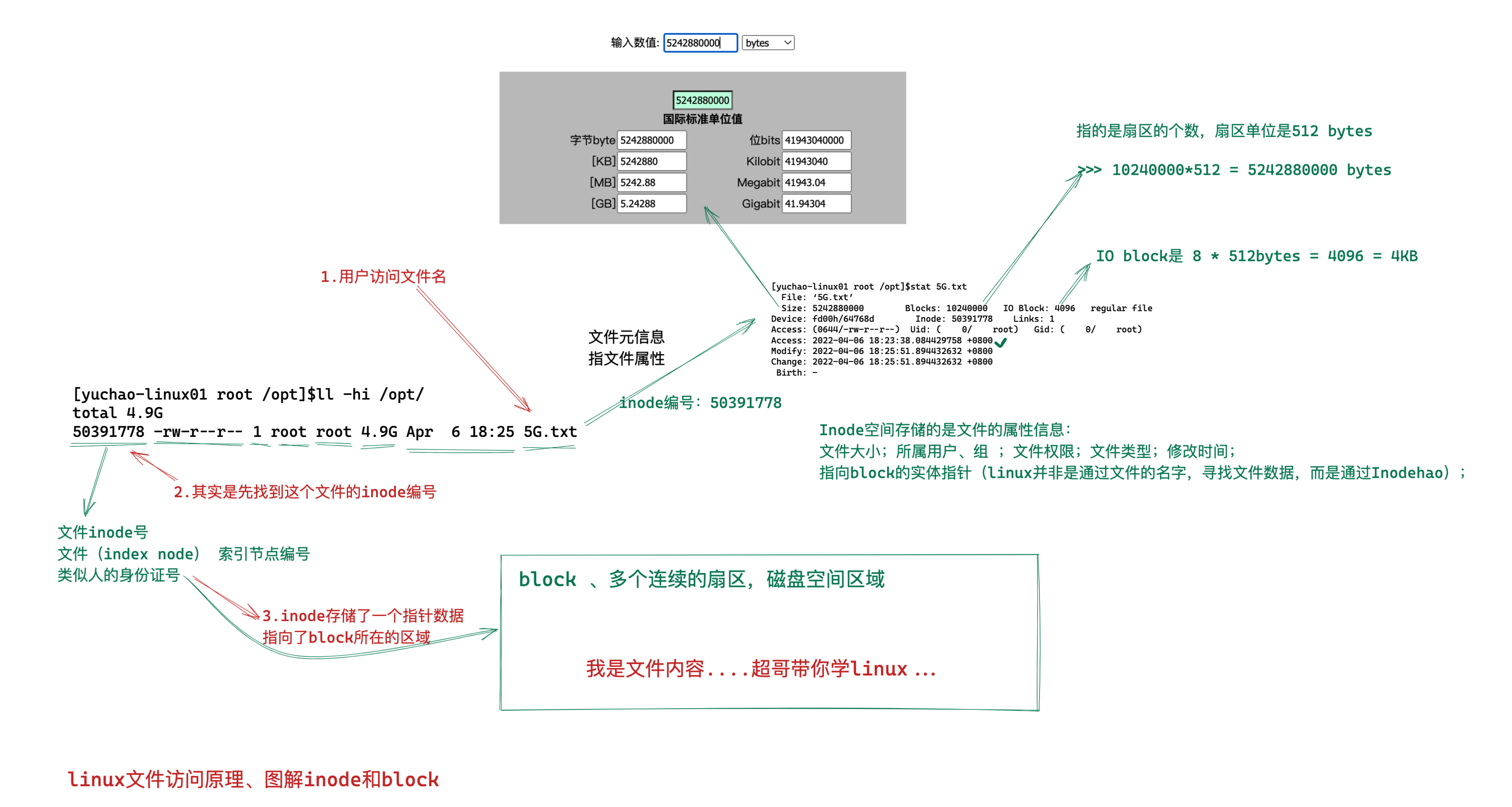
文件夹和文件的关系
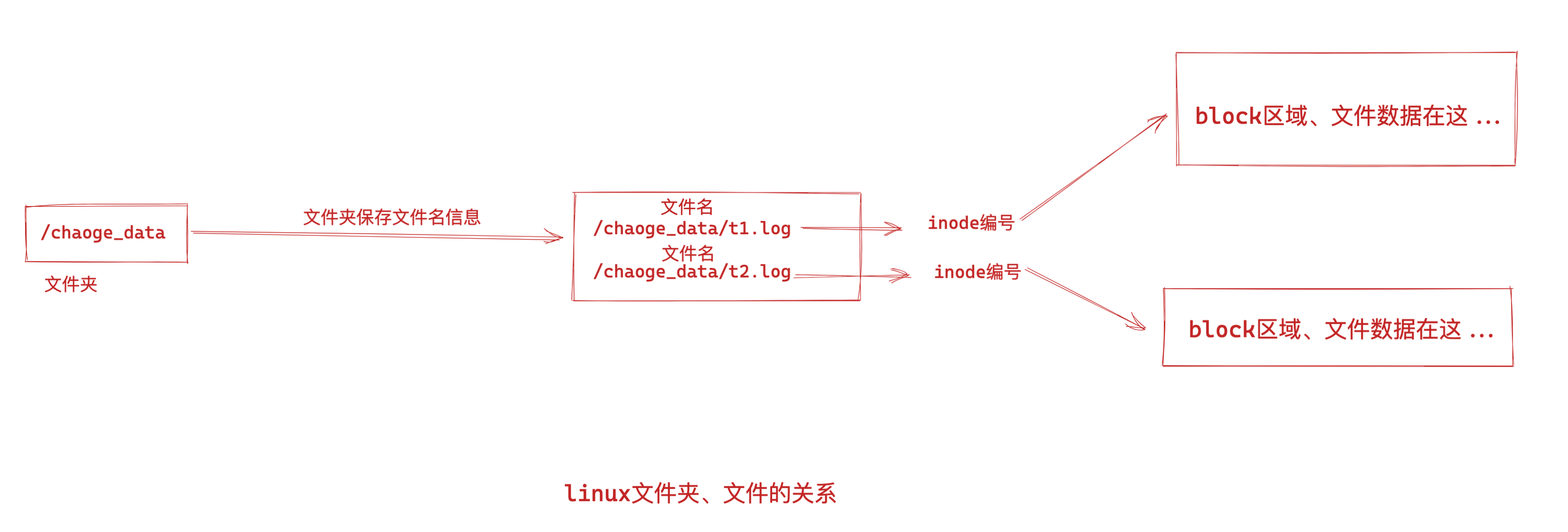
目录是一个特殊的文件,目录保存的是当前目录下的文件名字。
简单说,文件夹就是方便人类记忆文件存在哪、然后通过这个文件名,找到对应的文件inode号,inode号里记录了文件数据所处的block位置,最终访问到数据。
inode的作用
df -h
查看磁盘block空间的使用情况,如果看到分区快满了,可以去删除大容量的文件
df -i
inode存储文件属性的
当你机器上有大量的无用的小文件,空文件,白白消耗inode数量
查看磁盘分区inode空间的使用情况,如果可用的不多的,删除大量的4kb小文件即可,因为它们真用了太多的无效inode编号,应该留给别人用。
有时候明明 df -h看到磁盘还是有空间,但是写入数据,系统提示你no space for disk,你虽然还有block空间可以存数据但是你的inode数量肯定是没了。
touch 创建新文件,想分配inode编号,发现不够用了。block
什么是block
block是linux实际存储数据的空间,是8个连续的扇区,(8*512bytes=4KB)
单个大文件需要用多个block来存储
特别小的文件即使不满足4KB,也只能浪费其空间。
1 block =4kb删除文件原理
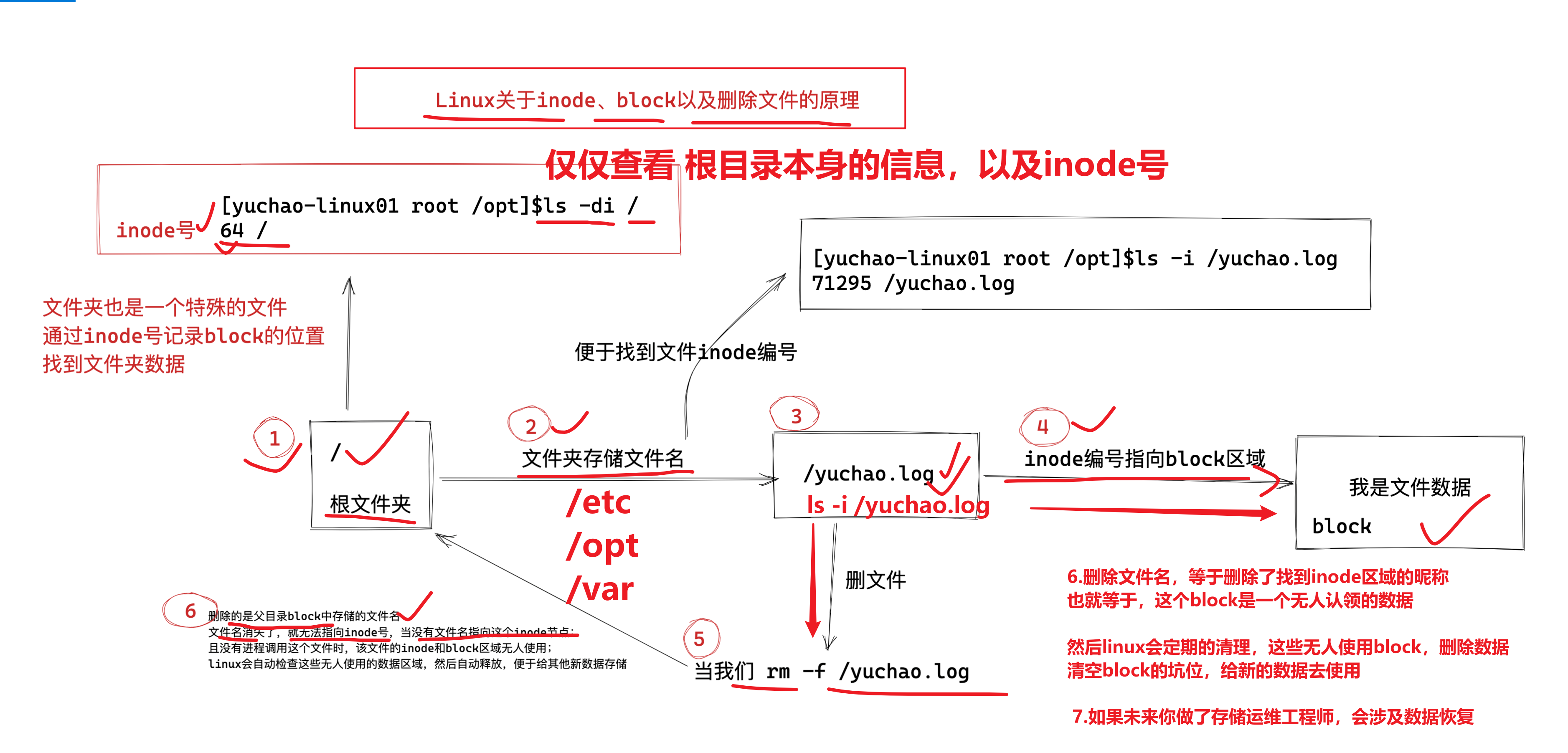
查看分区的inode和block数量(xfs_info)
inode和block的数量,是在你mkfs创建文件系统的时候,就已经确定好了。
ext4的文件系统,查看文件系统信息的命令,
dumpe2fsxfs文件系统,查看文件系统信息的命令,
xfs_info

查看某分区,有多少block让你用,(查看这个磁盘,分区还有多少容量)
df -h # -h参数,是友好的显示容量单位,如kb ,mb,gb查看某分区,一共有多少inode容量编号给我们用
#如/dev/sdc1
[root@server opt]# df -ih /dev/sdc1
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sdc1 5.0M 3 5.0M 1% /opt/my_sdc软链接
概念
语法
ln -s [源文件或目录] [软链接名称]软连接就是windows下的快捷方式。
软连接文件存储的是源文件的路径。
创建软连接 ln -s 参数去创建软连接
↓
当你访问软连接文件,其实是访问到源文件的路径,源文件的文件名
↓
访问源文件的inode编号 ls -i filename
↓
inode找到block,访问到数据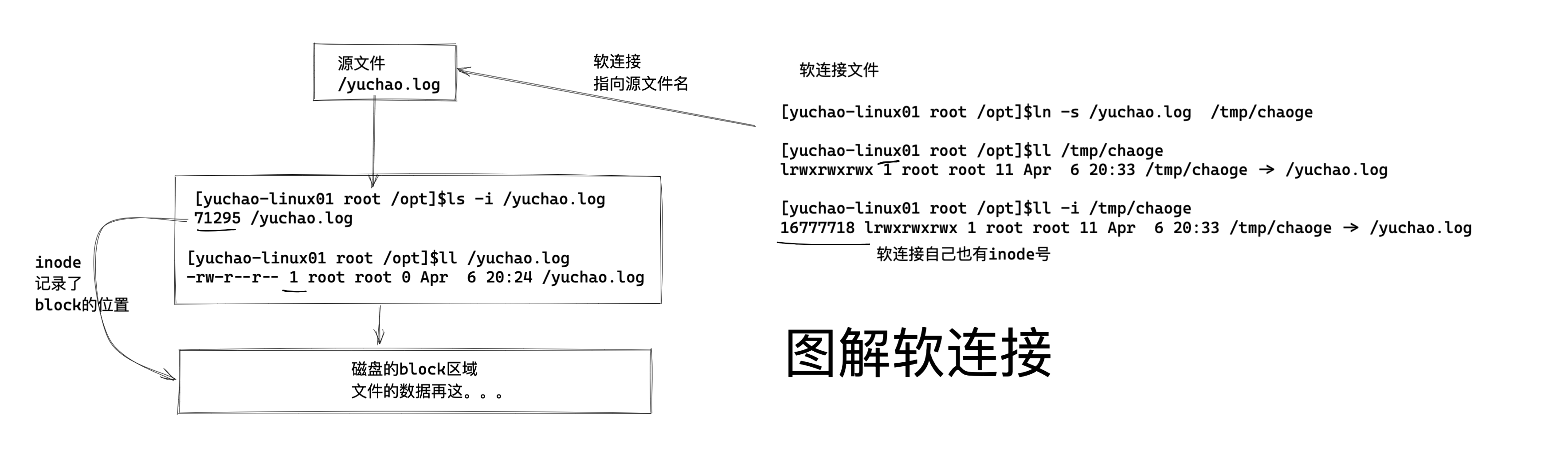
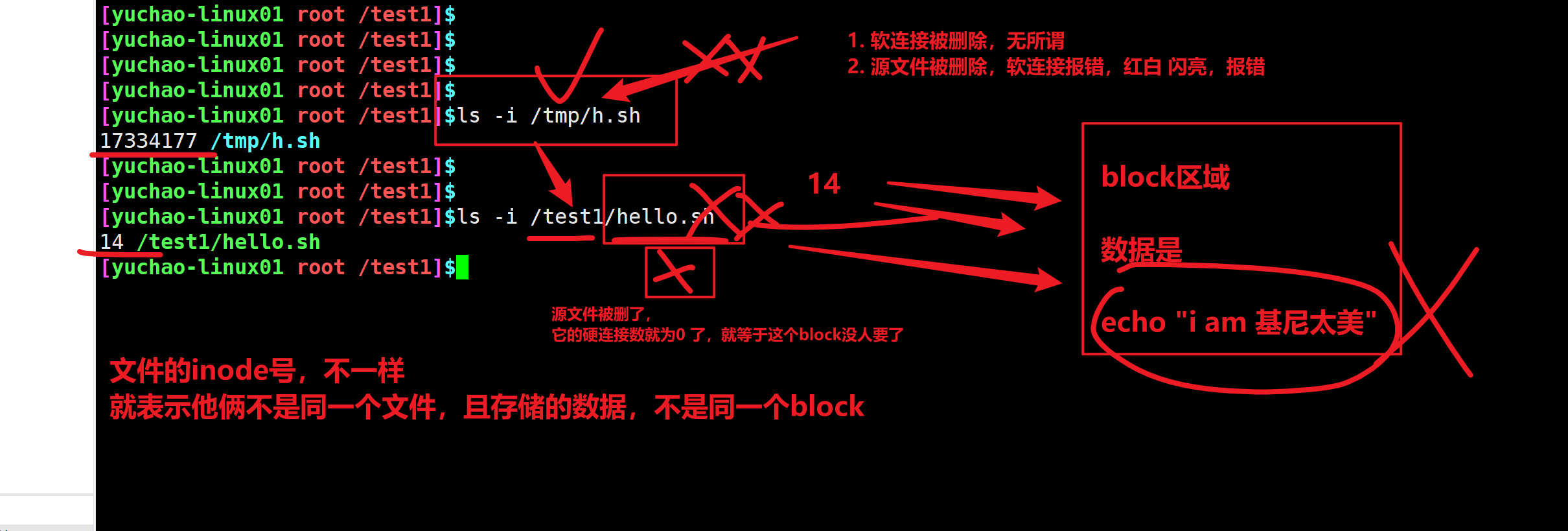
软连接特点
1.软连接文件的inode号和源文件不同,作用是存储源文件的路径
2.命令ln -s [源文件或目录] [软链接名称]
3.删除普通软连接,不影响源文件
4.删除源文件,软连接找不到目标,报错提示。硬链接
概念
硬链接,就是一个数据(block)被多个相同inode号的文件指向。就好比超市有好多个大门,但是都能进入到这个超市。
创建语法
ln [源文件] [链接文件][root@server opt]# touch yang.log
[root@server opt]# ls -li yang.log
52973440 -rw-r--r-- 2 root root 0 Aug 29 16:03 yang.log
[root@server opt]# ln yang.log /opt/yang2
[root@server opt]# ls -li yang2
52973440 -rw-r--r-- 2 root root 0 Aug 29 16:03 yang2
[root@server opt]# ln yang.log yang3
[root@server opt]# ls -li yang3
52973440 -rw-r--r-- 3 root root 0 Aug 29 16:03 yang3
#检查多个硬链接的inode号,都是同一个,表示是指向同一个区域的数据注意,大坑,硬链接,不得跨分区设置(inode号,是基于分区来创建)
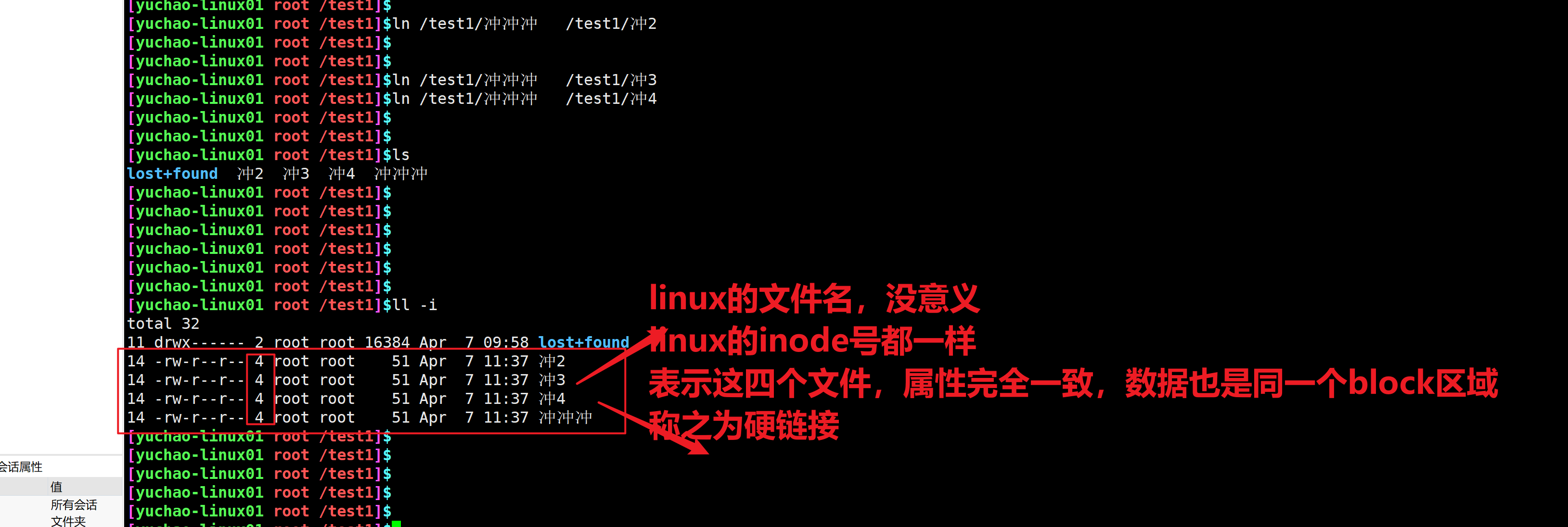
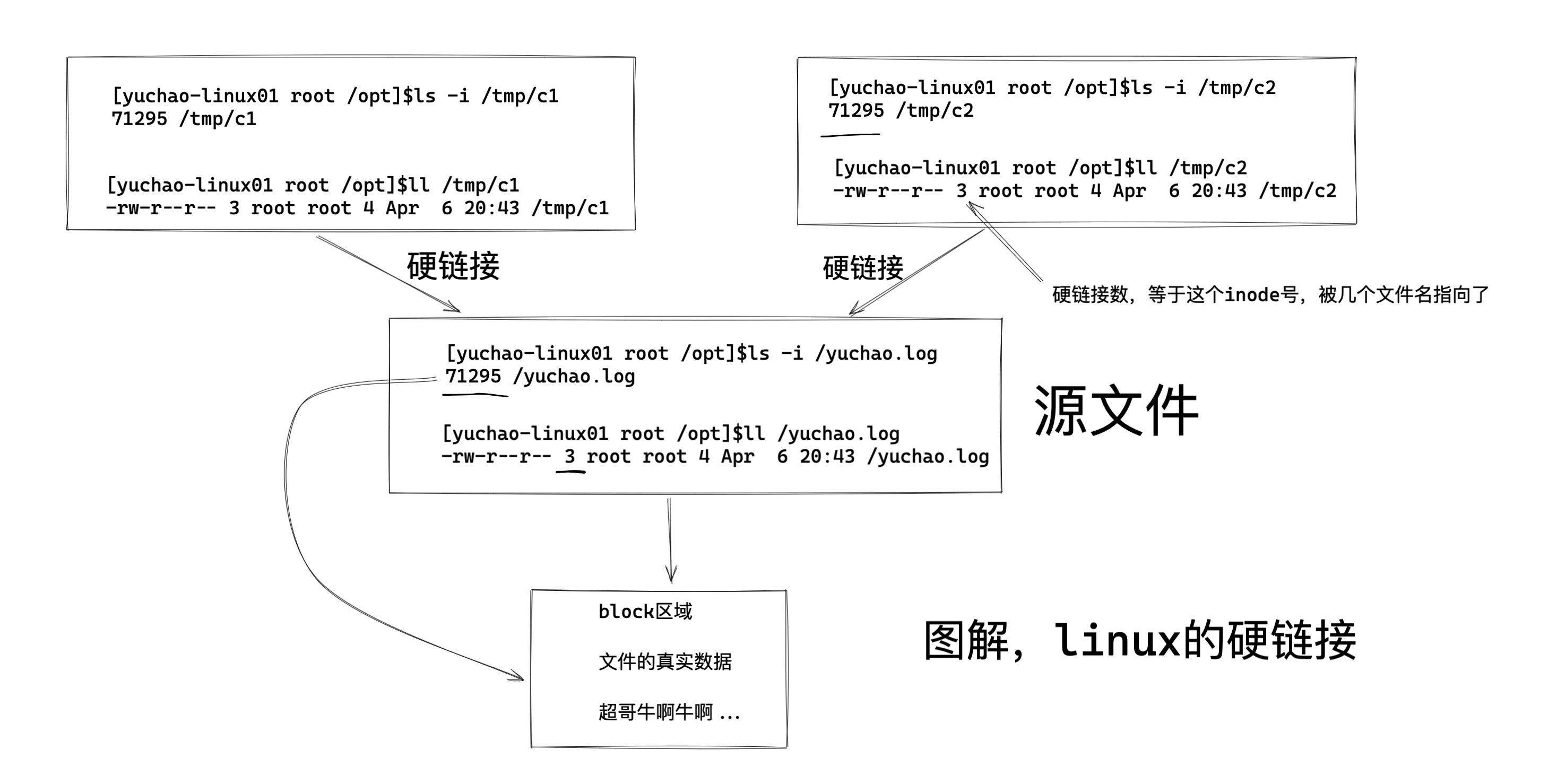
硬链接特点
1.可以对已存在的文件做硬链接,该文件的硬链接数,至少是1,为0就表示文件不存在
2.硬链接的文件,inode相同,属性一致
3.只能在同一个磁盘分区下,同一个文件系统下创建硬链接
4.不能对文件夹创建硬链接,只有文件可以
5.删除一个硬链接,不影响其他相同inode号的文件
6.文件夹的硬链接,默认是2个,以及是2+(第一层子目录总数)=文件夹的硬链接数量
7.可以用任意一个硬链接作为入口,操作文件(修改的其实是block中的数据)
8.当文件的硬链接数为0时,文件真的被删除在实际工作里用法
1.一般会给文件夹添加软连接,便于管理
2.通过软连接来区分软件的多种版本
3.通过inode号彻底删除文件,和硬连接关联的实例
1.创建文件夹的软连接2.创建文件的软连接3.删除文件、目录的软连接,查看效果4.删除文件、目录的源文件,查看效果5.往源文件写入数据,查看软连接文件的变化6.往软连接里写数据,查看源文件的变化通配符与特殊符号
通配符
基础通配符语法
实例
特殊符号
路径相关
引号相关
实例
' 单引号、所见即所得,引号里的所有内容,原样输出
[root@server ~]# echo '现在时间是$(date)'
现在时间是$(date)
[root@server ~]# echo '现在时间是 $(date '+%F %T')'
现在时间是 $(date '+%F %T')
[root@server ~]# name='吴彦祖'
[root@server ~]# echo '别人都喊我${name}'
别人都喊我${name}" 双引号、可以解析变量、及引用、linux命令
[root@server ~]# echo "现在时间是$(date)"
现在时间是Mon Apr 11 11:04:53 CST 2022
[root@server ~]# echo "现在时间是 $(date '+%F %T')"
现在时间是 2022-04-11 11:08:26
[root@server ~]# name='吴彦祖'
[root@server ~]# echo "别人都喊我${name}"
别人都喊我吴彦祖`` 反引号、可以解析命令
输出一段话---当前时间是:时间格式化
引号嵌套
[root@server ~]# echo "当前时间是:`date '+%F %T'`"
当前时间是:2022-04-11 11:11:23
作用同上
[root@server ~]# echo "当前时间是: $(date '+%F %T')"
当前时间是:2022-04-11 11:11:23
#无引号,一般我们都省略了双引号去写linux命令,但是会有歧义,比如空格,建议写引号理解Linux数据流
执行linux命令时,linux默认为用户进程提供了3种数据流
stdin
标准输入、0
一般是键盘输入数据
比如cat命令等待用户输入
stdout
标准输出、1
程序执行结果,输出到终端
stderr
械准错误输出
程序执行结果,输出到终端
标准输入(stdin) – 0
标准输出(stdout) – 1
标准错误(stderr) – 2
重定向符号
>这个符号表示将命令的输出重定向到一个文件中。如果文件不存在,它会被创建;如果文件已经存在,它的内容会被覆盖。
>>这个符号表示将命令的输出追加到一个文件中。如果文件不存在,它会被创建;如果文件已经存在,新内容会被追加到文件末尾。
使用
2>符号,将标准错误输出重定向到文件中。形式为:命令 2> 文件名使用
2>>符号,将标准错误输出追加到指定文件后面。形式为:命令 2>> 文件名使用
2>&1符号或&>符号,将把标准错误输出 stderr 重定向到标准输出 stdout使用
>/dev/nul符号,将命令执行结果重定向到空设备中,也就是不显示任何信息。
标准输入(stdin) – 0
标准输出(stdout) – 1
标准错误(stderr) – 2
例子:
如果你真的想要知道哪个输出命令说了些什么——你需要将那次发言重定向到(在命令后使用大于号">"和流索引)文件:
[root@localhost ~]# blablabla 1> output.txt
-bash: blablabla: command not found
在本例中,我们试着重定向流1(stdout)到名为output.txt的文件。让我们来看对该文件内容所做的事情吧,使用cat命令可以做这事:
[root@localhost ~]# cat output.txt
[root@localhost ~]#
看起来似乎是空的。好吧,现在让我们来重定向流2(stderr):
[root@localhost ~]# blablabla 2> error.txt
好吧,我们看到牢骚话没了。让我们检查一下那个文件:
[root@localhost ~]# cat error.txt
-bash: blablabla: command not found
果然如此!我们看到,所有牢骚话都被记录到errors.txt文件里头去了。
有时候,命令会同时产生stdout和stderr。要重定向它们到不同的文件,我们可以使用以下语句:
[root@localhost ~]#command 1>out.txt 2>err.txt
要缩短一点语句,我们可以忽略"1",因为默认情况下stdout会被重定向:
[root@localhost ~]#command >out.txt 2>err.txt
好吧,让我们试试做些"坏事"。让我们用rm命令把error和log给删了吧:
[root@localhost ~]# rmdir error log >out.txt 2>err.txt
现在来检查以下输出文件:
[root@localhost ~]# cat out.txt
[root@localhost ~]# cat err.txt
rmdir: failed to remove ‘error’: No such file or directory
rmdir: failed to remove ‘log’: No such file or directory
正如我们所看到的,不同的流被分离到了不同的文件。有时候,这也不是很方便,因为我们想要查看出现错误时,在某些操作前面或后面所连续发生的事情。要实现这一目的,我们可以重定向两个流到同一个文件
[root@localhost ~]# find /var/log -name "*.log" > log.txt 2>&1
[root@localhost ~]# find /var/log -name "*.log" > log.txt &>
------------------------------------------------------------------------------
2>&1 stderr重定向
把stderr当做stdout进行处理
实例:
[242-yuchao-class01 root ~]#ls /opt/ttttttttt > /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#cat /tmp/opt.file
ls: cannot access /opt/ttttttttt: No such file or directory
2>&1 stderr追加重定向
实例:
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#cat /tmp/opt.file
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory命令执行
实例
&&
安装nginx,且启动nginx
[root@server ~]# yum install nginx -y && systemctl start nginx
#常用
编译安装软件
make && make install ||
# 用户创建
判断用户已经存在了,就删掉用户
[root@server ~]# useradd wenjie || userdel -f wenjie ;
[root@server ~]# cd /opt ; pwd ;cd ; pwd
/opt
~\
需要和双引号结合使用
[root@server ~]# touch "\$name的文件"
[root@server ~]# ls
$name的文件$( )
[root@server ~]# echo "opt下的内容是$(ls /opt)"
opt下的内容是mm8888888.sh
M.sh
myfirst.txt找出nginx进程
ps -ef | grep ngixn{ }序列符
字母序列
touch {a..z}.txt touch {A..Z}.txt数字序列
touch {0..9}.txt文件名简写
修改linux的dns文件,但是要提前备份 ,文件名加上.bak [root@server ~]# cp /etc/resolv.conf /etc/resolv.conf.bak 这个写法,支持简写,再生成一个备份文件,叫做 .ori [root@server ~]# cp /etc/resolv.conf{,.ori} [root@server ~]# ls /etc/resolv.conf* /etc/resolv.conf /etc/resolv.conf.bak /etc/resolv.conf.ori变量分隔符
${name}
管道 |
[root@localhost ~]# echo "1+2+3" |bc
6
这里bc表示计算。
[root@localhost ~]# ls |grep cfg
anaconda-ks.cfg
initial-setup-ks.cfg
[root@localhost ~]# ls |grep cfg |grep anaconda-ks
anaconda-ks.cfg流
流并非一个命令,在计算机科学中,流 stream 的含义是比较难理解的,记住一点即可:流就是读一点数据,处理一点点数据。其中数据一般就是二进制格式。上面提及的重定向或管道就是把数据当做流去运转的。到此我们就接触了,流、重定向、管道等 Linux 高级概念及指令。
正则表达式与三剑客
为了让系统能正确执行shell语句(由于自定义修改的不同语言环境,对一些特殊符号的处理区别,如中文输入法,英文输入法下的标点符号等,导致shell无法执行)
我们会使用如下语句,恢复linux的所有的本地化设置,恢复系统到初始化的语言环境。
[root@server ~]# export LC_ALL=C通配符和正则的区别
1.从语法上就记住,只有awk、grep、sed才识别正则表达式符号、其他都是通配符
2.从用法上区分
表达式操作的是文件、目录名(属于是通配符)
表达式操作的是文件内容(正则表达式)
3.比如如下符号区别
通配符和正则表达式 都有 * ? [abcd] 符号
通配符中,都是用来标识任意的字符
如 ls *.log,可以找到a.log b.log ccc.log
正则中,都是用来表示这些符号前面的字符,出现的次数,如
grep 'a*'实际案例
通配符,一般用于对文件名的处理,查找文件
如ls命令结合*
意思是匹配任意字符
[root@yuchao-tx-server test]# ls *.log
1.log 2.log 3.log 4.log 5.log
而三剑客,结合*符号,是处理文件内容,如grep
此时的*作用就不一样了正则表达式分类
使用正则表达式的问题是、有两大类正则表达式规范、linux不同的应用程序,会使用不同的正则表达式。
例如
不同的编程语言使用正则(python,java)
Linux实用工具(sed、awk、grep)
其他软件使用正则(mysql、nginx)
正则表达式是通过正则表达式引擎(regular expression engine)实现的。正则表达式引擎是 一套底层软件,负责解释正则表达式模式并使用这些模式进行文本匹配。
在Linux中,有两种流行的正则表达式引擎:
基于unix标准下的正则表达式符号规则有两类:
POSIX基础正则表达式(basic regular expression,BRE)引擎
POSIX扩展正则表达式(extended regular expression,ERE)引擎
解释posix
POSIX(Portable Operating System Interface)是Unix系统的一个设计标准。
当年最早的Unix,源代码流传出去了,加上早期的Unix不够完善,于是之后出现了好些独立开发的与Unix基本兼容但又不完全兼容的OS,通称Unix-like OS普通字符与拓展字符
linux规范将正则表达式分为了两种
基本正则表达式(BRE、basic regular expression)
BRE对应元字符有
^ $ . [ ] *
其他符号是普通字符
; \扩展正则表达式(ERE、extended regular expression)
ERE在在BRE基础上,增加了
( ) { } ? + | 等元字符转义符
反斜杠 \
反斜杠用于在元字符前添加,使其成为普通字符正则表达式
正则表达式基础组成部分
例题
使用正则过滤出ens33网卡信息中的ip地址、掩码及广播地址。
[0-9]{n,m}(\ .[0.9]{n,m}){n}
[root@localhost dasan]# ifconfig ens33 | egrep -o '[0-9]{1,3}(\.[0-9]{1,3}){3}'
192.168.111.128
255.255.255.0
192.168.111.255
[root@localhost dasan]# ifconfig ens33 | egrep '[0-9]{1,3}(\.[0-9]{1,3}){3}'
inet 192.168.111.128 netmask 255.255.255.0 broadcast 192.168.111.255

^love 以love开头"^"
[root@localhost ~]# grep ^love linux.txt
love,how mich
love$ 以love结尾"$"
l..e 以l开头并e结尾的字符,".."表示俩字符。
[root@localhost ~]# grep l..e linux.txt
I hand a lovely time on our
love,how mich
. (小数点):代表『一定有一个任意字节』的意思;
* (星号):代表『重复前一个字符, 0 到无穷多次』的意思,为组合形态
.* 匹配任意字符
#找出文件名包含了yy且以txt结尾的文件
[root@localhost ~]#find / -name '*yy*.txt'
#找出i开头,you结束中间任意字符的内容
[root@server test]# grep 'i.*you' test.txt -n
13:i love you
14:iloveyou
^ .* 匹配以任意内容开头,以及后续所有数据
[root@server test]# grep '^i.*' test.txt -i -n
^$ 匹配空白行
[root@server test]# grep '^$' test.txt -i -n
3:
5:
9:
11:
^ .* $ 匹配开头和结尾,直接内容不管
#找出以I开头,s结尾的行
[root@server opt]# grep '^I.*s$' chaoge.txt
I like video,games,girls
[:space:]:空白字符
[:punct:]:标点符号
[:lower:]:小写字母
[:upper:]: 大写字母
[:alpha:]: 大小写字母
[:digit:]: 数字
[:alnum:]: 数字和大小写字母
[[:space:]]*love "*"代表匹配前面和后面以零个或多个字符
' '*love
[root@localhost ~]# grep [[:space:]]*love linux.txt
I hand a lovely time on our
love,how mich
#显示/etc/grub2.cfg文件中,至少以一个空白字符开头且后面有非空白字符的行。
[root@localhost ~]# grep "^[[:space:]]\+" /etc/grub2.cfg
#找出netstat -tan命令结果中以LISTEN跟多个空白字符的行
[root@localhost ~]# netstat -tan |grep "LISTEN[[:space:]]\+$"
#显示centos上所有UID小于1000以内的用户名和UID
[root@localhost ~]# cut -d: -f1,3 /etc/passwd | egrep -o "^.*\:[0-9]{1,3}$" | sort -t: -nk2 #这里 | sort -t: -nk2是升序排序
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 470M 0 470M 0% /dev
tmpfs 487M 0 487M 0% /dev/shm
tmpfs 487M 8.6M 478M 2% /run
tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/mapper/centos-root 17G 7.9G 9.2G 47% /
/dev/sda1 1014M 206M 809M 21% /boot
tmpfs 98M 32K 98M 1% /run/user/1000
/dev/sr0 4.2G 4.2G 0 100% /run/media/admin/CentOS 7 x86_64
[root@localhost ~]# df -h |egrep -o "[0-9]{1,3}%" |sort -rn #-r倒序排序 -n数字排序
100%
47%
21%
2%
1%
0%
0%
0%
过滤/etc/passwd中的root和bin
[root@localhost ~]# cut -d: -f1,3,7 /etc/passwd | egrep -o "^(root|bin)"
root
bin
[Ll]ove 同时匹配前面大小写的love。
[root@localhost ~]# grep [Ll]ove linux.txt
I hand a lovely time on our
Love,how mich
[ki]n 匹配k或i后接n的字符
[A-Z]ove 匹配首字母范围A到Z后接ove的字符。
[0-9] 匹配数字
[!a-f] 匹配除a-z之外的字符
[^A-Z]ove 匹配首字母不含A到Z后接ove的字符。这里"^"表示取反。
o\"{2,4\}" 匹配至少以俩o和最多有四o的单词。
grep o\"{2,4\}"
egrep o"{2,4}"
[root@localhost ~]# egrep "o{2,4}" linux.txt
looooveegrep [0-9]{1,3} #匹配1-3位的数字
egrep (\.[0-9]{1,3}) #.用到反转义\ 表示()匹配里面的字符串 即带小数点的1-3位数字
egrep {3} #匹配前面的字符3次,{n} 匹配前面的字符n次。
示例:
[0-9]{1,3}(\.[0-9]{1,3}){3}
说明:匹配IP地址 如127.0.0.1
[0-9]{1,3} 匹配1-3位的数字 等同于\d{1,3}
(\.[0-9]{1,3}) .用到反转义\ 表示匹配()里面的字符串 即带小数点的1-3位数字
{3} 匹配前面的字符3次,{n} 匹配前面的字符n次正则表达式全符号解释
实例
egrep "go+d"
[root@localhost ~]# egrep "go+d" re_file
goooood assdxw
goodfs awdef
good
egrep "go{1,}d"
[root@localhost ~]# egrep "go{1,}d" re_file
goooood assdxw
goodfs awdef
good
egrep "go?d"
[root@localhost ~]# egrep "go?d" re_file
god
egrep "gd|god|good"
[root@localhost ~]# egrep "gd|god|good" re_file
goodfs awdef
good
god
egrep "g(la|oo)d"
[root@localhost ~]# egrep "g(la|oo)d" re_file
goodfs awdef
good
glad
\< 铆定词首
grep \<is\> linux.txt
\> 铆定词尾
\<[]\> 铆定单词
例题:
过滤空白行和"#"开头输出关于三剑客
grep,过滤关键字信息数据。主要是用于查文本内的数据
sed ,对文本数据进行编辑,修改原文件内容
awk,对文件数据过滤,提取,并且能实现,格式化输出
awk对文件数据处理后,还能更美观的展示数据
sed
sed是什么
sed是Stream Editor(字符流编辑器)的缩写,简称流编辑器。
文件数据就像流水线一样被加工处理,sed就是一个加工厂,文件中的每一行每一个字符都是原料;
经过sed处理后,最终从流水线出来,产生结果。
sed常用于和正则表达式结合,实现对文件内容增删改查,最常用的功能是
过滤指定字符信息
取出指定的字符行
修改文件内容
sed语法格式
sed [选项] [sed内置命令字符] [输入文件]
说明:
1.注意 sed 软件及后面选项,sed 命令和输入文件,每个元素之间都至少有一个空格
2.为了避免混淆,文本称呼sed为sed软件.sed-commands(sed命令)是sed软件内置的一些命令选项,为了和前面的 options(选项)区分,故称为sed命令.
3.sed-commands 既可以是单个sed 命令,也可以是多个sed命令组合.
4.input-file(输入文件)是可选项,sed 还能够从标准输入或管道获取输入sed参数
options[选项]
解释说明
-n 取消默认的 sed 软件的输出,常与 sed 命令的 p 连用
-e 一行命令语句可以执行多条 sed 命令
-f 选项后面可以接 sed 脚本的文件名
-r 使用正则拓展表达式,默认情况 sed 只识别基本正则表达式
-i 直接修改文件内容,而不是输出终端,如果不使用-i 选项 sed 软件只是修改在 内存中的数据,并不影响磁盘上的文件sed软件命令
sed-commands[sed 命令]
解释说明
a 追加,在指定行后添加一行或多行文本
c 取代指定的行
d 删除指定的行
D 删除模式空间的部分内容,直到遇到换行符\n 结束操作,与多行模式相关
i 插入,在指定的行前添加一行或多行文本
h 把模式空间的内容复制到保持空间
H 把模式空间的内容追加到保持空间
g 把保持空间的内容复制到模式空间
G 把保持空间的内容追加到模式空间
x 交换模式空间和保持空间的内容
l 打印不可见的字符
n 清空模式空间,并读取下一行数据并追加到模式空间
N 不清空模式空间,并读取下一行数据并追加到模式空间
p 打印模式空间的内容,通常 p 会与选项-n 一起使用
P(大写) 打印模式空间的内容,直到遇到换行符\你结束操作
q 退出 sed
r 从指定文件读取数据
s 取代,s#old#new#g==>这里 g 是 s 命令的替代标志,注意和 g 命令区分
w 另存,把模式空间的内容保存到文件中
y 根据对应位置转换字符
:label 定义一个标签
t 如果前面的命令执行成功,那么就跳转到 t 指定的标签处,继续往下执行后 续命令,否则,仍然继续正常的执行流程set匹配范围
sed默认是一行一行,处理文件中每一行的数据
sed匹配文本范围
实践
准备测试文本
My name is yuchao.
I teach linux.
I like play computer game.
My qq is 877348180.
My website is http://www.yuchaoit.cnSed 默认不修改源文件
sed默认的命令操作,不会修改源文件,你看到的终端结果,只是sed把模式空间的内容打印给你看了而已。
得用 sed -i 参数修改源数据。
sed的修改字符与取消默认输出
sed命令语法(记忆)
关于sed处理文件行范围语法
sed提供打印的命令是p
注意-p和-n参数要结合使用
-p打印
-n取消默认输出
sed增删改查
增加数据
sed增加字符命令
"a":追加文本到指定行,记忆方法:a 的全拼是 apend,,意思是追加
3a 表示在第三行下面追加数据
"i":插入文本到指定行前,记忆方法:i 的全拼是 insert,意思是插入
3i 在第三行上面插入数据单行增加
语法
sed '行号 sed指令 你想添加的字符数据' 源文件实例
1,在文件第二行后,插入数据,今天又是美好的一天
sed -i '2 a 今天又是美好的一天 ' t1.log
[root@server ~]# sed -i '2 a 今天又是美好的一天 ' t1.log
[root@server ~]# cat t1.log -n
1 My name is yang.
2 I teach linux.
3 今天又是美好的一天
4 I like play computer game.
5 My qq is 877348180.
6 My website is http://www.soloyang.cn2,在第二行前,插入数据
sed -i '2 i 今天雾霾比较大' t1.log
[root@server ~]# sed -i '2 i 今天雾霾比较大' t1.log
[root@server ~]# cat t1.log -n
1 My name is yang.
2 今天雾霾比较大
3 I teach linux.
4 今天又是美好的一天
5 I like play computer game.
6 My qq is 877348180.
7 My website is http://www.soloyang.cn多行增加
分析:增加的数据存在换行\n
实例
cat实现多行文本追加
[root@server ~]# cat >>my.log<<EOF
> 你好
> 我好
> 他也好
> EOF
[root@server ~]# cat my.log
你好
我好
他也好echo 追加多行数据
1.多次追加
echo "你好" >> tt.log
[root@server ~]# echo "你好" >> tt.log
[root@server ~]# echo "你好" >> tt.log
[root@server ~]# echo "你好" >> tt.log
[root@server ~]# cat tt.log
你好
你好
你好2.使用换行符,一次添加多行数据
echo -e "hello\nworld\n你好\n我也好" > hello.log
[root@server ~]# echo -e "hello\nworld\n你好\n我也好" > hello.log
[root@server ~]# cat hello.log
hello
world
你好
我也好sed追加多行文本
无论是cat、还是echo,都只能往文件末尾追加内容。
而sed是按行处理文本,可以指定要处理的行,也就是在指定行插入字符数据。
使用\n添加多行数据
1,给t1.log 开头,添加两行数据
加油
奥力给
sed -i '1 i 加油\n奥力给' t1.log
[root@server ~]# sed -i '1 i 加油\n奥力给' t1.log
[root@server ~]# cat t1.log -n
1 加油
2 奥力给
3 My name is yang.
4 今天雾霾比较大
5 I teach linux.
6 今天又是美好的一天
7 I like play computer game.
8 My qq is 877348180.
9 My website is http://www.soloyang.cn删除数据
sed删除字符命令
d 删除指定的行
sed默认是多行处理所有文本,如果不指定范围,sed默认是删除所有文本行数据了实例
这里为了演示就不加
-i参数应用sed命令了。
准备演示数据
[root@server ~]# cat t1.log -n
1 加油
2 奥力给
3 My name is yang.
4 今天雾霾比较大
5 I teach linux.
6 今天又是美好的一天
7 I like play computer game.
8 My qq is 877348180.
9 My website is http://www.soloyang.cn
10 my name is 吴彦祖1,删除第二行数据
[root@server ~]# sed '2 d' t1.log
加油
My name is yang.
今天雾霾比较大
I teach linux.
今天又是美好的一天
I like play computer game.
My qq is 877348180.
My website is http://www.soloyang.cn
my name is 吴彦祖2,删除第1行到第3行数据
[root@server ~]# sed '1,3 d' t1.log
今天雾霾比较大
I teach linux.
今天又是美好的一天
I like play computer game.
My qq is 877348180.
My website is http://www.soloyang.cn
my name is 吴彦祖3,删除所有数据,不加任何范围限制就是删除全部内容。
[root@server ~]# sed 'd' t1.log
[root@server ~]# 4,删除game那一行,以及game的后1行
[root@server ~]# sed '/game/ d' t1.log
加油
奥力给
My name is yang.
今天雾霾比较大
I teach linux.
今天又是美好的一天
My qq is 877348180.
My website is http://www.soloyang.cn
my name is 吴彦祖5,删除第1、2、4行
[root@server ~]# sed '1d;2d;4d' t1.log
My name is yang.
I teach linux.
今天又是美好的一天
I like play computer game.
My qq is 877348180.
My website is http://www.soloyang.cn
my name is 吴彦祖6,删除game和http的行
[root@server ~]# sed '/game/d;/http/d' t1.log
加油
奥力给
My name is yang.
今天雾霾比较大
I teach linux.
今天又是美好的一天
My qq is 877348180.
my name is 吴彦祖7,删除My开头的行
[root@server ~]# sed '/^My/d' t1.log
加油
奥力给
今天雾霾比较大
I teach linux.
今天又是美好的一天
I like play computer game.
my name is 吴彦祖8,删除以.结尾的行
[root@server ~]# sed '/\.$/d' t1.log
加油
奥力给
今天雾霾比较大
今天又是美好的一天
My website is http://www.soloyang.cn
my name is 吴彦祖9,删除第2行到qq的行
[root@server ~]# sed '2,/qq/d' t1.log
加油
My website is http://www.soloyang.cn
my name is 吴彦祖10,删除3到最后一行
[root@server ~]# sed '3,$d' t1.log
加油
奥力给11,删除偶数行(步长)
[root@server ~]# sed '2~2'd t1.log
加油
My name is yang.
I teach linux.
I like play computer game.
My website is http://www.soloyang.cn12,删除奇数行(步长)
[root@server ~]# sed '1~2'd t1.log
奥力给
今天雾霾比较大
今天又是美好的一天
My qq is 877348180.
my name is 吴彦祖13,除了有字符yang的行,其他都删除!d
[root@server ~]# sed '/yang/!d' t1.log
My name is yang.
My website is http://www.soloyang.cn14,删掉除了My开头的行!d
[root@server ~]# sed '/^My/!d' t1.log
My name is yang.
My qq is 877348180.
My website is http://www.soloyang.cn15,删除My,my开头的行Id
[root@server ~]# sed '/^My/Id' t1.log
加油
奥力给
今天雾霾比较大
I teach linux.
今天又是美好的一天
I like play computer game.16,删除除了My,my开头的行I!d
[root@server ~]# sed '/^My/I!d' t1.log
My name is yang.
My qq is 877348180.
My website is http://www.soloyang.cn
my name is 吴彦祖sed修改数据
修改数据,是一大重点,因为我们需要用sed来修改各种配置文件,sed这种非交互式修改文件内容,在脚本中实现自动化修改是最常见的。
修改nginx的端口;
修改mysql的数据存储路径;
替换整行全部命令 c
c 把选定的行改为新的文本。
把11行替换为新数据 , 睡醒了 精神很饱满
语法:
sed ' 11 c 睡醒了,精神很饱满 ' t1.log替换字符命令 s
语法
替换一次,替换每一行的第一个。
sed 's#替换前字符#替换后字符#' filename
全局替换,global 全局替换。
sed 's#替换前字符#替换后字符#g' filename
sed替换的命令解释
这个分隔符,常见有如下形式
sed 's/old_string/new_string/'
sed 's#old_string#new_string#'
sed 's@old_string@new_string@'
强烈建议用#
sed 's#old_string#new_string#'准备演示数据
[root@server ~]# cat t1.log -n
1 加油
2 奥力给
3 My name is yang.
4 今天雾霾比较大
5 I teach linux.
6 今天又是美好的一天
7 I like play computer game.
8 My qq is 877348180.
9 My website is http://www.soloyang.cn
10 my name is 吴彦祖 吴彦祖1,替换第3行数据位我是吴彦祖
[root@server ~]# sed '3c 我是吴彦祖' t1.log
加油
奥力给
我是吴彦祖
今天雾霾比较大
I teach linux.
今天又是美好的一天
I like play computer game.
My qq is 877348180.
My website is http://www.soloyang.cn
my name is 吴彦祖 吴彦祖2,把 吴彦祖 替换为 蔡徐坤替换一次
注意:这是替换每一行的第一个数据。
[root@server ~]# sed 's#吴彦祖#蔡徐坤#' t1.log
加油
奥力给
My name is yang.
今天雾霾比较大
I teach linux.
今天又是美好的一天
I like play computer game.
My qq is 877348180.
My website is http://www.soloyang.cn
my name is 彭于晏 吴彦祖3,把第9行的 My 替换为 You
[root@server ~]# sed '9 s#My#You#' t1.log
加油
奥力给
My name is yang.
今天雾霾比较大
I teach linux.
今天又是美好的一天
I like play computer game.
My qq is 877348180.
You website is http://www.soloyang.cn
my name is 吴彦祖 吴彦祖4,把全部的 M 替换为 m
[root@server ~]# sed 's#M#m#g' t1.log
加油
奥力给
my name is yang.
今天雾霾比较大
I teach linux.
今天又是美好的一天
I like play computer game.
my qq is 877348180.
my website is http://www.soloyang.cn
my name is 吴彦祖 吴彦祖5,替换所有的 my 包括大小写为 you
[root@server ~]# sed 's#My#You#Ig' t1.log
加油
奥力给
You name is yang.
今天雾霾比较大
I teach linux.
今天又是美好的一天
I like play computer game.
You qq is 877348180.
You website is http://www.soloyang.cn
You name is 吴彦祖 吴彦祖6,替换所有的 my 包括大小写为 you,且把 吴彦祖 替换为 彭于晏
[root@server ~]# sed 's#My#You#Ig;s#吴彦祖#彭于晏#' t1.log
加油
奥力给
You name is yang.
今天雾霾比较大
I teach linux.
今天又是美好的一天
I like play computer game.
You qq is 877348180.
You website is http://www.soloyang.cn
You name is 彭于晏 吴彦祖
#注意g的位置,↑是一次替换 吴彦祖,↓是全局替换 吴彦祖
[root@server ~]# sed 's#My#You#Ig;s#吴彦祖#彭于晏#g' t1.log
加油
奥力给
You name is yang.
今天雾霾比较大
I teach linux.
今天又是美好的一天
I like play computer game.
You qq is 877348180.
You website is http://www.soloyang.cn
You name is 彭于晏 彭于晏更加准确的演示
[root@server ~]# cat x2.log
MMM yyy
YYY MMM
mmm YYY
yyy mmm替换一次M为x,y为B
[root@server ~]# sed 's#M#x#;s#y#B#' x2.log
xMM Byy
YYY xMM
mmm YYY
Byy mmm全局替换M为x,而替换一次y为B
[root@server ~]# sed 's#M#x#g;s#y#B#' x2.log
xxx Byy
YYY xxx
mmm YYY
Byy mmm全局替换M m为x,而替换一次y为B
[root@server ~]# sed 's#M#x#Ig;s#y#B#' x2.log
xxx Byy
YYY xxx
xxx YYY
Byy xxx全局替换M m为x,Y y为B
[root@server ~]# sed 's#M#x#Ig;s#y#B#Ig' x2.log
xxx BBB
BBB xxx
xxx BBB
BBB xxx7,sed使用shell变量
sed要替换数据,替换的内容是从shell变量里拿到的
new_name="彭于晏"
注意单引号、双引号的对变量的解析作用
[root@server ~]# new_name="彭于晏"
[root@server ~]# sed "s#yang#$new_name#g" t1.log
加油
奥力给
My name is 彭于晏.
今天雾霾比较大
I teach linux.
今天又是美好的一天
I like play computer game.
My qq is 877348180.
My website is http://www.solo彭于晏.cn
my name is 吴彦祖 吴彦祖8,sed分组替换
注意:别忘了扩展正则
-r参数
语法:
sed软件也提供了 \(\)分组功能
使用\1引用第一个括号的数据
\2引用第二个括号的数据
sed最多记住9个分组
() \1向后引用分组数据测试数据
echo 'I am teacher yuchao,welcome my linux course'要求:提取出welcome这个单词
[root@server ~]# echo 'I am teacher yuchao,welcome my linux course' | sed -r 's#^.*,(.*)\s+m.*#\1#g'
welcome图解sed -r 's#^.*,(.*)\s+m.*#\1#g'
9,分组取出ip地址
\s表示单个空格
去头去尾法
[root@server ~]# ifconfig ens33 | sed -e '2s#^.*inet##' -e '2s#netmask.*##p' -n
10.0.0.130 图解sed -e '2s#^.*inet##' -e '2s#netmask.*##p' -n
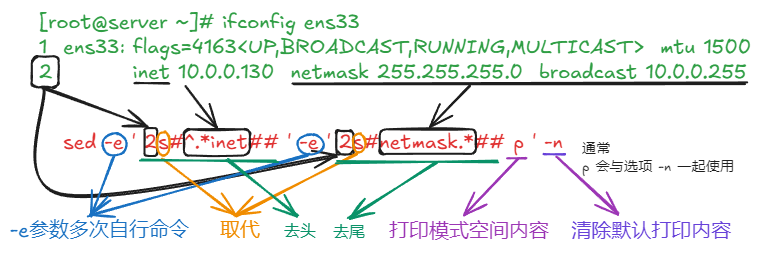
分组提取法
[root@server ~]# ifconfig ens33 | sed -r '2s#^.*inet(.*)netmask.*#\1#p' -n
10.0.0.130
#简写
[root@server ~]# ifconfig ens33 | sed -r '2s#^.*i(.*)n.*#\1#p' -n
10.0.0.130 sed查询数据
sed打印命令p 打印sed正则处理后的数据
并且sed默认打印模式空间,可以用-n取消
文本,10数据 > sed 一行一行的读取,编辑 >> 打印
固定用法,只要使用到了p打印些数据,就是想输出指定数据
必然用-n取消默认打印,目的是,只看到你想p打印的那些数据
准备演示数据
[root@server ~]# cat t1.log -n
1 加油
2 奥力给
3 My name is yang.
4 今天雾霾比较大
5 I teach linux.
6 今天又是美好的一天
7 I like play computer game.
8 My qq is 877348180.
9 My website is http://www.soloyang.cn
10 my name is 吴彦祖实例
1,打印前三行
[root@server ~]# sed '1,3p' t1.log -n
加油
奥力给
My name is yang.2,只显示qq号那一行
[root@server ~]# sed -r '/qq/p' t1.log -n
My qq is 877348180.3,找出http和linux的行
[root@server ~]# sed '/http/p;/linux/p' -n t1.log
I teach linux.
My website is http://www.soloyang.cn
[root@server ~]# sed -e '/http/p' -e '/linux/p' t1.log -n
I teach linux.
My website is http://www.soloyang.cnsed其他命令
w命令
作用是将sed操作结果,写入到指定文件中
语法
sed '/模式/w new_file' old_file
必须,找出computer这一行,数据写入到game2.log文件中
[root@server ~]# sed '/computer/w game2.log' t1.log -n
[root@server ~]# cat game2.log
I like play computer game.替换文件中所有的 yang 为 彭于晏 ,新数据写入 yang.log
[root@server ~]# sed 's#yang#彭于晏#gw yang.log' t1.log -n
[root@server ~]# cat yang.log
My name is 彭于晏.
My website is http://www.solo彭于晏.cn-e选项
-e 选项用于接上sed多个命令
提取1,2,4行信息
语法
sed -e 'sed命令' -e 'sed命令' -e 'sed命令'
sed -e '1p' -e '2p' -e '4p' t1.log -n ; 分号
分号也用于执行多条命令,和linux基础命令一样支持这种写法。
单独提取出1,2,4行信息
sed '1p;2p;4p' t1.log -n[root@server ~]# sed -e '1p' -e '2p' -e '4p' t1.log -n
加油
奥力给
今天雾霾比较大
[root@server ~]# sed '1p;2p;4p' t1.log -n
加油
奥力给
今天雾霾比较大awk
awk语法格式
awk指令是由 模式,动作,或者模式和动作的组合 组成。
模式即 pattern,可以类似理解成 sed 的模式匹配,可以由表达式组成,也可以使两个正斜杠之间的正则表达式。比如 NR==1,这就是模式,可以把他理解为一个条件。
动作即 action,是由在大括号里面的一条或多条语句组成,语句之间使用分号隔开,如下 awk 使用格式。
Action指的是动作,awk擅长文本格式化,且输出格式化后的结果,因此最常用的动作就是
print
awk模式、动作
模式,是指,要操作哪些行。
动作,是指,找到这些行之后,干什么,如何处理。
生成测试数据
[root@server ~]# echo cc{01..50} | xargs -n 5
cc01 cc02 cc03 cc04 cc05
cc06 cc07 cc08 cc09 cc10
cc11 cc12 cc13 cc14 cc15
cc16 cc17 cc18 cc19 cc20
cc21 cc22 cc23 cc24 cc25
cc26 cc27 cc28 cc29 cc30
cc31 cc32 cc33 cc34 cc35
cc36 cc37 cc38 cc39 cc40
cc41 cc42 cc43 cc44 cc45
cc46 cc47 cc48 cc49 cc50
写入文件,生成测试数据文件
echo cc{01..50} | xargs -n 5 > yang.log无模式、只有动作
不写模式、默认处理每一行
动作是 {print $0} 这个$0是表示列的数据,默认是表示一整行数据
关于字段的取值语法
是
$0 表示所有字段数据
$1 第一列数据
$2 第二列数据
依次类推
......
$1,$3 第一列和第三列数据1,直接输出源文件,所有内容
[root@server ~]# awk '{print $0}' yang.log
cc01 cc02 cc03 cc04 cc05
cc06 cc07 cc08 cc09 cc10
cc11 cc12 cc13 cc14 cc15
cc16 cc17 cc18 cc19 cc20
cc21 cc22 cc23 cc24 cc25
cc26 cc27 cc28 cc29 cc30
cc31 cc32 cc33 cc34 cc35
cc36 cc37 cc38 cc39 cc40
cc41 cc42 cc43 cc44 cc45
cc46 cc47 cc48 cc49 cc502,输出每一行数据,只要第一列和第三列的数据
[root@server ~]# awk '{print $1,$3}' yang.log
cc01 cc03
cc06 cc08
cc11 cc13
cc16 cc18
cc21 cc23
cc26 cc28
cc31 cc33
cc36 cc38
cc41 cc43
cc46 cc48行变量NR、匹配范围语法
刚才是没指定处理那一行,默认是所有行
可以指定对某一行处理了
语法说明,内置变量NR,表示awk处理的每一行
number of record (记录,行的意思)
NR ============== 行号
#格式说明
NR 行
直接打印这个内置变量,表示取当前行的号码
#在开头显示行号
[root@server ~]# awk '{print NR,$0}' yang.log
1 cc01 cc02 cc03 cc04 cc05
2 cc06 cc07 cc08 cc09 cc10
3 cc11 cc12 cc13 cc14 cc15
4 cc16 cc17 cc18 cc19 cc20
5 cc21 cc22 cc23 cc24 cc25
6 cc26 cc27 cc28 cc29 cc30
7 cc31 cc32 cc33 cc34 cc35
8 cc36 cc37 cc38 cc39 cc40
9 cc41 cc42 cc43 cc44 cc45
10 cc46 cc47 cc48 cc49 cc50
#在结尾显示行号
[root@server ~]# awk '{print $0,NR}' yang.log
cc01 cc02 cc03 cc04 cc05 1
cc06 cc07 cc08 cc09 cc10 2
cc11 cc12 cc13 cc14 cc15 3
cc16 cc17 cc18 cc19 cc20 4
cc21 cc22 cc23 cc24 cc25 5
cc26 cc27 cc28 cc29 cc30 6
cc31 cc32 cc33 cc34 cc35 7
cc36 cc37 cc38 cc39 cc40 8
cc41 cc42 cc43 cc44 cc45 9
cc46 cc47 cc48 cc49 cc50 10
NR== 等于行
#打印第2行的所有字段数据
[root@server ~]# awk 'NR==2{print $0}' yang.log
cc06 cc07 cc08 cc09 cc10
#打印第2行的,第1列,和第4列数据
[root@server ~]# awk 'NR==2{print $1,$4}' yang.log
cc06 cc09
NR>= 大于等于行
NR<= 小于等于
NR>=N && NR<=M 从N行到M行
#打印第1行到第2行的,第1列和第3列数据
[root@server ~]# awk 'NR>=1 && NR<=2{print $1,$4}' yang.log
cc01 cc04
cc06 cc09
|| 或的用法列变量NF、每一列的字段
number of field (字段的数量) =====NF====等于列的总数
直接写NF变量表示每一行字段的总数
这个NF,默认表示,字段的总数
$0,NF 查看每一行有多少个字段
[root@server ~]# awk '{print $0,NF}' yang.log
cc01 cc02 cc03 cc04 cc05 5
cc06 cc07 cc08 cc09 cc10 5
cc11 cc12 cc13 cc14 cc15 5
cc16 cc17 cc18 cc19 cc20 5
cc21 cc22 cc23 cc24 cc25 5
cc26 cc27 cc28 cc29 cc30 5
cc31 cc32 cc33 cc34 cc35 5
cc36 cc37 cc38 cc39 cc40 5
cc41 cc42 cc43 cc44 cc45 5
cc46 cc47 cc48 cc49 cc50 5
$NF 输出最后一列
[root@server ~]# awk '{print $NF}' yang.log
cc05
cc10
cc15
cc20
cc25
cc30
cc35
cc40
cc45
cc50
$(NF-1) 输出倒数第2列
[root@server ~]# awk '{print $(NF-1)}' yang.log
cc04
cc09
cc14
cc19
cc24
cc29
cc34
cc39
cc44
cc49多个模式和动作(解释NR、NF)
指定行,
NR==4,number of record,行号的记录指定动作
awk '{print $0,NF,NR}' yang.log内置变量$0表示整行数据
NF表示Number of filed,字段的数量,表示这一行数据分了几列
NF表示字段总数
$NF表示取最后一个字段的值
NR表示,number of record,行号的记录,表示在处理第几行
打印前四行数据,要求输出每一行的行号、字段数、以及对应行的数据
awk 'NR<=4{print NR,NF,$0 }' yang.logawk快速入门小结
pattern和action都要用单引号,防止shell作特殊解释(是交给awk去执行的,而不是bash)
不指定模式,awk默认处理输入的文件数据,每一行,每一列
如果指定模式,例如指定的行,awk就处理指定那一行的数据
awk的动作,必须写在花括号里
{print}括号里写入awk提供的命令。
如果没有
{ }花括号,就会被识别为patter,而不是action
注意给awk传入数据,一般都是file
也可以是管道传递的数据
拿到第二行的,倒数第二列的数据
cat yang.log | awk 'NR==2{print $(NF-1)}'
cc09awk其他内置变量
参考国外awk网址
awk的其他内置变量如下。
FILENAME:当前文件名
===================awk在数据输入时,的一个分隔符===================
FS:字段分隔符,默认是空格和制表符。
Input field separator variable.输入字段分隔符变量。
RS:行分隔符,用于分割每一行,默认是换行符。
Record Separator variable,行分隔符变量
============awk处理完毕后,打印的数据格式,分隔符=================
OFS:输出字段的分隔符,用于打印时分隔字段,默认为空格。
Output Field Separator Variable,输出字段分隔符变量
ORS:输出记录的分隔符,用于打印时分隔记录,默认为换行符。
Output Record Separator Variable,输出记录分隔符变量
OFMT:数字输出的格式,默认为%.6g。FS===========数据输入的字段分隔符,默认是` `【空格】
(awk读取的这个数据,以什么分隔符去读,去分割它的数据)
RS============record separator 行分隔符,默认是`\n`【换行符】
awk行操作RS(分行符修改)
语法
awk -v RS='[输入数据]' '{[打印数据]}' 文件路径实例
准备测试数据
[root@server ~]# echo cc{01..15} | xargs -n 5
cc01 cc02 cc03 cc04 cc05
cc06 cc07 cc08 cc09 cc10
cc11 cc12 cc13 cc14 cc15
写入文件,生成测试数据文件
echo cc{01..15} | xargs -n 5 > awk_test.log1,将文件的内容单独一行输出
#其实就是把' '【空格】替换为换行符
[root@server ~]# awk -v RS=' ' '{print $0}' awk_test.log
cc01
cc02
cc03
cc04
cc05
cc06
cc07
cc08
cc09
cc10
cc11
cc12
cc13
cc14
cc15修改ORS/修改awk输出显示
当awk处理完毕后,print打印结果,默认也是 一个换行符
awk给这个默认打印的结果,结尾加上的是 换行符
你可以修改这个,awk的输出行分隔符,默认是 换行符
把awk输出的行分隔符,改为 @@
修改 ORS变量为@@
[root@server ~]# awk -v ORS='@@' '{print $0}' awk_test.log
cc01 cc02 cc03 cc04 cc05@@cc06 cc07 cc08 cc09 cc10@@cc11 cc12 cc13 cc14 cc15
你可以自由修改,awk处理完毕后的每一行的分隔符,也就是修改ORS变量。
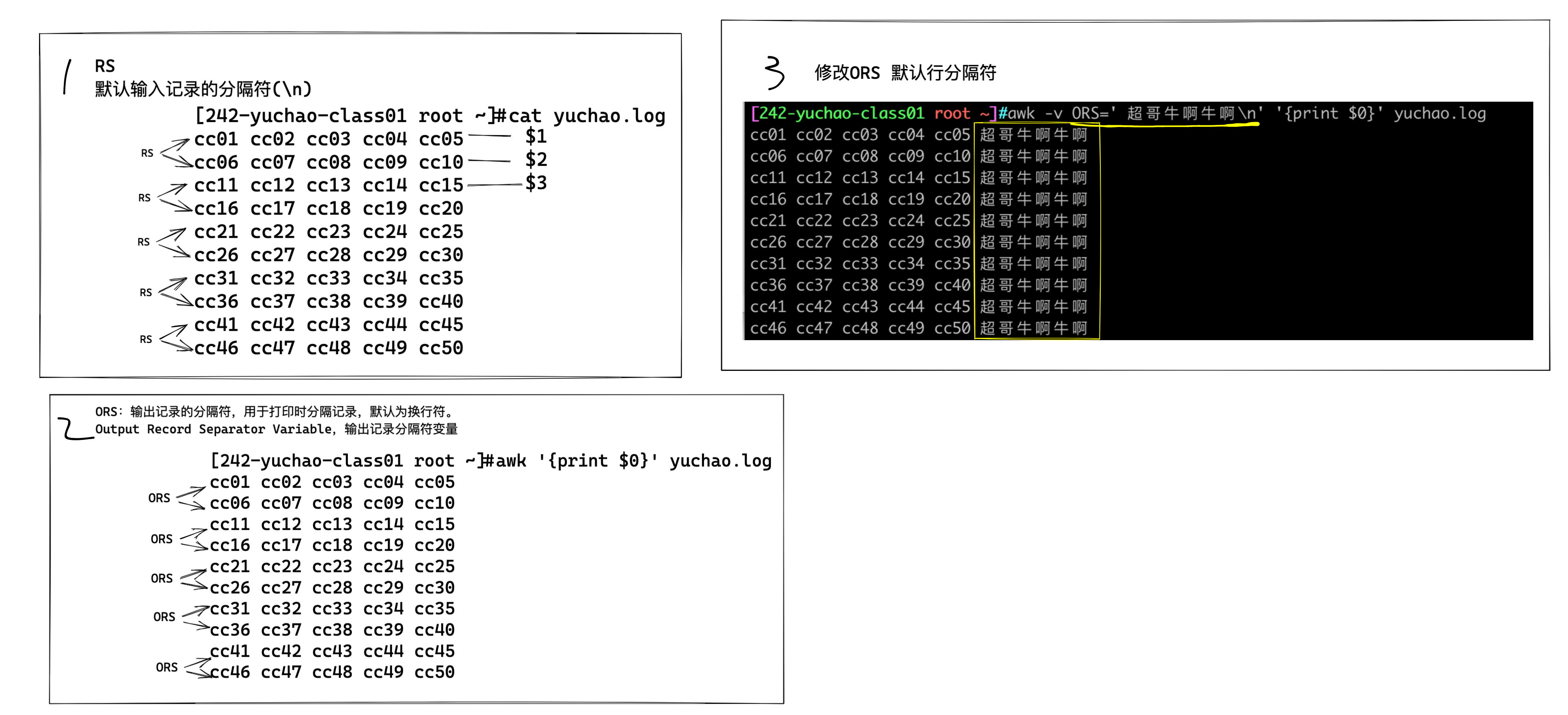
面试题,统计单词出现频率
统计如下内容单词出现的频率,并只要前五组的单词。
[root@server ~]# cat english.log
I have a dog, it is lovely, it is called Mimi. Every time I go home from school, Mimi always cruising around me, I will go to the kitchen to get a piece of meat to it, it lay on the floor to eat. My legs and then jump to bark "Wang "called, so I picked up Mimi, it is the opportunity to lick my hand, making me laugh.I like Mimi, like puppies.解决思路
1.将一整行的数据改为,每一个单词,就是一行
2.改为这样后,就可以交给sort去排序了
3.再去uniq 去重 -c 统计重复的次数
4.最后head -5 取出前5组数据1,sed替换法
思路就是
将除大小写字母外的数据替换为换行符\n
sed -r 's#[^a-zA-Z]+#\n#g' english.log | sort | uniq -c | sort -r -n | head -5
[root@server ~]# sed -r 's#[^a-zA-Z]+#\n#g' english.log | sort | uniq -c | sort -r -n | head -5
6 to
5 it
5 I
4 Mimi
3 the2,tr替换法
tr命令就是将字符替换的作用
基本语法
[root@server ~]# echo 'hello world' | tr 'll' 'LL'
heLLo worLd思路就是 cat查看文本内容再用 tr命令 将文本中的空格,换为 \n ,就实现了每一个单词,作为新的一行
cat english.log |tr ' ' '\n' | sort | uniq -c | sort -r -n | head -5
[root@server ~]# cat english.log |tr ' ' '\n' | sort | uniq -c | sort -r -n | head -5
6 to
4 it
4 I
3 the
3 is注:但是可以看到提取的数据有误,暂时保留该方法
出现问题的原因是因为该命令不支持正则表达式用不了
[ ^a-zA-Z]+(提取除大小写英文之外的数据),实际上什读取不了^符但是如果其他三种方法不提取
[ ^a-zA-Z]+(提取除大小写英文之外的数据)这种方法是没问题的,考虑到实际应用层面还是不建议使用该方法。
3,grep查询法
思路是
利用 grep 查询命令将除大小写字母外的数据提取出来交给 -o 参数单行显示
grep -E '[a-zA-Z]+' english.log -o | sort | uniq -c | sort -r -n | head -5
[root@server ~]# grep -E '[a-zA-Z]+' english.log -o | sort | uniq -c | sort -r -n | head -5
6 to
5 it
5 I
4 Mimi
3 the4,awk替换法
简单考虑,直接考虑输入的行分隔符,改为` `空格
1.将一整行的数据,改为,每一个单词,就是一行
awk -v RS=' ' '{print $0}' english.log
2.改为这样后,就可以交给sort去排序了,将子母一样的,搁一块
awk -v RS=' ' '{print $0}' english.log | sort
3.再去uniq 去重 -c 统计重复的次数
awk -v RS=' ' '{print $0}' english.log | sort |uniq
4.并且统计出现最多的前5个
awk -v RS=' ' '{print $0}' english.log | sort |uniq -c | sort -r | head -5
就是用正则,提取,大小写字母
5.复杂考虑
awk -v RS='[^a-zA-z]+' '{print $0}' english.log | sort | uniq -c | sort -r -n | head -5
[root@server ~]# awk -v RS='[^a-zA-z]+' '{print $0}' english.log | sort | uniq -c | sort -r -n | head -5
6 to
5 it
5 I
4 Mimi
3 theawk列操作FS(分隔符修改)
每条记录都是由多个区域(field)组成的
每一行数据,都被分割为了很多个字段
默认情况下区域之间的分隔符是由空格(即空格或制表符)来分隔
将分隔符记录在内置变量 FS中
每行记录的区域数据保存在 awk 的内置变量 NF 中
图解awk字段
FS 即 fileld separator,输入字段(列)分隔符,分隔符就是菜刀,把一行字符串切为很多区域
NF 即 number of fileds,表示一行中列(字段)的个数,可以理解为菜刀切过一行后,切成了多少份
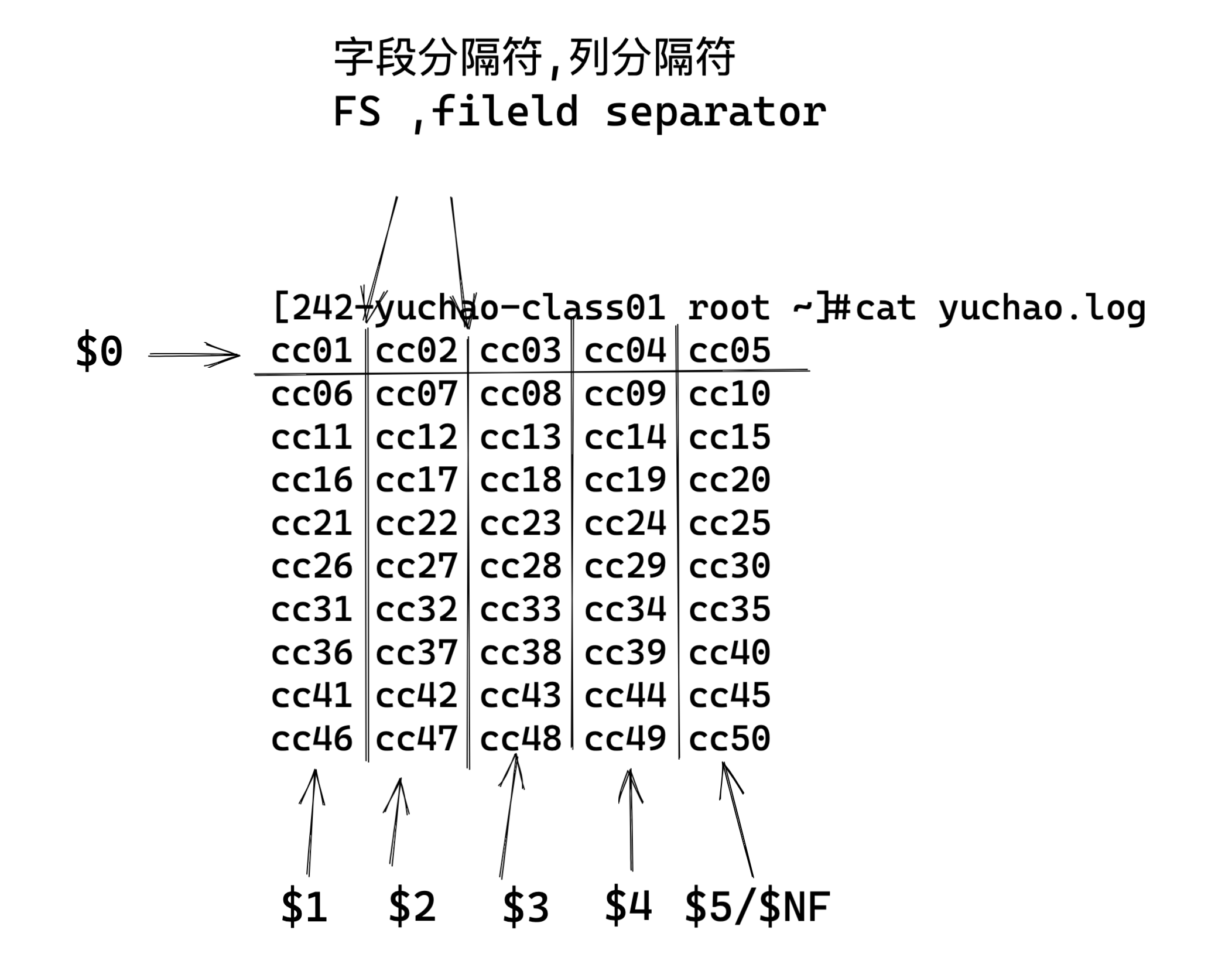
指定分隔符
当文本不是以空格分割,你得自己找特征,进行切蛋糕。
FS的值可以是固定的字符、也可以是正则表达式
例如/etc/passwd文件 ,提取用户信息
提取出用户名、登录解释器
awk -v FS=':' '{print $1,$NF }' /etc/passwd
# 美化显示的命令column -t
[root@server ~]# awk -v FS=':' '{print $1,$NF }' /etc/passwd |column -t提取用户账号密码信息
生成测试数据,python脚本
#coding:utf-8
#导入random模块生成随机数字
import random
#导入CSV模块,用于数据写入到CSV
import csv
#创建一个空列表,后面可以把生成的用户名、密码、身份证号码存放进来
list = []
#把CSV文件绝对路径赋值给一个变量
file_path ='user_id.csv'
#从1开始循环100次
for i in range(1, 101):
#生成18位随机身份证号,生成的随机数在100000000000000000,和999999999999999999之间
ID =random.randint(100000000000000000, 999999999999999999)
#添加用户名到列表1ist中,用户名默认以test开头,后面跟上数字,数字是当前循环的次数,如:test1
list.append('test%s' % i)
#添加用户密码到1ist中,密码全部默认为123456
list.append('123456')
#把生成的身份证号码添加到1ist,添加时需要在后面加“\t”,不加“\t”则在CSV中会显示成科学计数,如:8.39381E+17
list.append(str(ID) + '\t')
#下面三行是把1ist内容写入到CSV文件中的代码
with open(file_path, 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(list)
#把1ist内容清空
list = [][root@server ~]# yum install python3 python3-devel -y
[root@server ~]# python3 user.py
[root@server ~]# ls
anaconda-ks.cfg initial-setup-ks.cfg user_id.csv user.py如何去提取里面的数据
思考,分析该数据的 每一个字段的分隔符是否有特点
提取该分隔符
准备测试数据
[root@server ~]# cat user_id.csv
test1,123456,898907025069288822
test2,123456,930102322533847534
test3,123456,258733755211834488
test4,123456,404641745727737166
test5,123456,800219181216995742
test6,123456,756701201229967857
test7,123456,604869432725968327
test8,123456,646646752552727304
test9,123456,954945090943629816
test10,123456,408353602886485142提取用户的数据
[root@server ~]# awk -v FS=',' '{print $1,$2,$3}' user_id.csv
test1 123456 898907025069288822
test2 123456 930102322533847534
test3 123456 258733755211834488
test4 123456 404641745727737166
test5 123456 800219181216995742
test6 123456 756701201229967857
test7 123456 604869432725968327
test8 123456 646646752552727304
test9 123456 954945090943629816
test10 123456 408353602886485142提取5号用户的用户名、身份证号,且显示行号
[root@server ~]# awk -v FS=',' 'NR==5{print $1,$3,NR}' user_id.csv
test5 800219181216995742 5awk内置变量梳理
关于行的内置变量,RS、ORS
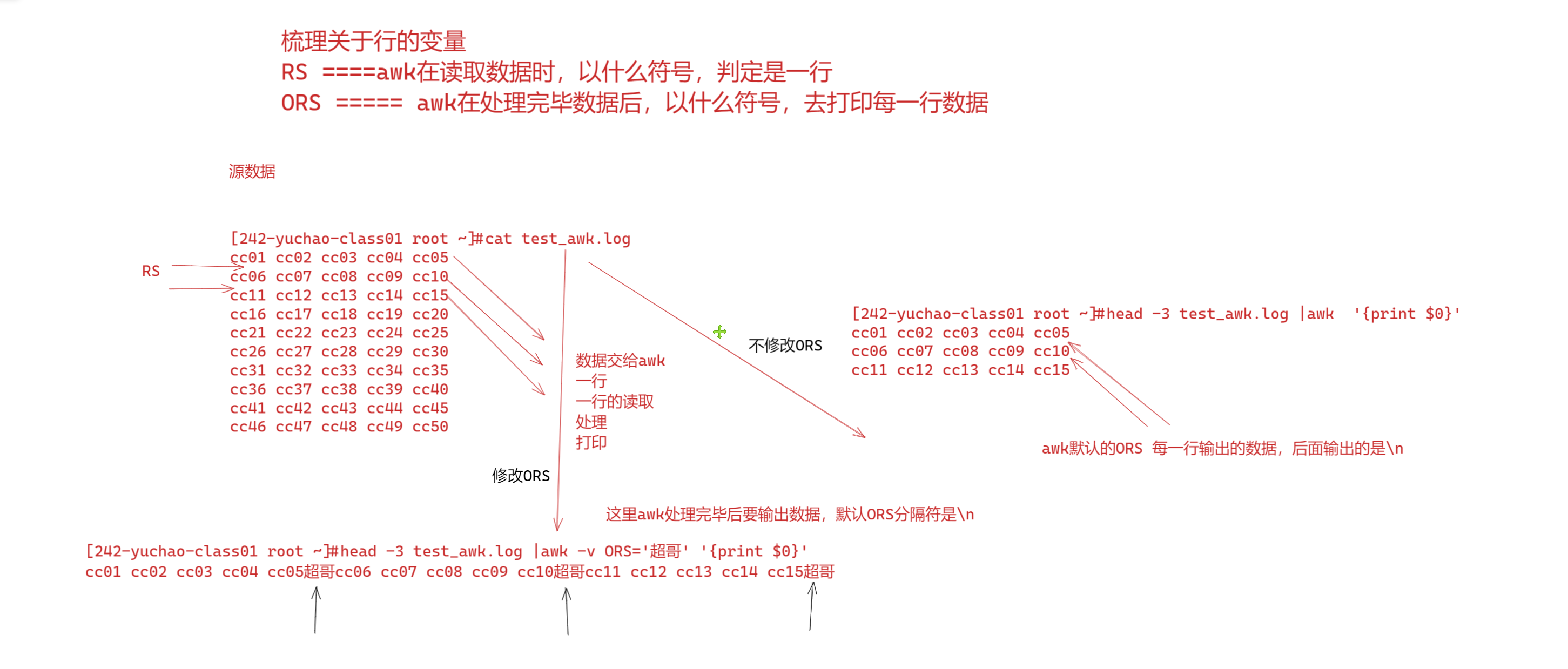
关于列的变量
FS,提取数据时,提取的字段,以什么字符进行切割,分割
OFS,打印数据时,每一个字段之间的分隔符是什么
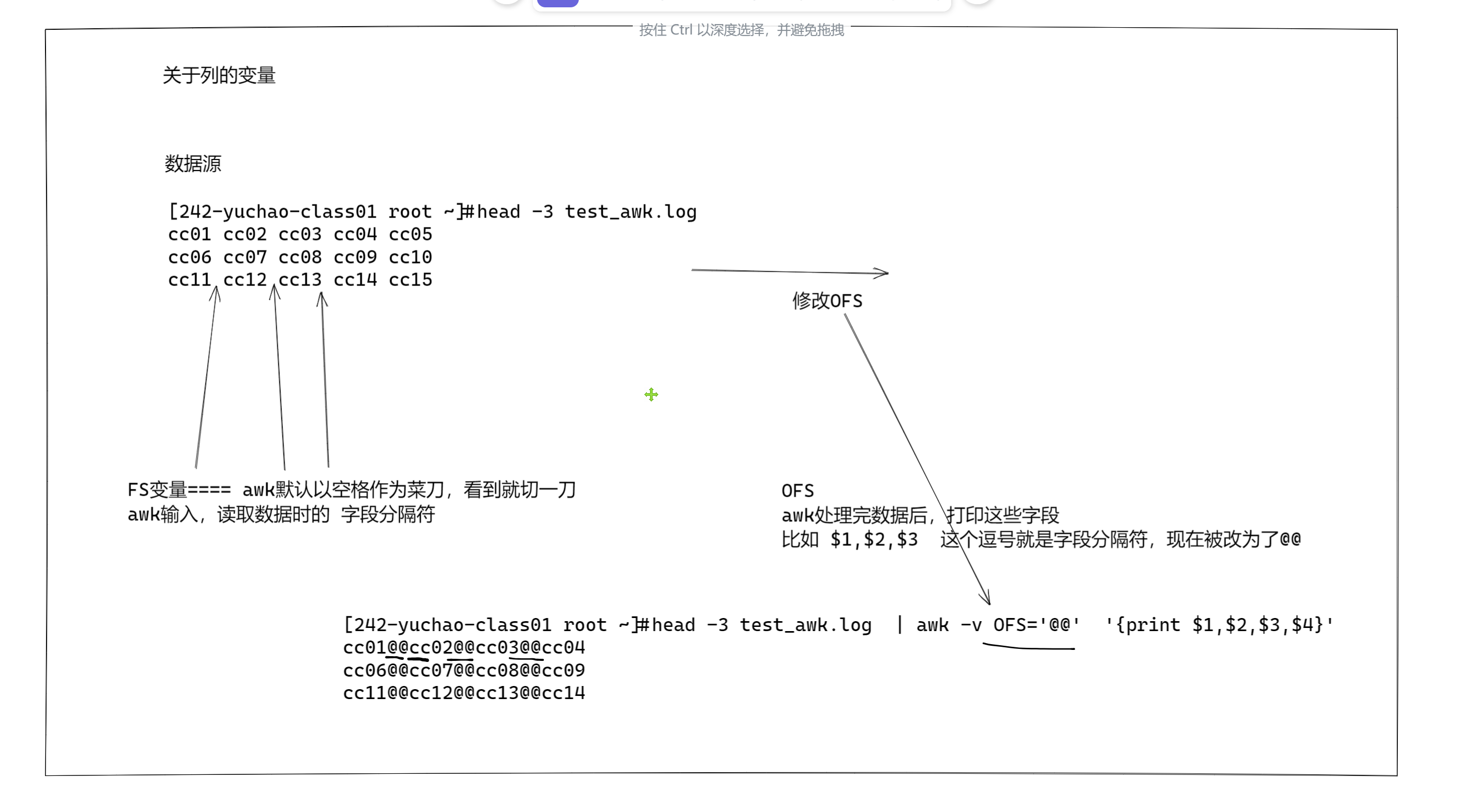
修改FS和OFS变量
刚才我们练习了
RS和ORS
RS、输入记录分隔符,决定awk如何分隔每一行(默认是\n)
ORS,输出记录分隔符,决定awk如何输出每一行(默认是\n)
FS和OFS
FS是输入字段分隔符,决定awk输入数据后的每一个字段分隔符是什么,默认是空格
OFS是输出字段分隔符,决定awk输出每个字段的分隔符是什么,默认是空格
指定FS分隔符
两个方式
1、参数
awk -F '分隔符'
2.修改变量
awk -v FS='分隔符'当你拿到一个数据文本,并非是很直观的可以看出 空格分割的数据
那么你就得自己找规律,如何提取该数据,也就是指定分隔符,修改FS变量。
指定OFS分隔符
要求修改每一个数据之间的分隔符,改为#号
$1 ,$2 是字段之间的逗号,和OFS对应
[root@server ~]# awk -v OFS='#' '{print $1,$2,$3,$4,$5}' test_awk.log
cc01#cc02#cc03#cc04#cc05
cc06#cc07#cc08#cc09#cc10
cc11#cc12#cc13#cc14#cc15
cc16#cc17#cc18#cc19#cc20
cc21#cc22#cc23#cc24#cc25
cc26#cc27#cc28#cc29#cc30
cc31#cc32#cc33#cc34#cc35
cc36#cc37#cc38#cc39#cc40
cc41#cc42#cc43#cc44#cc45
cc46#cc47#cc48#cc49#cc50修改/etc/passwd的格式
修改原本用户信息的冒号分隔符、改为---
提取出 root、家目录、登录解释器
head -5 /etc/passwd|awk -v FS=':' -v OFS='---' 'NR==1{print $1, $(NF-1),$NF}' 图解修改FS、OFS

总结行、列
RS、ORS、代表了awk的输入、输出、关于
行的分隔符FS、OFS、代表了awk的输入、输出、关于
列的分隔符对于不同的文本,需要选择合适的FS、合适的菜刀,来分割出左右可以便于提取的数据
NR表示行号、记录号
NF表示每一行的字段数、有多少列
$符号一般用于提取某一列的数据,如$1、$2
$NF表示最后一列的数据
进价
awk模式种类
awk的模式匹配
NR 针对行号的比较,
==
>=
模式,是指定了第二行
awk 'NR==2{print $0}'
关于awk的正则匹配
语法
模式,指定正则
awk '/正则/{print $0}'awk的模式分为这几种
正则表达式
基本正则
扩展正则
比较表达式
范围表达式
特殊模式
BEGIN
END
awk比较运算符(语法)
关于数值的比较
关于字符串的匹配
| ~ | 匹配正则 | x~/正则/ |
| !~ | 与表达式不匹配 | x!~/正则/ |正则表达式语法(awk模式)
正则表达式作用在于在行数据中匹配想要的字符串、然后执行对应的action动作
支持基本正则、扩展正则
awk '/正则表达式/{print $0}'再来看一下awk的语法,模式也可以理解为是条件
awk [option] 'pattern[action]' file ...awk默认是按行处理文本,如果不指定任何模式(条件),awk默认一行行处理
如果指定了模式,只有符合模式的才会被处理
经典语法图解

awk特殊模式BEGIN和END
BEGIN模式
BEGIN模式作用是在awk开始读取文件行数据、之前就先执行,一般用于预定义一些操作,比如数据的表头格式化等。
BEGIN后面必须跟上action动作
BEGIN打印
语法
awk 'BEGIN{print "你好"}{print $0}' 显示/etc/passwd前五行,且加上打印BEGIN动作,打印"awk正在执行中" 表头
awk ' BEGIN{print "awk正在执行中" } NR<=5 {print $0}' /etc/passwd语法
awk 'BEGIN{} 模式 {动作}'END{} 特殊模式
BEGIN{} 用于awk执行之前的操作
END{} awk所有行数据处理完毕后,做什么事
语法
awk 'BEGIN{print "你好 "} 模式 {动作} END{print "awk完事了"}' Shell脚本编程初体验
配置yum仓库
配置本地yum源仓库光盘
备份yum源
mkdir /etc/yum.repos.d/bck #创建备份文件夹
mv /etc/yum.repos.d/*.repo /etc/yum.repos.d/bak #移动所以得repo后缀的文件到bak目录下创建自己的yum仓库配置文件
#先复制这个代码块到命令终端中,并按回车执行它
vi /etc/yum.repos.d/iso.repo
[iso]
name=ISO Repository
baseurl=file:///mnt/iso
enabled=1
gpgcheck=0访问ISO中文件数据
到目前为止,我们自己的yum软件仓库配置文件就写好了。现在回过头来看看/etc/yun.repos. d/iso.repo的内容,只需要关注baseur1=file:///mnt/iso 这句话,这句话的意思是软件仓库在/mnt/iso 这个目录下。那这个目录是否存在呢?或者说这个目录下是否有软件包的数据呢?我们一块来看看。
创建/mnt/iso目录
mkdir -p /mnt/iso此时虽然
/mnt/iso目录已经创建了,但里面并没有数据啊。数据从哪里来呢?数据都在安装系统的ISO文件里面,我们需要访问系统ISO文件中的数据,这有办法办到吗?
答案是有的,具体做法如下:
1.复制系统安装的ISO文件到/opt目录下(使用scp命令或者其他图形化的软件操作)
[root@localhost opt]# scp 172.16.208.33:/var/www/html/web/images/CentOS-7-x86_64-Minimal-1804.iso
注意:这是自建的yum源局域网仓库可能访问不了。
#我这里直接将CentOS-7-x86_64-Minimal-1804.iso文件拷贝到Linux系统中了。如果是虚拟机的话可以通过光盘挂载
[root@server yum.repos.d]# ls -l /dev/
total 0
lrwxrwxrwx 1 root root 3 Aug 22 15:24 cdrom -> sr0
#可以找到光盘挂载文件cdrom2.挂载ISO文件到/mnt/iso目录下,命令如下:
mount -o loop /opt/Cent0S-7-x86_ 64-Minimal-1804.iso /mnt/iso
-o 是以只读方式挂载
查看是否挂载
lsblk以光盘形式挂载
[root@167 opt]# mount /dev/sr0 /mnt/cdrom_iso
mount: /dev/sr0 写保护,将以只读方式挂载1、mount:
用于查看哪个模块输入只读,一般显示为:
[root@localhost ~]# mount
/dev/cciss/c0d0p2 on / type ext3 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
/dev/cciss/c0d0p7 on /home type ext3 (rw)
/dev/cciss/c0d0p6 on /var type ext3 (rw)
/dev/cciss/c0d0p3 on /usr type ext3 (rw)
/dev/cciss/c0d0p1 on /boot type ext3 (rw)
tmpfs on /dev/shm type tmpfs (rw)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw)
/dev/dm-0 on /home/book/upload/BookFile1 type ext3 (rw)
/dev/dm-1 on /home/book/upload/BookFile2 type ext3 (rw)
/dev/dm-2 on /backup type ext3 (rw)
/dev/dm-3 on /home/book/upload/BookFile3 type ext3 (ro)
2、如果发现有ro,就重新mount,或者umount以后再remount
3、umount /dev/dm-3
如果发现有提示“device is busy”,找到是什么进程使得他busy
fuser -m /mnt/data 将会显示使用这个模块的pid
fuser -mk /mnt/data 将会直接kill那个pid
然后重新mount即可。
4、还有一种方法是直接remount,命令为
mount -o rw,remount /mnt/data3.再次查看/mnt/iso 目录,查看到如下内容:
[root@localhost opt]# ll /mnt/iso/
total 108
-rw-rw-r-- 1 root root 14 May 2 2018 CentOS_BuildTag
drwxr-xr-x 3 root root 2048 May 4 2018 EFI
-rw-rw-r-- 1 root root 227 Aug 30 2017 EULA
-rw-rw-r-- 1 root root 18009 Dec 10 2015 GPL
drwxr-xr-x 3 root root 2048 May 4 2018 images
drwxr-xr-x 2 root root 2048 May 4 2018 isolinux
drwxr-xr-x 2 root root 2048 May 4 2018 LiveOS
drwxrwxr-x 2 root root 71680 May 4 2018 Packages
drwxrwxr-x 2 root root 4096 May 4 2018 repodata
-rw-rw-r-- 1 root root 1690 Dec 10 2015 RPM-GPG-KEY-CentOS-7
-rw-rw-r-- 1 root root 1690 Dec 10 2015 RPM-GPG-KEY-CentOS-Testing-7
-r--r--r-- 1 root root 2883 May 4 2018 TRANS.TBL能看到/mnt/iso 目录下的有数据之后说明访问ISO文件就成功了。
加载本地yum源&测试
# 清除yum缓存
yum clean all
# 缓存本地yum源
yum makecache
# 测试yum本地源
yum list配置阿里yum源软件仓库
CentOS
阿里源地址
https://developer.aliyun.com/mirror/这里配置下载两个软件仓库
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo运行
yum clean all清除缓存运行
yum makecache生成缓存
Ubuntu
1,打开Ubuntu的apt源配置文件
备份源文件
sudo cp /etc/apt/sources.list{,.bak}
sudo vim /etc/apt/sources.list2,查询系统版本
uname -a
#或者
cat /etc/os-release 3,Ubuntu 20.04 LTS (focal) 配置如下
deb https://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
# deb https://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
# deb-src https://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverseapt-get update更新apt源
自建私有yum源云仓库
1,创建一个存放软件的目录
[root@server ~]# mkdir /usr/local/software2,准备软件的所有rpm包,你可以选择用光盘仓库,也可以用这个神奇的办法
拿vim举例,安装vim以及它的依赖包
yum install --downloadonly --downloaddir=/0224_software/ vim也可从宿主机拷贝rpm包及其依赖包。
3,使用命令,让该目录成为yum可识别仓库
yum install createrepo -y4,使用该createrepo命令,创建本地仓库
createrepo /usr/local/software
[root@server software]# createrepo /usr/local/software
Spawning worker 0 with 55 pkgs
Spawning worker 1 with 54 pkgs
Workers Finished
Saving Primary metadata
Saving file lists metadata
Saving other metadata
Generating sqlite DBs
Sqlite DBs complete
[root@server software]# ll /usr/local/software/ -a
总用量 63544
drwxrwxrwx 3 root root 8192 8月 23 16:30 .
drwxr-xr-x. 13 root root 147 8月 23 16:19 ..
-rw-rw-r-- 1 admin admin 106124 8月 23 16:27 apr-1.4.8-7.el7.x86_64.rpm
-rw-rw-r-- 1 admin admin 94424 8月 23 16:27 apr-util-1.5.2-6.el7_9.1.x86_64.rpm5,此时,创建repo文件,指向这个目录即可,就是一个本地仓库目录,你先移除其他的repo文件,让yum被识别
cat >> /etc/yum.repos.d/rpm.repo <<EOF
[base]
name=local_rpm
baseurl=file:///usr/local/software/
enabled=1 # 这个参数是控制,该repo启用,还是关闭的
gpgcheck=0
EOF6,清除缓存,生成缓存
yum clean all
yum makecache6,测试装zabbix监控组建
[root@server yum.repos.d]# yum install zabbix* -y
已安装:
zabbix-agent.x86_64 0:5.0.40-1.el7 zabbix-apache-conf-scl.noarch 0:5.0.40-1.el7 zabbix-get.x86_64 0:5.0.40-1.el7 zabbix-release.noarch 0:5.0-1.el7 zabbix-server-mysql.x86_64 0:5.0.40-1.el7
zabbix-web-deps-scl.noarch 0:5.0.40-1.el7 zabbix-web-mysql-scl.noarch 0:5.0.40-1.el7
完毕! 通过yum获取rpm包缓存
建议操作
准备一个最小化安装的系统,yum会自动判断,它需要什么基础依赖
因为最小化,系统缺少很多依赖包
再使用
yum install --downloadonly --downloaddir=/0224_software/ nginx这个命令去尝试,看看下载多少依赖vim,只找到了2个依赖
最小化机器进行操作,5个依赖
yum是针对当前机器的环境,判断,安装vim,需要多少个rpm依赖包
查询所需依赖包
rpm -qR [软件名]
1.使用yumdownloader工具(前提是,配置好yum仓库源)
yum install yum-utils
2.仅仅下载mysql的软件rpm包
# --destdir 也是指定一个rpm包存放的路径
[root@client-242 yum.repos.d]# yumdownloader --destdir=/opt/mysql mysql
3.以及学过了的是
# --downloadonly 默认是把rpm包,放到/var/cache/yum/
yum install --downloadonly --downloaddir=/opt/my_rpm/ nginx还有一个办法,修改yum配置文件,前提是你有一个可用的yum源仓库
1.需求是安装nginx,且获取nginx的rpm包,缓存下来(存在于epel仓库)
修改epel.repo文件,添加如下参数
keepcache=1
yum install nginx
2.此时nginx相关的rpm包都在缓存目录下了
[root@167 yum.repos.d]#
[root@167 yum.repos.d]# find /var/cache/yum/ -name *.rpm
/var/cache/yum/x86_64/7/epel/packages/nginx-1.20.1-9.el7.x86_64.rpm修改yum仓库的优先级
1.你的机器,又有本地光盘仓库--------版本1.4
2.有有阿里云的仓库---------版本2.5
3.===============省事点,不要的仓库,移走就行了=============
只需要在对应的repo仓库文件中,针对仓库的区域设置,添加一个参数即可
priority=1如何检查rpm软件依赖
上面两种要求该软件,在机器上以及安装了
1.针对以安装的rpm程序(以及在你机器上装好来的,rpm软件)
[root@client-242 yum.repos.d]# rpm -qR vim-enhanced
2.安装工具 rpmreaper
sudo yum install rpmreaper -y
rpmreaper会向用户显示已安装包的列表,显示他们的依赖关系
(不要求安装,直接去yum源仓库中,检索他们的依赖关系)
3.使用repoquery工具来罗列包的依赖关系,软件名字得正确,先yum list看看
# 安装如下工具包,即可使用
yum install yum-utils
# 前提是你的yum仓库中有这个软件包。且名字不能错
[root@client-242 yum.repos.d]# repoquery --requires --resolve nginx最后安装MySQL-5.6.43
1.获取软件的rpm包 ,也要想办法,找到mysql-5.6.43这个rpm包,用rpm装,还是yum装
2. mysql-5.6.43.tar.gz 编译安装
3.配置yum仓库
- 本地光盘
- 阿里云yum源
- 自建yum仓库文件夹
4.去mysql官网,寻找该软件的下载地址,设置为yum仓库即可实践过程
你们上述,安装过mysql,可能会和这个有冲突
你可能需要执行如下的命令,清理阿里云安装的mysql环境
注意,本操作,和其他题目无关,不要随便删东西,删东西,请看好,你在做什么
yum remove mysql* -y
yum remove mysql-* -y
yum remove mariadb* -y1.去mysql官网,找到mysql的rpm包下载地址
https://repo.mysql.com//mysql80-community-release-el7-5.noarch.rpm
通过分析其url,找到了mysql-5.6版本的rpm包,集合地儿
https://repo.mysql.com/yum/mysql-5.6-community/el/7/x86_64/
2.创建mysql的yum配置文件即可
[root@167 yum.repos.d]# cat mysql5643.repo
[mysql56]
name='This is mysql 5.6.43 server rpm'
baseurl='https://repo.mysql.com/yum/mysql-5.6-community/el/7/x86_64/'
enable=1
gpgcheck=0
3.安装对应版本软件即可
[root@167 yum.repos.d]# yum install mysql-community-server-5.6.43
#果出现依赖报错,需要你分析报错,解决对应的依赖关系
4.安装完毕后,启动mysql-5.6.43即可
#到如下脚本,即可用systemctl去管理启动了
[root@167 yum.repos.d]# ls /usr/lib/systemd/system/mysqld.service
/usr/lib/systemd/system/mysqld.service
[root@167 yum.repos.d]# systemctl start mysqld
5.启动mysql
[root@167 yum.repos.d]# systemctl start mysqld
[root@167 yum.repos.d]# netstat -tunlp|grep mysql
[root@167 yum.repos.d]# ps -ef|grep mysql
6.能执行基本的sql语句
[root@167 yum.repos.d]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.6.43 MySQL Community Server (GPL)
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
+--------------------+
3 rows in set (0.00 sec)
mysql> exit;
Bye各种排错
Linux切换用户报错
admin is not in the sudoers file. This incident will be reported
原因
没有将admin账号加入用户组,使用sudo命令的时候,出现这个情况
解决办法
1.切换到root用户下
su
接着输入root用户的密码
2.添加sudo文件的写权限,命令是:
chmod u+w /etc/sudoers
3.编辑sudoers文件
vi /etc/sudoers
找到这行 root ALL=(ALL) ALL,在他下面添加xxx ALL=(ALL) ALL (这里的xxx是你的用户名)
#admin ALL=(ALL) ALLyum报错
Loaded plugins: fastestmirror
尝试修复
使用 yum 出现 Loaded plugins: fastestmirror
意思为:插件不可用
解决办法
修改fastestmirror配置文件
[root@root ~]# vim /etc/yum/pluginconf.d/fastestmirror.conf将 enable=1 改为 enable=0
[main]
enabled=0
verbose=0
always_print_best_host = true
socket_timeout=3
# Relative paths are relative to the cachedir (and so works for users as well
# as root).
hostfilepath=timedhosts.txt
maxhostfileage=10
maxthreads=15
#exclude=.gov, facebook
#include_only=.nl,.de,.uk,.ie修改yum配置文件
[root@root ~]# vim /etc/yum.conf将plugins=1改为plugins=0
[main]
cachedir=/var/cache/yum/$basearch/$releasever
keepcache=0
debuglevel=2
logfile=/var/log/yum.log
exactarch=1
obsoletes=1
gpgcheck=1
plugins=0
installonly_limit=5
bugtracker_url=http://bugs.centos.org/set_project.php?project_id=23&ref=http://bugs.centos.org/bug_report_page.php?category=yum
distroverpkg=centos-release清除缓存并重新构建yum源
[root@root ~]# yum clean all
[root@root ~]# yum clean dbcache
[root@root ~]# yum makecache但执行完yum makecache出现以下报错↓
Could not retrieve mirrorlist
Could not retrieve mirrorlist http://mirrorlist.centos.org/?release=7&arch=x86_64&repo=os&infra=stock error was
14: curl#6 - "Could not resolve host: mirrorlist.centos.org; Unknown error"尝试修复
检测是否能ping通外网
如果没有修改DNS
找到/etc/sysconfig/network-scripts/ifcfg-ens33
注意一下,ifcfg-ens33后面的数字是随机产生的[root@root ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
***************************内容省略****************************
DEVICE="ens33"
ONBOOT="yes"将onboot改为yes,重新启动网络,service network restart,然后ping www.baidu.com如果通了的话,就证明链接成功。这样就可以正常yum update了
如果不行检查有没有配置/etc/resolv.conf
[root@root ~]#/etc/resolv.conf
# Generated by NetworkManager
search localdomain
nameserver 10.0.0.2 #主
nameserver 223.5.5.5 #备到这里如果还是不行可能是yum源的问题,修改yum源
备份yum源
[root@root ~]# mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup查看本机linux版本
cat /etc/redhat-release下载新yum源——阿里源
CentOS-Base.repo 到/etc/yum.repos.d/
进入yum的repo目录
cd /etc/yum.repos.d/修改所有CentOS文件内容
sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-*
sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-*下载并更新最新的yum源为阿里云镜像
yum install wget
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-vault-8.5.2111.repo
yum clean all
yum makecache测试是否成功
安装tree命令
[root@root ~]# sudo yum install -y tree
Resolving Dependencies
--> Running transaction check
---> Package tree.x86_64 0:1.7.0-15.el8 will be installed
--> Finished Dependency Resolution
***********************内容省略****************************
Installed:
tree.x86_64 0:1.7.0-15.el8
Complete!
'大功告成'常见报错_NTP同步常见报错之no server suitable for synchrnization found
概述
在成功配置好NTP服务端后,在NTP客户端执行ntpdate命令更新NTP客户端的时间时,如果报以下错误: no server suitable for synchronization found,可采用以下步骤检查。
[root@root yum.repos.d]# ntpdate 192.168.31.125
19 Aug 19:53:46 ntpdate[10916]: no server suitable for synchronization found解决步骤
1、在NTP服务端执行以下命令检测NTP服务是否运行
[root@root yum.repos.d]# systemctl status ntpd
● ntpd.service - Network Time Service
Loaded: loaded (/usr/lib/systemd/system/ntpd.service; disabled; vendor preset: disabled)
Active: inactive (dead)
[root@root yum.repos.d]# systemctl start ntpd
[root@root yum.repos.d]# systemctl status ntpd
● ntpd.service - Network Time Service
Loaded: loaded (/usr/lib/systemd/system/ntpd.service; disabled; vendor preset: disabled)
Active: active (running) since 四 2018-11-08 10:01:43 CST; 1s ago
Process: 10406 ExecStart=/usr/sbin/ntpd -u ntp:ntp $OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 10409 (ntpd)
Tasks: 1
CGroup: /system.slice/ntpd.service
└─10409 /usr/sbin/ntpd -u ntp:ntp -g
11月 08 10:01:43 root ntpd[10409]: Listen normally on 2 lo 127.0.0.1 UDP 123
11月 08 10:01:43 root ntpd[10409]: Listen normally on 3 ens33 192.168.31.150 UDP 123
11月 08 10:01:43 root ntpd[10409]: Listen normally on 4 virbr0 192.168.122.1 UDP 123
11月 08 10:01:43 root ntpd[10409]: Listen normally on 5 lo ::1 UDP 123
11月 08 10:01:43 root ntpd[10409]: Listen normally on 6 ens33 fe80::1b53:5dd3:4a3e:e6c5...123
11月 08 10:01:43 root ntpd[10409]: Listening on routing socket on fd #23 for interface ...tes
11月 08 10:01:43 root systemd[1]: Started Network Time Service.
11月 08 10:01:43 root ntpd[10409]: 0.0.0.0 c016 06 restart
11月 08 10:01:43 root ntpd[10409]: 0.0.0.0 c012 02 freq_set kernel 0.000 PPM
11月 08 10:01:43 root ntpd[10409]: 0.0.0.0 c011 01 freq_not_set
Hint: Some lines were ellipsized, use -l to show in full.2、运行ping命令检测NTP客户端与NTP服务端是否连通
[root@root yum.repos.d]# ping 192.168.31.125
PING 192.168.31.125 (192.168.31.125) 56(84) bytes of data.
64 bytes from 192.168.31.125: icmp_seq=1 ttl=64 time=0.350 ms
64 bytes from 192.168.31.125: icmp_seq=2 ttl=64 time=0.193 ms3、在NTP客户端执行 ntpdate -d NTP服务端IP: 输出结果如下:
[root@root yum.repos.d]# ntpdate -d
19 Aug 19:58:55 ntpdate[11220]: ntpdate 4.2.6p5@1.2349-o Tue Jun 23 15:38:19 UTC 2020 (1)
19 Aug 19:58:55 ntpdate[11220]: no servers can be used, exiting4、检查NTP服务端使用的ntp版本
[root@root yum.repos.d]# ntpq -c version
ntpq 4.2.6p5@1.2349-o Tue Jun 23 15:38:21 UTC 2020 (1)如果输出版本是ntp4.2(包括4.2)之后的版本,检测是否在restrict的定义中使用了notrust。如果有则删除notrust,再进行NTP时间同步。
5、检查NTP服务端的防火墙是否开放NTP服务端口:udp 123
为了检查NTP服务端的防火墙是否已经打开了NTP端口(UDP 123),你可以使用以下命令来检查防火墙规则。以下示例适用于Linux系统,其他系统的命令可能会有所不同。
对于使用iptables的系统:
sudo iptables -L -n | grep 123
对于使用firewalld的系统:
sudo firewall-cmd --list-ports | grep 123
如果上述命令没有输出任何信息,表示当前防火墙规则中没有针对UDP端口123的开放设置。你需要添加相应的规则来允许NTP流量通过。
对于iptables,添加规则的示例:
sudo iptables -I INPUT -p udp --dport 123 -j ACCEPT
[root@root ~]# sudo iptables -L -n | grep 123
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:123
对于firewalld,添加规则的示例:
sudo firewall-cmd --permanent --add-port=123/udp
sudo firewall-cmd --reload
[root@root ~]# sudo firewall-cmd --list-ports | grep 123
123/udp
请确保你有足够的权限执行这些操作,并在修改防火墙规则后测试NTP服务是否能正常工作。5.1、或者直接关闭防火墙
[root@root ~]# systemctl stop firewalld注意:在NTP Server重新启动NTP服务后,NTP Server自身或与其他NTPServer的同步大概需要5分钟左右,因此NTP客户端在这个时间段运行ntpdate命令时会产生no server suitable for synchronization found错误。
6、测试是否成功
[root@node1 ~]# ntpdate -u 192.168.31.125
19 Aug 20:49:32 ntpdate[15028]: adjust time server 192.168.31.125 offset -0.006382 sec
[root@node1 ~]# timedatectl
Local time: 一 2024-08-19 20:50:35 CST
Universal time: 一 2024-08-19 12:50:35 UTC
RTC time: 一 2024-08-19 12:50:34
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: no
NTP synchronized: yes
RTC in local TZ: no
DST active: n/a

